
APSheduler定时任务的使用和案例
前言
简化工作流程实现 办公自动化, 需要使用定时任务:
- 定时发送邮箱
- 定时发送微信或者检测垃圾邮箱
虽然在 python 中常用实现定时任务的包含以下四种方法:
while True: + sleepthreading.Timer定时器- 调度模块
schedule - 任务框架
APScheduler
但是在实际测试中,可以发现:
- 循环+
sleep方式可以用来做简单测试. timer可以实现异步定时任务.schedule可以实现定点定时执行,但是任然需要while True配合,而且占用内存大.APScheduler框架更加强大, 可以直接在里面添加定点与定时任务,无可挑剔。
APScheduler简介
APSchedule 全称 Advanced Python Scheduler,作用为在指定的时间规则执行指定的任务,其实基于 Quartz 的一个 Python 定时任务框架,实现了 Quartz 的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及 crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个 python 定时任务系统。
APScheduler安装
pip install apscheduler
APScheduler组成部分
- 触发器(
trigger): 包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己的初始配置以外,触发器是完全是无状态的。 - 作业存储(
job store): 存储被调度的作业,默认的作业存储是简单地把作业保存到内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据将在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。 - 执行器(
executor): 处理作业的运行,他们通常通过在作业中提交指定的可调用对象到一个线程或者进程池来进行。当作业完成时,执行器会通知调度器。 - 调度器(
scheduler): 其他的组成部门。通常在应用中只有一个调度器,应用的开发这通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如、修改和移除作业。
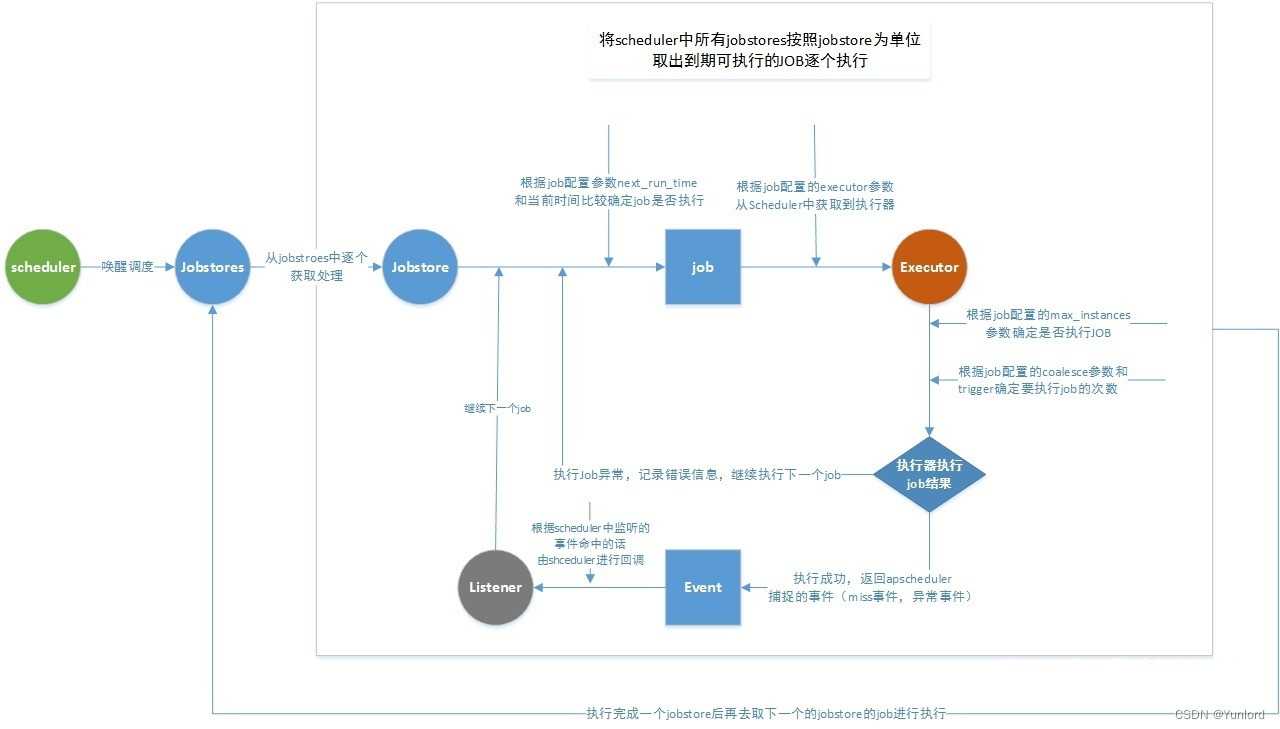
触发器( trigger)
包含调度逻辑,每一个作业都有它自己的触发器,用于决定接下来哪一个作业会运行。除了它们自己初始配置以外,触发器完全时无状态的。
APScheduler 有三种内建的 trigger:
data: 特定的时间点触发interval: 固定时间间隔触发cron: 在特定时间周期性地触发
总结: 触发器就是根据你指定的触发方式,比如时按照时间间隔,还是按照 corn 触发, 触发条件是什么等。每个任务都有自己的触发器。
interval触发器
固定时间间隔触发。 interval间隔参数,参数如下:
weeks(int): 间隔几周days(int): 间隔几天hours(int): 间隔几小时minutes: 间隔几分钟seconds: 间隔几秒start_date(datetime or str): 开始日期end_date(datetime or str): 结束日期timezone(datetime.tzinfo or str): 时区
示例代码
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def get_time():
print(datetime.datetime.now())
scheduler = BlockingScheduler()
scheduler.add_job(get_time,'interval',seconds=3,start_date='2023-2-27 1:03:33',end_date='2023-2-27 1:05:33')
scheduler.start()
date 触发器
date 是最基本的一种调度,作业任务指挥执行一次。 它表示特地给的时间点触发。它的参数如下:
run_date(datetime or str): 任务运行的日期或者时间timezone(datetime.tzinfo or str): 指定时区
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def get_time():
print(datetime.datetime.now())
scheduler = BlockingScheduler()
scheduler.add_job(get_time,'interval',seconds=3,run_date='2023-2-27 1:03:33')
scheduler.start()
cron触发器
在特定时间周期性地触发, 和 Linux crontab格式兼容,它是功能最强大的触发器.
参数:
year(int or str): 年,4位数字month(int or str): 月day(int or str): 日week(int or str): 周day_of_week(int or str):周内第几天或者星期几hour(int or str): 时minute(int or str): 分second(int or str): 秒start_date(datetime or str): 最早开始日期end_date(datetime or str): 最晚结束日期timezone(datetime.tzinfo or str): 指定时区
表达式:
表达式,参数类型,描述
*: 所有;通配符。例如:minutes=*即每分钟触发*/a: 所有;可被a整除的通配符a-b: 所有;范围a-b触发a-b/c: 所有;范围a-b,且可被c整除时触发xth y: 日;第几个星期即触发,x为第几个,y为星期几last x: 日;一个月中,最后的星期几触发last: 日; 一个月最后一天触发x,y,z: 所有;组合表达式,可以组合确定值或上方的表达式
代码演示:
from apscheduler.schedulers.blocking import BlockingScheduler
import datetime
def get_time():
print(datetime.datetime.now())
scheduler = BlockingScheduler()
scheduler.add_job(get_time,'cron',month='1-3,7-9',day_of_week='1-3')
scheduler.start()
执行器(executor)
Executor 在 scheduler中初始化,另外也可以通过 scheduler 的 add_executor 动态添加 Executor
每个 executor 都会绑定一个 alias,这个作为唯一标识绑定到 Job, 在实际执行时会根据 Job 绑定的 executor。找到实际的执行器对象,然后根据执行器对象执行 Job.
Executor 的选择需要根据实际的 scheduler来选择不同的执行器
处理作业的运行,它们通常在作业中提交指定的可调用对象到一个线程或者进程池来进行。当作业完成时,执行器将会通知调度器。
调度器(scheduler)
Scheduler 是 APScheduler的核心,所有相关组件通过其定义。 scheduler 启动之后,将开始按照配置的任务进行调度。除了依据所有定义 Job 的 trigger 生成的将要调度时间唤醒调度之外。当发生 Job信息变更时也会触发调度.
scheduler 可根据自身的需求选择不同的组件,如果是使用 AsynclIO,则选择 AsynclOScheduler,使用 tornado则选择 TornadoScheduler.
任务调度器是属于整个调度的总指挥官。它会合理的安排作业存储器、执行器、触发器进行工作,并进行添加和删除任务等。调度器通常是只有一个的。开发人员很少直接操作触发器、存储器、执行器等。因为这些都由调度器自动来实现了。
示例代码
add_job的参数
id: 指定作业的唯一IDname: 指定作业的名字trigger:apscheduler定义的触发器,用于确定Job的执行时间,根据设置的trigger规则, 计算得到下次执行此job的时间,满足时将会执行executor:apscheduler定义的执行器,Job创建任务时设置执行器的名字,根据字符串你名字到scheduler获取到执行此job的执行器,执行job指定的函数max_instances: 执行此job的最大实例数,executor执行job时,根据job的id来计算执行次数,根据设置的最大实例数来确定是否可执行。next_run_time:Job下次的执行时间,创建Job时可以指定一个时间 [datatime] ,不指定的化则默认根据trigger获取触发时间.misfire_grace_time:Job的延迟执行时间, 例如Job的计划执行时间是21:00:00, 但因服务重启或其他原因导致21:00:33才执行,如果设置此key为40,则该job会继续执行,否则将会丢弃此job.coalesce:Job是否合并执行,是一个bool值。 例如scheduler停止20s后重新启动,而job的触发器设置为5s执行一次,因此此job错过了4个执行时间,如果设置为是,则会合并到一次执行,否则会逐个执行。func:Job执行的函数args:Job执行函数需要的位置参数kwargs:Job执行函数需要的关键字参数
常见的两种调度器
APScheduler 中有很多不同类型的调度器,BlockingScheduler 和 BackgroundScheduler 是其中最常用的两种调度器。它们两个的主要区别在于 BlockingScheduler会阻塞主线程的运行,而 BackgroundScheduler不会阻塞。所以,在不同的情况下,选择不同的调度器:
BlockingScheduler: 调用start函数后会阻塞当前线程。当调度器是你应用中唯一要运行的东西时使用.BackgroundSchduler: 调用start后主线程不会阻塞。当你不运行任何其它任何框架时使用,并希望调度器在你应用的后台执行。
示例代码
import time
from pytz import utc # 获取utc时间
from apscheduler.schedulers.blocking import BlockingScheduler # 阻塞主进程执行任务
from apscheduler.schedulers.background import BackgroundScheduler # 后台实行,不阻塞
from apscheduler.executors.pool import (
ProcessPoolExecutor, # 进程调度器
ThreadPoolExecutor) # 线程调度器
def workertask():
print('hello apscheduler')
if __name__ == '__main__':
# 调度器,确认以多进程或多线程执行
executors = {
'default': ProcessPoolExecutor(24)
}
"""
max_instances: 可配置调度器的参数,最多允许 `workertask` 的任务数
"""
scheduler = BackgroundScheduler(executors=executors,timezone=utc)
scheduler.add_job(workertask,'interval',id='workder_job',seconds=3,max_instances=3)
scheduler.start()
res = scheduler.get_job('workder_job') # 获取当前 调度器的队列
print(res)
也可以通过 scheduled_job()装饰器实现:
import time
from apscheduler.schedulers.blocking import BlockingScheduler
sched = BlockingScheduler()
@sched.scheduled_job('interval', id='my_job_id', minutes=20)
def job_function():
print("Hello World")
print(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()))
sched.start()
任务存储器(job_stores)
其他
删除任务
- 通过调度器对象调用
remove_job(),参数为id或任务别名 - 通过
job调用remove(), 从获得的Job实例add_job()
# 方式1
job = scheduler.add_job(workertask,'interval', minutes=2)
job.remove()
# 方式2
scheduler.add_job(workertask,'intervak',minuter=2,id='worker_id')
scheduler.remove_job('worker_id')
重新执行任务
resume()
项目案例代码
import asyncio
from typing import List, Optional
import logging
import re
from multiprocessing import freeze_support
import asyncio
import typer
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.executors.pool import ProcessPoolExecutor
from apscheduler.events import (
JobExecutionEvent,
EVENT_JOB_EXECUTED,
EVENT_JOB_ERROR,
EVENT_JOB_MISSED,
EVENT_JOB_REMOVED,
)
from datacell import DataCell
from reactive import Reactive
import schemas
from cells import *
from config import settings
from utils.commons import reactive_data_to_worker_task, int_range_str_to_int_list
from utils.coro import coro
from utils.fansy_api import fansy_api
from utils.logging import Log
app = typer.Typer()
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)-8s %(message)s",
)
FANSY_API_HEADERS = {"Authorization": "Bearer " + settings.FANSY_API_TOKEN}
def main(
account_ids_range: Optional[str] = typer.Argument(None),
channel_type: Optional[schemas.ChannelType] = None,
free_man: bool = True,
concurrency: int = 1,
auto_fetch_free_accounts: bool = False,
):
"""
To run account ids of 1, 2, 3, simple run command `python main.py 1-3`.
To auto fetch free accounts from backend, specify `--auto-fetch-free-accounts`.
"""
loop = asyncio.get_event_loop()
scheduler = set_up_scheduler(concurrency=concurrency)
channel_type = parse_or_prompt_channel_type(channel_type)
if auto_fetch_free_accounts is False:
all_acc_ids = parse_or_prompt_account_ids(account_ids_range)
for acc_id in all_acc_ids:
asyncio.ensure_future(run_worker(acc_id, channel_type, scheduler, True))
if free_man:
asyncio.ensure_future(
run_free_man_worker(
channel_type,
scheduler,
auto_fetch_free_accounts,
account_ids_range,
)
)
scheduler.start()
loop.run_until_complete(asyncio.Future()) # Run forever.
async def run_worker(
acc_id: int,
channel_type: Optional[schemas.ChannelType],
scheduler: BackgroundScheduler,
force: bool = False,
account: Optional[schemas.Account] = None,
) -> None:
"""
Start running a worker given an account id.
If the account is already running, default to skip it. Set `force` to True to run anyway.
If the account does not match `channel_type`, the account will be skipped.
"""
# Fetch account by acc_id if not given.
if account is None:
r = await fansy_api.aget_one_free_acc(id=acc_id, channel_type=channel_type)
if r.status_code != 200:
if (
force is True
and r is not None
and r.status_code == 400
and r.json()["detail"]["status"] == 1
):
Log.w(f"RESET ACCOUNT #{acc_id}, but may cause duplicated worker!!!")
await fansy_api.aupdate_acc_status(acc_id, 0, 1)
r = await fansy_api.aget_one_free_acc(id=acc_id)
if r.status_code != 200:
return
else:
Log.e(
f"SKIP ACCOUNT #{acc_id}. {r.json() if r is not None else 'UNKNOWN'}."
)
return
account = schemas.Account(**r.json())
client = await get_reactive_client(acc_id)
await resume_and_listen_to_worker_tasks(scheduler, client, account)
async def get_reactive_client(
account_id: int, account_status_hook: bool = True
) -> Reactive:
assert settings.REACTIVE_URL, f"Env REACTIVE_URL is required."
r = await fansy_api.aaccount_access_token(account_id)
account_token = r.json()["access_token"]
client = Reactive(
settings.REACTIVE_URL + f"?token={account_token}", log_level=logging.DEBUG
)
if account_status_hook:
asyncio.ensure_future(subscribe_account_status_hook(client))
asyncio.ensure_future(client.run())
return client
async def subscribe_account_status_hook(client: Reactive):
async for data in client.get("/account-status-hook"):
pass
async def run_free_man_worker(
channel_type: schemas.ChannelType,
scheduler: BackgroundScheduler,
auto_fetch_free_accounts: bool,
account_ids_range: Optional[str] = None,
):
"""
Start running a FREE_MAN_* worker, which is similar to a normal worker, besides it:
1. Listens to `account` for INSERT, so it can run newly created accounts as normal workers in real time.
2. Skip when there is already another free man with same `channel_type` running.
Other processes may take away free man ownership and current process will stop listening to free man topics
and stop fetch more free accounts if it is still fetching.
"""
async def fetch_free_accounts(account_ids_range: Optional[str] = None):
while True:
r = await fansy_api.aget_one_free_acc(
channel_type=channel_type, account_ids_range=account_ids_range
)
if r.status_code == 404:
Log.w(f"Pause fetching free accounts for 10s due to: {r.text}")
await asyncio.sleep(10)
continue
elif r.status_code != 200:
Log.e(f"Failed to get one free account due to {r.text}. Keep trying...")
await asyncio.sleep(3)
continue
account = schemas.Account(**r.json())
Log.i(f"Running fetched account #{account.id}.")
asyncio.ensure_future(
run_worker(account.id, channel_type, scheduler, True, account)
)
await asyncio.sleep(0.01) # Give backend a break.
r = await fansy_api.aget_one_free_acc(
id=None, channel_type=schemas.ChannelType(f"FREE_MAN_{channel_type}")
)
if r.status_code != 200:
# Force to start this free man in the current process
r = await fansy_api.aget_random_accounts(
channel_query=f"FREE_MAN_{channel_type}"
)
if r.status_code != 200:
Log.e(f"Failed to taking away FREE_MAN_{channel_type} due to {r.text}")
return
free_man_acc_id = r.json()[0]["id"]
Log.w(f"Taking away FREE_MAN_{channel_type} ownership")
await fansy_api.aupdate_acc_status(free_man_acc_id, 0, 1)
r = await fansy_api.aget_one_free_acc(id=free_man_acc_id)
if r.status_code != 200:
Log.e(f"Failed to taking away FREE_MAN_{channel_type} due to {r.text}")
return
# Make sure the other process has acknowledged, as well as current process.
await asyncio.sleep(60)
acc = schemas.Account(**r.json())
if auto_fetch_free_accounts:
validate_account_ids_range(account_ids_range)
fetch_free_accounts_task = asyncio.ensure_future(
fetch_free_accounts(account_ids_range)
)
else:
fetch_free_accounts_task = None
client = await get_reactive_client(
acc.id,
account_status_hook=False, # We do not auto reset free man's status.
)
asyncio.ensure_future(resume_and_listen_to_worker_tasks(scheduler, client, acc))
# Listen to free man ownership change.
# Use infinite loop here to make sure this never stop on socket errors.
free_man_released = False
while free_man_released is not True:
async for data in client.get(
"/account-update-by-channel-type",
params={"channel_type": f"FREE_MAN_{channel_type}"},
):
if data["status"] == 0:
# Only stop account fetch if account range is not given.
# If it is given, we assume it's the user's responsibility to make sure
# same account won't be run twice.
if not account_ids_range:
if fetch_free_accounts_task:
fetch_free_accounts_task.cancel()
Log.w(f"Current process released FREE_MAN_{channel_type}!")
free_man_released = True
break
async def resume_and_listen_to_worker_tasks(
scheduler: BackgroundScheduler,
client: Reactive,
acc: schemas.Account,
):
async def resume_tasks():
"""
Resume existing worker tasks if any.
If there are no existing tasks, trigger task creation.
"""
r = await fansy_api.aget_existing_tasks(account_id=acc.id)
if r.status_code != 200:
Log.e(f"Failed to get existing tasks caused by {r.text}", acc.id)
if len(r.json()) == 0:
Log.i("No tasks from backend. Waiting for new tasks.", acc.id)
else:
for e in r.json():
add_or_update_job(
scheduler, acc.id, worker_task=schemas.WorkerTask(**e)
)
await resume_tasks()
async for data in client.get(
"/worker-tasks-by-account-id", params={"account_id": acc.id}
):
add_or_update_job(scheduler, acc.id, reactive_data=data)
def add_or_update_job(
scheduler: BackgroundScheduler,
acc_id: int,
worker_task: Optional[schemas.WorkerTask] = None,
reactive_data: Optional[dict] = None,
):
"""
Add a job to APScheduler. If the job id exists already, the job will be "updated" by
removing it then adding a new job.
"""
if worker_task is None:
if reactive_data is None:
Log.e(f"Got a reactive_data being None!!!")
return
worker_task = reactive_data_to_worker_task(reactive_data)
Log.i(
f"Received worker task: {worker_task.task_name} ({worker_task.id}) {worker_task.status}",
acc_id,
)
if worker_task.status == schemas.WorkerTaskStatus.PENDING:
if scheduler.get_job(str(worker_task.id)) is not None:
scheduler.modify_job(
str(worker_task.id),
args=(worker_task, acc_id),
next_run_time=worker_task.scheduled_at,
)
else:
scheduler.add_job(
run_worker_task,
args=(worker_task, acc_id),
next_run_time=worker_task.scheduled_at, # type: ignore
misfire_grace_time=settings.MISFIRE_GRACE_TIME, # type: ignore
id=str(worker_task.id),
)
else:
# For all other statuses, just try removing the job.
if scheduler.get_job(str(worker_task.id)) is not None:
scheduler.remove_job(str(worker_task.id))
def worker_task_listener(scheduler: BackgroundScheduler, event: JobExecutionEvent):
"""
Executing a worker task results in one of the results: SUCCESS, FAIL, MISSED.
We determine the result directly via listening to `APScheduler.events`.
"""
try:
if event.code == EVENT_JOB_EXECUTED:
r = fansy_api.report_worker_task(
event.job_id, schemas.WorkerTaskStatus.SUCCESS
)
Log.i(f"Reported task ({event.job_id}) as SUCCESS")
elif event.code == EVENT_JOB_ERROR:
r = fansy_api.report_worker_task(
event.job_id,
schemas.WorkerTaskStatus.FAIL,
f"{event.exception}\n{event.traceback}",
)
Log.e(event.exception)
Log.e(event.traceback)
Log.i(f"Reported task ({event.job_id}) as FAIL")
elif event.code == EVENT_JOB_MISSED:
r = fansy_api.report_worker_task(
event.job_id, schemas.WorkerTaskStatus.MISSED
)
Log.i(f"Reported task ({event.job_id}) as MISSED")
# Because missed job always trigger removed event, return here
# to prevent duplicate task creations.
return
elif event.code == EVENT_JOB_REMOVED:
pass
else:
raise NotImplementedError(f"JobExecutionEvent code {event.code}")
except Exception as e:
Log.e(e, exc_info=True)
def run_worker_task(worker_task: schemas.WorkerTask, acc_id: int):
# Get the latest account info here.
r = fansy_api.get_acc(acc_id)
assert r.status_code == 200, f"Failed to get account data: {r.text}"
try:
acc = schemas.Account(**r.json())
variables = acc.dict()
# Need a little modification...
variables["acc_id"] = variables.pop("id")
variables["task_id"] = worker_task.id
variables["task_name"] = worker_task.task_name
if worker_task.task_variables is not None:
variables.update(worker_task.task_variables)
if worker_task.data is not None:
task_data = worker_task.data
else:
r = fansy_api.get_task_data(worker_task.task_name)
assert r.status_code == 200, f"Failed to get task config: {r.text}"
task_data = r.json()
DataCell.set_network_base_url(settings.FANSY_API)
DataCell.set_network_headers(FANSY_API_HEADERS)
cell = DataCell.take(task_data)
cell.inject_initial_variables(variables)
cell.execute()
except Exception as e:
raise e
async def try_run_newly_created_worker(
reactive_data: dict,
channel_type: schemas.ChannelType,
scheduler: BackgroundScheduler,
client: Reactive,
):
Log.i(f"Try run newly created account: {reactive_data}")
try:
if reactive_data["channel_type"] != channel_type:
return
await run_worker(
reactive_data["id"],
reactive_data["channel_type"],
scheduler,
)
except Exception as e:
Log.e(e, exc_info=True)
def set_up_scheduler(concurrency: int = 1) -> BackgroundScheduler:
"""Set up a BackgroundScheduler with a process pool, given a concurrency num."""
apscheduler_executors = {"default": ProcessPoolExecutor(concurrency)}
scheduler = BackgroundScheduler(executors=apscheduler_executors, timezone=utc)
scheduler.add_listener(
lambda x: worker_task_listener(scheduler, x),
EVENT_JOB_EXECUTED | EVENT_JOB_ERROR | EVENT_JOB_MISSED | EVENT_JOB_REMOVED,
)
return scheduler
def parse_or_prompt_channel_type(channel_type: Optional[str]) -> schemas.ChannelType:
if channel_type is None:
channel_type = settings.CHANNEL_TYPE
while channel_type is None:
channel_type = typer.prompt("Channel type(s)? (e.g. TWITTER)")
channel_type = schemas.ChannelType(channel_type)
return channel_type
def parse_or_prompt_account_ids(account_ids_range: Optional[str]) -> List[int]:
if account_ids_range is None:
account_ids_range = typer.prompt(
"Account ids range? (e.g. 1-3)", default="None"
)
if account_ids_range is None or account_ids_range == "None":
Log.w("No account ids are given.")
return []
all_acc_ids = int_range_str_to_int_list(account_ids_range)
return all_acc_ids
def validate_account_ids_range(account_ids_range: Optional[str]) -> None:
"""
Either be None or format like '1-3'.
"""
if (
account_ids_range is not None
and re.search("^[0-9]+-[0-9]+$", account_ids_range) is None
):
raise ValueError(f"Invalid account ids range: {account_ids_range}")
if __name__ == "__main__":
freeze_support()
typer.run(main)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?