
TCP/IP协议、Socket套接字以及黏包问题的解决方案
传输层
PORT协议
TCP协议与UDP协议
规定了数据传输所遵循的规则
数据传输能够遵循的协议有很多,TCP和UDP是较为常见的两个
TCP协议(Transmission Control Protocol) 可靠的、面向连接的协议、传输效率低全双工通信、面向字节流
应用场景:Web浏览器、电子邮件、文件传输程序。
三次握手:建立双向通道
洪水攻击:同时让大量的客户端朝服务端发送建立TCP连接的请求
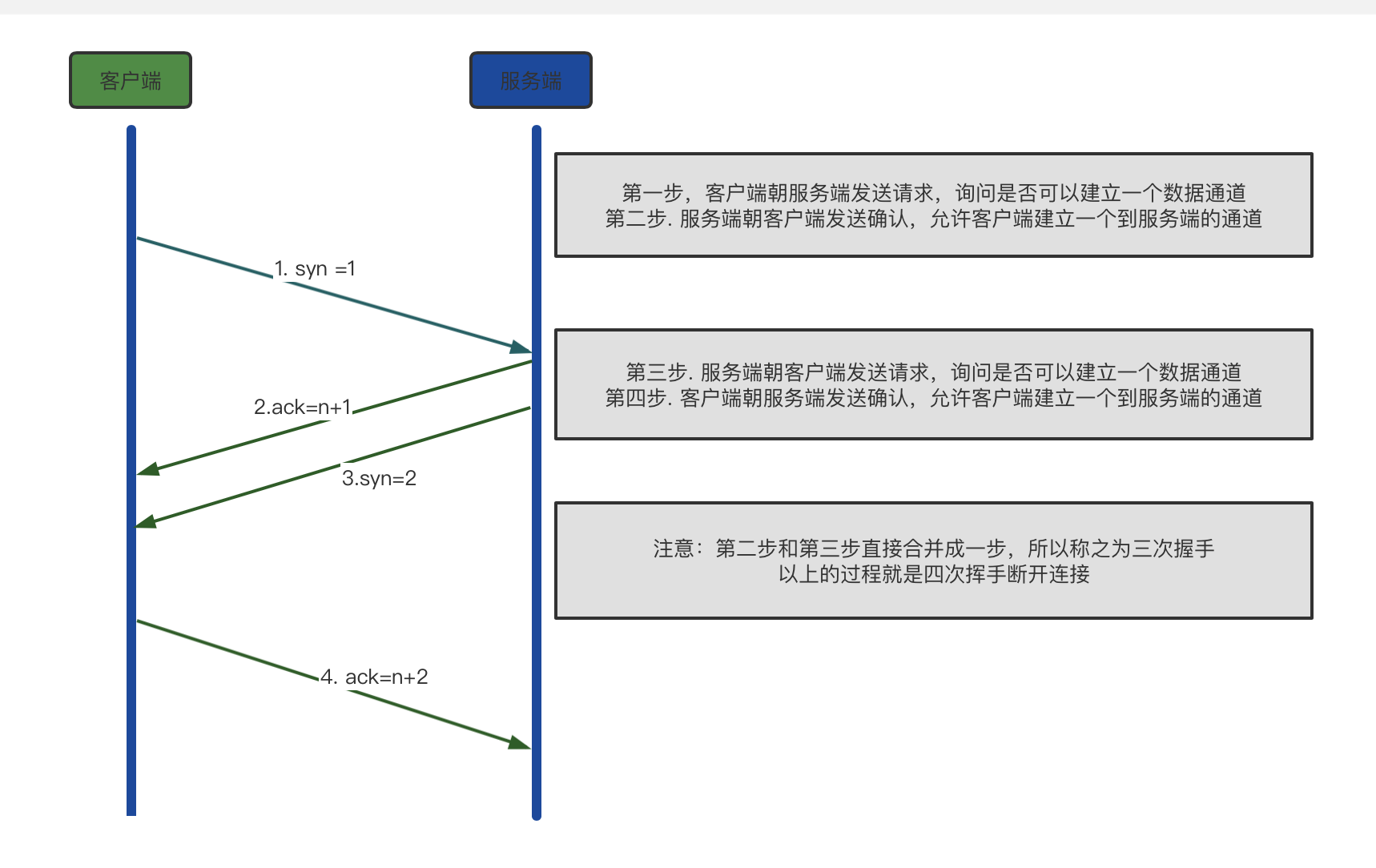
四次挥手:断开连接(中间的两步不能合并,需要有检查的时间)
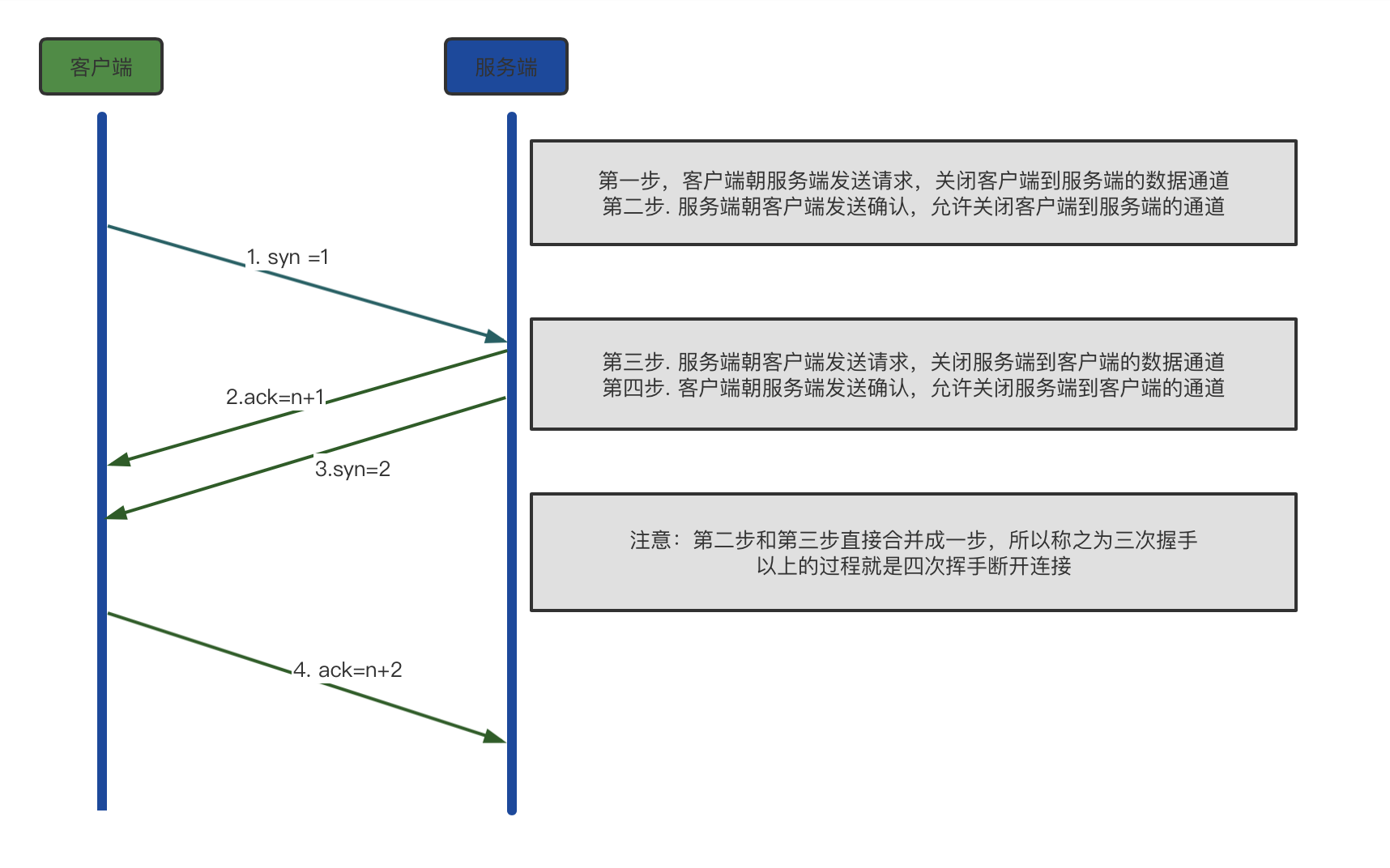
基于TCP传输数据非常的安全,因为有双向通道,数据也不容易丢失,不容易丢失的原因在于二次确认机制每次发送数据都需要返回确认消息,否则在一定时间会反复发送。
UDP协议(User Datagram Protocol): 不可靠的、无连接的服务,传输效率高(发送前时延小),一对一、一对多、多对一、多对多、面向报文,尽最大努力服务,无拥塞控制。
应用场景:域名系统(DNS)、视频流、IP语音(VoIP)
TCP和UDP的区别:
TCP类似于打电话:你一句我一句,有来有往(二次确认机制)
UDP类似于发短信:只要发送了,不管别人看没看到,也不管回不回复
应用层
主要取决于程序员自己采用什么策略和协议
常见的协议有:HTTP HTTPS FTP...
Socket套接字
1.基于文件类型的套接字家族:套接字家族的名字:AF_UNIX
2.基于网络类型的套接字家族:套接字家族的名字:AF_INET
Socket就是由第二种而来,它是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,他就是一个门面模式,它把复杂的TCP/IP协议族隐藏在socket接口后面,对用户来说,一组简单的接口就是全部让socket去组织数据,以符合执行的协议。
服务端:
import socket
# 创建一个socket对象
server = socket.socket() # 括号内什么都不写,默认就是基于网络的TCP套接字
# 绑定一个固定的地址(ip/port)
server.bind(('127.0.0.1',8080))
# 半连接池
server.listen(5)
# 等待客户端连接
sock,addr = server.accept()
print(sock,addr) # sock是双向通道,addr是客户端地址
# 数据交互
sock.send(b'helloworld') # 朝客户端发送数据
data = sock.recv(1024)
print(data)
sock.close() # 与客户端断开连接
server.close() # 关闭服务
客户端:
import socket
# 产生一个socket对象
client = socket.socket()
# 连接服务器(拼接服务端的ip和port)
client.connect(('127.0.0.1',8080))
# 数据交互
data = client.recv(1024) # 接受服务端发送的数据
print(data)
client.send(b'HELLOWORLD!') # 发送给服务端的数据
client.close()
这样的服务端和客户端只能通信一次就结束,于是我们做了如下优化:
1.消息自定义,让客户端和服务端的消息可以自定义发送
2.循环通信,给数据交互的环节添加循环
3.服务端能够持续提供服务(在server.accept()上加个死循环)
4.服务端和客户端的自定义消息都添加了限制:
-
服务端当消息发送为空就重新发送
-
客户端消息发送为空就回复给服务端:客户端暂无消息
5.服务端频繁重启可能会报端口被占用的错(mac电脑)
服务端:
import socket
from socket import SOL_SOCKET,SO_REUSEADDR
# 创建一个socket对象
server = socket.socket() # 括号内什么都不写,默认就是基于网络的TCP套接字
# 绑定一个固定的地址(ip/port)
server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server.bind(('127.0.0.1',8080))
# 半连接池
server.listen(5)
while True:
# 等待客户端连接
sock,addr = server.accept()
print(sock,addr) # sock是双向通道,addr是客户端地址
while True:
# 数据交互
msg = input('发送给客户端的消息>>>:').strip()
if not msg:
continue
sock.send(msg.encode('utf8')) # 朝客户端发送数据
data = sock.recv(1024)
print(data.decode('utf8'))
客户端
import socket
# 产生一个socket对象
client = socket.socket()
# 连接服务器(拼接服务端的ip和port)
client.connect(('127.0.0.1',8080))
while True:
# 数据交互
data = client.recv(1024) # 接受服务端发送的数据
print(data.decode('utf8'))
msg = input('发送给服务端的消息>>>:').strip()
if not msg:
msg = '客户端暂无消息!'
client.send(msg.encode('utf8')) # 发送给服务端的数据
半连接池
主要是为了做缓冲,避免太多客户端无效等待
server.listen(5) #即只能有5个客户端等待与服务端通信,超出则拒绝
黏包问题
黏包现象代码说明
服务端:
import socket
server = socket.socket()
server.bind(('127.0.0.1',8081))
server.listen(5)
sock,addr = server.accept()
sock.send(b'helloworld')
sock.send(b'hellojason')
sock.send(b'hellopython')
客户端:
import socket
client = socket.socket()
client.connect(('127.0.0.1',8081))
data1 = client.recv(1024)
print(data1)
data2 = client.recv(1024)
print(data2)
data3 = client.recv(1024)
print(data3)
'这就是黏包现象'
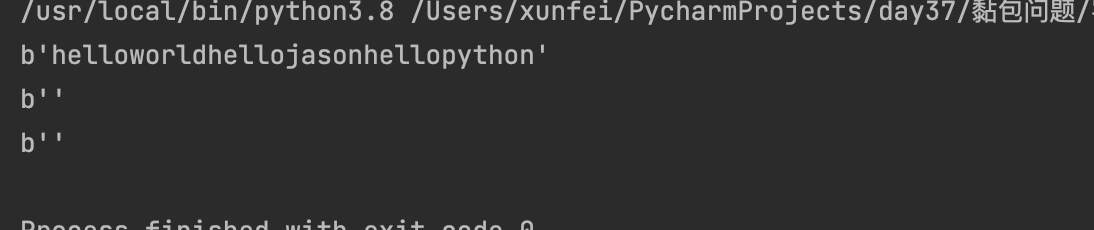
导致黏包现象的原因:
-
TCP特性
流式协议:所有的数据类似于水流,连接在一起(黏在一起发送,所以会导致一个黏包问题就如上述代码一样的问题) -
recv(server[/client].recv(字节数))
我们不知道即将要接受的数据量多大,如果知道的话,并不会产生也不会黏包
利用struct模块解决黏包问题
1.如果我们知道了所要接受的数据量的大小,那么就可以解决黏包问题,struct模块可以帮我们解决这个问题
服务端:
import socket
import struct
from socket import SOL_SOCKET,SO_REUSEADDR
server = socket.socket()
server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server.bind(('127.0.0.1',8081))
server.listen(5)
sock,addr = server.accept()
info = '人生苦短,我用python'
info = info.encode('utf8')
# 制作报头并发送
info_len = struct.pack('i',len(info))
sock.send(info_len)
# 发送真实数据
sock.send(info)
sock.send('你好世界'.encode('utf8')) # 为了验证是否可以准确的利用struct获取数据长度,在发一个数据
import socket
import struct
client = socket.socket()
client.connect(('127.0.0.1',8081))
#接受报头数据
info_len = client.recv(4)
real_info_len = struct.unpack('i',info_len)[0] # 解包后的返回值为一个元组,解包的长度为元组第一个元素
# 根据解包后的数据长度获取实际数据
info = client.recv(real_info_len).decode('utf8')
print(info)

struct模块针对数据量特别大的数字无法打包,但是足以满足我们目前日常的文件传输需求。
作业:
1.编写一个cs架构的软件
就两个功能
一个视频下载:从服务端下载视频
一个视频上传:从客户端上传视频
"""
视频的上传:(可以实现自定义上传内容)
即从客户端传输文件到服务端
客户端的代码流程为:
1.将文件的内容(文件名称,文件大小等)组织成字典形式,并将字典数据打包(struct模块的pack功能),发送报头
2.将真实的字典发送
3.将真实的数据发送
"""
# 客户端:
import socket
import os
import json
import struct
client = socket.socket()
client.connect(('127.0.0.1',8080))
base_dir = '/Users/xunfei/Desktop'
file_list = os.listdir(base_dir)
def get_file():
for i,file in enumerate(file_list,start=1):
print(i,file)
choice = input('请选择要上传的文件>>>:').strip()
choice = int(choice)
if choice not in range(1,len(file_list)+1):
print('请输入存在文件!')
return
return file_list[choice-1]
# 上传
def upload():
file_name = get_file()
if not file_name:
print('无目标文件')
return
file_path =f'{base_dir}/{file_name}'
# 写一个字典,包含文件详细信息
file_dict = {
'file_name': file_name,
'file_desc': '各种视频应有尽有',
'file_size': os.path.getsize(file_path)
}
# # 将字典数据进行打包
file_dict_bytes = json.dumps(file_dict).encode('utf8') # 将真实字典数据序列化为字符串数据,并编码
file_dict_len = struct.pack('i', len(file_dict_bytes)) # 将字典的长度打包成固定长度4
print(file_dict_bytes)
while True:
client.send(file_dict_len) # 发送固定长度的报头
client.send(file_dict_bytes) # 发送真实字典数据
with open(file_dict.get('file_name'), 'rb') as f:
for line in f:
client.send(line) # 发送真实文件数据
print('文件上传成功')
break
return
upload()
# 服务端:
import socket
import json
import struct
def receive_file():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
sock, addr = server.accept()
while True:
file_dict_len = sock.recv(4) # 接受固定长度为4的报头
real_file_dict_len = struct.unpack('i', file_dict_len)[0] # 将打包的字典长度解包,获取真实的字典长度
file_dict_str = sock.recv(real_file_dict_len) # 通过真实的字典长度,获取真实的字典数据
file_dict = json.loads(file_dict_str) # 将字典数据反序列化(因为在服务端序列化传过来的,所以要反序列化)
temp_len = 0
with open(file_dict.get('file_name'), 'wb') as f:
while temp_len < file_dict.get('file_size'):
data = sock.recv(1024)
f.write(data)
temp_len += len(data) # 下载文件
print('文件上传成功')
return
receive_file()

