
线程理论和实操
互斥锁
互斥锁:就是将并发变成串行,虽然牺牲了程序的执行效率,但是保证了数据安全
代码演示
from multiprocessing import Lock
mutex = Lock()
mutex.acquire() # 抢锁
mutex.release() # 释放锁
强调:互斥锁只应该出现在多个程序操作数据的地方,其他位置尽量不要加。以后我们自己处理锁的情况很少,只知道锁的功能即可
-
行锁:mysql等数据库或excel对表中一行行数据加的锁,当多个用户同时访问并修改行数据时,第二个用户及以后的用户会提交修改数据时自动被锁(阻塞),无法修改行数据,除非第一个用户提交事务,才会释放。
-
表锁:mysql等数据库或excel对整张表加的锁,当多个用户同时访问并修改表时,第二个用户及以后的用户会自动被锁,无法修改表内容,除非第一个用户提交事务。
-
客观锁:指的是在操作数据的时候非常乐观,乐观地认为别人不会同时修改数据,因此乐观锁默认是不会上锁的,只有在执行更新的时候才会去判断在此期间别人是否修改了数据,如果别人修改了数据则放弃操作,否则执行操作。
-
悲观锁:指的是在操作数据的时候比较悲观,悲观地认为别人一定会同时修改数据,因此悲观锁在操作数据时是直接把数据上锁,直到操作完成之后才会释放锁,在上锁期间其他人不能操作数据。
线程理论
线程和进程的区别
- 进程是资源单位:进程相当于是车间,负责给内部的线程提供相应的资源
- 线程是执行单位:线程相当于是车间里面的流水线,负责执行真正的功能
注意:一个进程至少含有一个线程
多线程和多进程的区别
- 多进程:需要申请内存空间,需要拷贝全部代码,资源消耗大
- 多线程:不需要申请内存空间,也不需要拷贝全部代码,资源消耗小
同一个进程下多个线程之间资源共享(进程之间默认隔离)
创建线程的两种方式
方式1:
from threading import Thread
import time
def task(name):
print(f'子线程{name}开始执行')
time.sleep(1)
print(f'子线程{name}结束执行')
t = Thread(target=task,args=('jason',))
t.start()
print('主线程')
方式2:
class MyThread(Thread):
def __init__(self,name):
super().__init__()
self.name=name
def run(self):
print(f'子线程{self.name}开始执行')
time.sleep(1)
print(f'子线程{self.name}结束执行')
f = MyThread('jason')
f.start()
print('主线程')
多线程实现TCP服务端并发
服务端:
from threading import Thread
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
def talk(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data.upper())
while True:
sock, addr = server.accept()
t= Thread(target=talk,args=(sock,))
t.start()
join方法
主线程等到子线程运行结束后在运行
from threading import Thread
import time
def task():
print('子线程开始运行')
time.sleep(2)
print('子线程结束运行')
t = Thread(target=task)
t.start()
t.join()
print('主线程')
同一个进程下线程间数据共享
from threading import Thread
money = 100
def task():
global money
money=666
t= Thread(target=task)
t.start()
t.join() # 确保线程结束后在查找money
print(money)
线程对象相关方法
进程号:同一个进程下开设的多个线程拥有相同的进程号
# 查看子线程和主线程的名字
from threading import Thread,current_thread
def task():
print(current_thread().name) # 子线程 Thread-1
t= Thread(target=task)
t.start()
print(current_thread().name) # 主线程 MainThread
# 进程下的线程数
import threading
from threading import Thread,current_thread
def task():
print(current_thread().name)
print(threading.active_count()) # 2
守护线程
守护线程伴随着被守护的线程的结束而结束
from threading import Thread
import time
def task():
print('子线程开始运行')
time.sleep(1)
print('子线程结束运行')
t = Thread(target=task)
t.daemon= True
t.start()
print('主线程')
进程下所有的非守护线程结束,主线程(主进程)才能真正结束!(回收资源)
GIL全局解释器锁
python解释器也是由编程语言写出来的
- Cpython:用C写出来的
- Jpython:用java写出来的
- Pypython:用python写出来的
最常用的就是Cpython(默认)
官方文档对GIL的解释
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
- GIL的研究是Cpython解释器的特点,不是python语言的特点
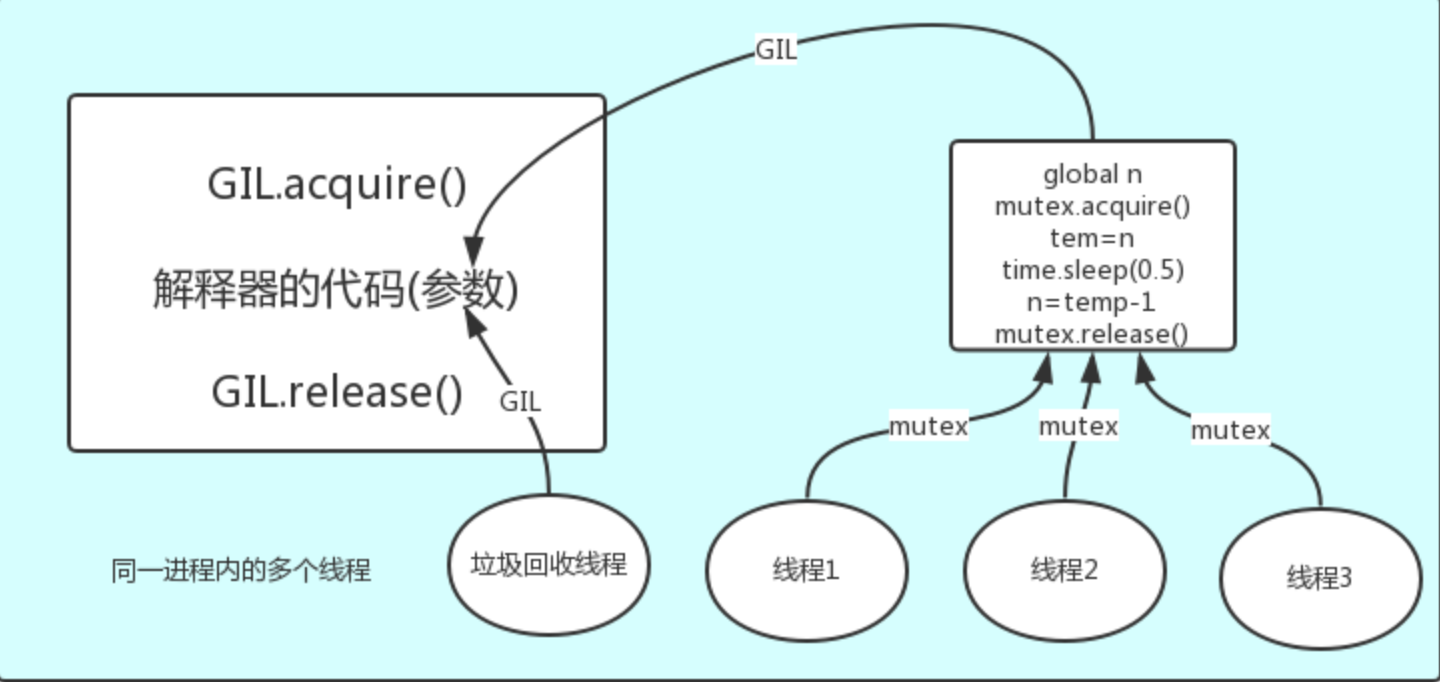
- GIL本质也是一把互斥锁
- GIL的存在使得同一个进程下的多个线程无法同时执行(关键),即:单线程下的多线程无法利用多核优势,效率低
- GIL的存在主要是因为cpython解释器中垃圾回收机制不是线程安全的
误解:
-
python的多线程就是垃圾,利用不到多核优势
python的多线程确实无法使用多核优势,但是IO密集型的任务下是有用的
-
既然有GIL,那么以后我们写代码都不需要加互斥锁
GIL只确保解释器层面的数据不会错乱(垃圾回收机制),针对程序中自己的数据应该自己加锁处理
所有的解释型编程语言都没办法做到同一个进程下多个线程同时执行
