
redis高级用法之慢查询、pipline与事务、发布订阅、bitmap位图、hyperloglog、geo、持久化、主从
高级用法之慢查询
5大数据类型,o(n),命令执行时间很长,redis命令操作,为单线程架构,会阻塞
- 单线程架构:并发操作不需要锁
- mysql:行锁,表锁,并发操作数据错乱的问题
慢查询日志,记录下来,以便后期查看,排查redis的配置,用来记录慢查询,如果符合这个配置,这条命令就会被记录
命令操作生命周期
- 客户端到服务端的网络时间
- 执行命令时间;我们指的慢查询指这里,设定一个时间,如果超过了这个时间,我们就认为是慢查询
- 服务端返回客户端时间
配置:两个配置项
# 查询
config get slowlog-max-len # 慢查询队列是128
config get slowly-log-slower-than # 微秒,超过这个时间,我们就记录
动态配置
config set slowlog-log-slower-than 0 # 即记录所有
config set slowlog-max-len 128
# 持久化到本地配置文件
config rewrite
# 查看慢命令队列
slowlog get [n] # 获取慢查询队列
日志由4个属性组成:
- 日志的标识id
- 发生的时间戳
- 命令耗时
- 执行的命令和参数

slowlog len # 获取慢查询队列长度
slowlog reset # 清空慢查询队列
作用
后期发现redis速度非常慢,开启慢日志,过一会,查看一下慢命令,分析这个命令是不是必须要执行,把这个慢命令换一种方式实现,从而加快操作速度。
pipline与事务
redis本身不支持事务,通过管道实现部分事务
redis的pipline(管道)功能在命令行中没有,但redis是支持pipline的,而且在各个语言版的client中都有响应的实现
- 将一批命令,批量打包,在redis服务端批量计算(执行),然后把结果批量返回
- 1次pipline(n条命令)=1次网络时间+n次命令时间
python代码实现
import redis
pool=redis.ConnectionPool(host='127.0.0.1',port=6379)
r=redis.Redis(connection_pool=pool)
# 创建pipline
pipe=r.pipeline(transaction=True)
# 开启事务
pipe.multi()
pipe.set('name1','xunfei1')
# 其他代码,可能出异常
pipe.set('role1','ss1')
pipe.execute() # 一次性执行命令,在这之前,如果处理异常,所有命令不会执行,保证了一致性
原生事务操作
mutil:开启事务,放到管道中一次性执行
# 原生redis使用管道
multi # 开启事务
set name xunfei
set age 20
exec
模拟事务
在开启事务之前,先watch,只有这个age,在整个过程中没有被改变,才能正常修改成功,如果在执行exec时发现,age被修改了,就修改失败。
watch age
multi
decr age
exec
另一台机器
multi
decr age
exec # 先执行,上面的执行就会失败(乐观锁,被watch的事务不会执行成功)
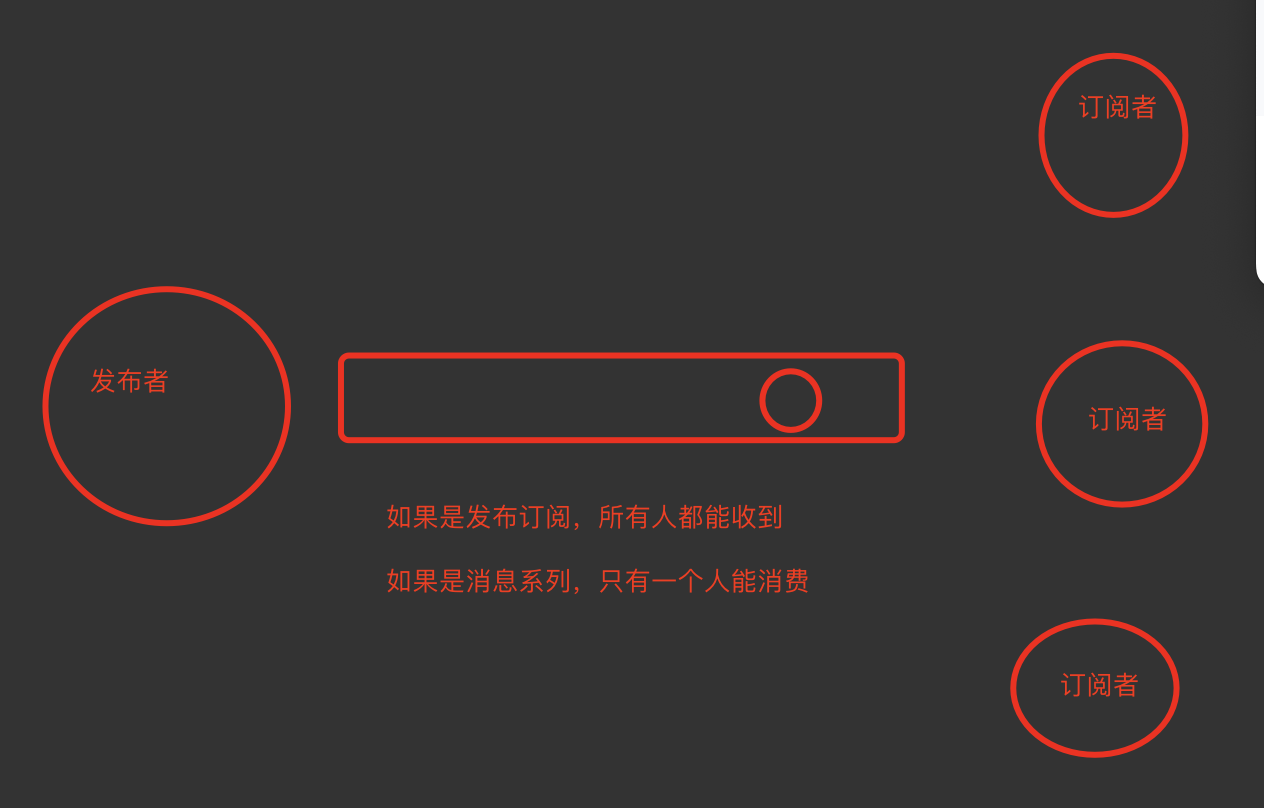
发布订阅
观察者模式:我们现在订阅了一个人,只要这个人发生变化,我们都能收到变化
发布者发布了消息,所有的订阅者都可以收到,就是生产者消费者模型(后订阅了,无法获取历史消息)
- 关注了某个明星,只要明星发布动态,大家都能收到
- 订阅了某个人的博客,只要它发布新博客,都能收到
- 订阅了某个商品的抢购提醒,当要开始抢购的时候,你收到短信通知
redis实现发布订阅
发布消息
publish souhu:tv "hello world"
订阅消息
subsribe souhu:tv
发布订阅和消息队列区别
- 只要订阅了,所有人都能收到消息
- 消息队列,只有一个人能抢到消息
bitmap位图
本质就是字符串,可以操作某个比特位
# 比如字符串是big,设置和获取某个比特位
set hello big # 放入key为hello 值为big的字符串
# 获取比特位
getbit hello 0 # 取位图的第0个位置,返回0
getbit hello 1 # 取位图的第一个位置,返回1
# 设置比特位
127.0.0.1:6379> setbit hello 7 1
(integer) 0
127.0.0.1:6379> get hello
"cig"
# 获取指定范围内1的个数,前闭后闭区间
bitcount key start end # 单位为字节,注意按字节,一个字节8个比特位
作用
做独立用户统计,日活统计,大数据量的日活统计,使用它会节约内存
日活:每日的用户活跃数,用户登录后,把id放入到集合中
1 2 3 9999 # 字符串9999四个字符 4*8 32个比特位,用户量越多,存储用户id用的空间越大
使用setbit设置,只要用户登录了,就在对应的位置设置为1,没有登录就是0
setbit users 9999 1
setbit users 1 1
最终通过bitcount计算出总共有多少个1,就是多少个活跃用户
抖音日活
集合:用户id方式 3亿用户*32比特位
位图:方式 3亿*1个比特位
setbit users 10亿 1
做日活,使用集合和位图比较
使用set和bitmap对比
1亿用户,5千万独立(1亿用户量,约5千万人访问,统计活跃用户数量)
数据类型 每个userid占用空间 需要存储用户量 全部内存量
set 32位(假设userid是整形,占32位) 5千万 32位*5千万=200MB
bitmap 1位 1亿 1位*1亿=12.5MB
假设有10万独立用户,使用位图还是占用12.5mb,使用set需要32位*1万=4MB
HyperLogLog
HyperLogLog本质还是字符串;基于HyperLogLog算法:极小的空间完成独立数量统计
- 用来统计某个值是否在其中,只能统计,不能取出来
- 集合可以取值,统计是否在其中,但是集合占的空间大
使用
pfadd key element # 向hyperloglog添加元素,可以同时添加多个
pfcount key # 计算hyperloglog的独立总数
类似于集合,去重,统计某个元素是否在其中,之前使用去重的地方,就可以使用它
独立用户统计,也可以使用HyperLogLog
127.0.0.1:6379> pfcount xunfei
(integer) 2
127.0.0.1:6379> pfadd xunfei dcd852f8-d979-4c96-8996-1e9a26eea5d7
(integer) 1
127.0.0.1:6379> pfadd xunfei 7bea605c-bfa5-4677-aa97-979b0f7dbf28
(integer) 1
127.0.0.1:6379> pfcount xunfei
(integer) 4
如果用户id不是数字,而是uuid无规律的形式
错误率
和布隆过滤器的本质是一样的,使用HyperLogLOG算法;百万级别独立用户统计,百万条数据只占15k;错误率0.81%;无法取出单条数据,只能统计个数。
GEO
GEO(地理信息定位):存储经纬度,计算两地距离,范围等
- 抖音,附近的人
- 美团,附近的美食
- 交友软件,附近的美女
存储经纬度,t通过经纬度,计算距离
- 经纬度哪里来,前端(app,网页),前端获取用户授权,用户授权后,通过某个方法,可以直接获取到手机的位置,获取出来经纬度
- 通过后台某个接口,把此时的经纬度,提交到后台,后台保存到redis的geo中
存储数据
geoadd user:locations 116.28 39.55 1 # 1 为userid
geoadd user:locations 116.25 42.55 2
geoadd cities:locations 116.28 39.55 beijing
geoadd cities:locations 117.12 39.08 tianjin
genadd cities:locations 114.29 38.02 shijiazhuang
geoadd cities:locations 118.01 39.38 tangshan
genadd cities:locations 115.29 38.51 baoding
获取地理位置信息,获取位置
127.0.0.1:6379> geopos user:locations 2
1) 1) "117.29999810457229614"
2) "42.44000107518477449"
127.0.0.1:6379> geopos cities:locations beijing
1) 1) "116.28000229597091675"
2) "39.5500007245470826"
获取两个地点的距离
127.0.0.1:6379> geodist cities:locations beijing tianjin km
"89.2061"
方圆100km内有哪些城市
改一个接口,交友类app,附近4公里的美女,每次都会把它自己叉出去,不显示自己,只查别人
georadiusbymember cities:locations beijing 150 km
geo本质就是zset类型
持久化
redis的所有数据保存在内存中,对数据的更新将异步保存到硬盘上,更新到硬盘上这个操作称之为持久化
常见的持久化方案
- 快照:某时某刻数据的一个完成备份(mysql的dump、redis的RDB)
- 写日志:任何操作记录日志,要恢复数据,只要把日志重新走一遍即可(mysql的binlog,redis的aof)
redis支持两种持久化方案
- rdb:快照,某一时刻完整备份
- aof:日志,进行了操作就记录日志
- 混合持久化:rdb+aof方案,后来加入的,为了快速恢复数据
rdb持久化方案
三种触发机制
- 手动:save
- 手动:bgsave
- 配置文件:符合条件就触发
1.手动:save
在客户端执行save,把此时内存中的数据,完整的备份到硬盘上,生成一个xx.rdb文件,当redis服务器停止,在启动,会加载rdb文件数据到内存,达到快速恢复的效果
save会阻塞住,导致其他命令执行不了
2.手动:bgsave
在客户端执行bgsave,异步备份,不会阻塞其他命令的执行
3.配置文件,用的情况比较多
配置文件中添加如下配置
save 900 100
save 300 10
save 60 5
- 如果60秒中改变了5条数据,自动生成rdb
- 如果300秒中改变了10条数据,自动生成rdb
- 如果900秒钟改变了100条数据,自动生成rdb
客户端主动关闭服务端时,也会触发持久化
127.0.0.1:6379> shutdown
rdb方案会存在数据丢失的情况,一般我们用redis做缓存,可以使用这种方案,缓存丢失,影响不大,但如果对数据准确性要求比较高,应该使用aof方案
aof方案
客户端每写入一条命令,都记录一条日志,放到日志文件中,如果出现宕机,可以将数据完全恢复
aof的三种策略
日志不是直接写到硬盘上,而是先放在缓存区,缓存区根据一些策略,写入到硬盘上
- always:redis->写命令刷新的缓存区->每条命令fsync到硬盘->aof文件
- everysec(默认值):redis->写命令刷新的缓冲区->每秒把缓冲区fsync到硬盘->aof文件
- no:redis->写命令刷新的缓冲区->操作系统决定,缓冲区fsync到硬盘->aof文件
| 命令 | always | everysec | no |
|---|---|---|---|
| 优点 | 不丢失数据 | 每秒一次fsync,丢失1秒数据 | 不用管 |
| 缺点 | io开销大,一般的sata盘只有几百tps | 丢1秒数据 | 不可控 |
aof重写
随着命令的逐步写入,并发量的变大,aof文件会越来越大,通过aof重写来解决该问题
原生AOF AOF重写
set hello world set hello hehe
set hello java set counter 2
set hello hehe rpush mylist a b c
incr counter
incr counter
rpush mylist a
rpush mylist b
rpush mylist c
过期数据
本质就是把过期的,无用的,重复的,可以优化的命令,来优化;这样可以减少磁盘占用量,加快恢复速度。
配置文件配置好,会自动开启aof重写,优化aof日志文件
auto-aof-rewrite-min-size # aof文件到达某个尺寸,就触发aof重写
auto-aof-rewrite-percentage # aof 文件增长率,到达某个比率,就触发aof重写
最佳配置
appendonly yes # 将该选项设置为yes,打开,开启aof
appendfilename appendonly.aof # 文件保存的名字
appendfsync everysec # 采用第二种策略
no-appendfsync-on-rewrite yes # 在aof重写的时候,是否要做aof的append操作,因为aof重写消耗性能,磁盘消耗,正常aof写磁盘有一定的冲突,这段期间的数据,允许丢失
你们公司采用了什么持久化方案
- 如果是缓存,就用rdb
- 如果是对数据准确性要求高,就用aof
- 混合持久化:两个都开启
主从复制
mysql的主从复制原理:binlog、relaylog、io线程、sql线程
redis主从复制出现原因
问题:机器故障、容量瓶颈、qps瓶颈
解决问题:一主一从,一主多从,做读写分离,做数据副本
扩展数据性能:
- 一个master可以有多个slave
- 一个slave只能有一个master
- 数据流是单向的,从master到slave
redis主从复制原理
- 副本库通过
slaveof 127.0.0.1 6379命令,连接主库,并发送SYNC给主库 - 主库收到
SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库 - 副本库接受到会会应用RDB快照
- 主库会陆续将中间产生的新的操作,保存并发送给副本库
- 到此,我们主复制集就正常工作了
- 再次以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库
- 所有复制相关信息,从info信息中都可以查到,即使重启任何节点,它的主从关系都还在。
- 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送
PSYNC给主库 - 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的。
1. 主从复制搭建
两台机器,启动两个redis进程
第一台机器配置
daemonize yes
port 6379
dir "/root/redis/data"
logfile "6379.log"
save 900 20
save 300 10
save 60 5
dbfilename dump.rdb
appendonly yes
appendfilename appendonly.aof
appendfsync everysec
no-appendfsync-on-rewrite yes
第二台机器配置
daemonize yes
port 6380
dir "/root/redis/data2"
logfile "6380.log"
save 900 20
save 300 10
save 60 5
dbfilename dump.rdb
appendonly yes
appendfilename appendonly.aof
appendfsync everysec
no-appendfsync-on-rewrite yes
启动两个redis-server服务
redis-server ./redis_6379.conf
redis-server ./redis_6380.conf
ps aux|grep redis-server
在6380库上执行
slaveof 127.0.0.1 6379
以后6380库就是6379的从库了,不能再写数据了
Info 命令查看主从关系
2. 配置文件搭建方式
在从库配置文件加入
replicaof 127.0.0.1 6379
masterauth xunfei123 # 密码
slave-read-only yes
在俩从库配置文件中加入
- 6379 主
- 6380 从
- 6381 从
- 停掉一个从库,主从关系还在
- 停掉一个主库,就不能写数据了
