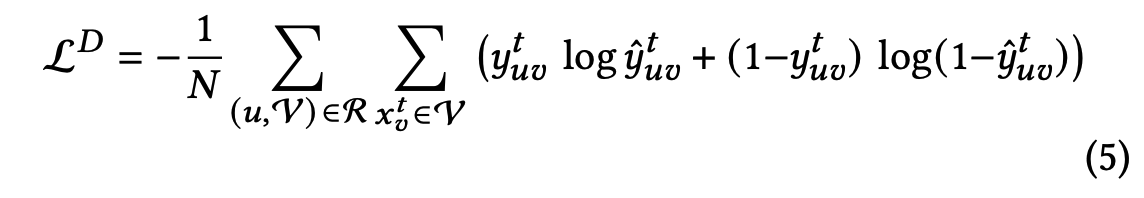阿里重排论文PRS 《Revisit Recommender System in the Permutation Prospective》
背景
这是一篇阿里发表的permutation-wise优化的重排论文,阿里在这篇论文里提出了PRS重排框架,其由两个步骤组成:
1. PMatch:采用beam search算法生成候选序列
2. PRank:设计了permutation-wise model DPWN 计算 permutation-wise 排序指标LR,并选出LR最大的候选序列作为最终的排序结果
PMatch stage
除了采用了ctr模型之外,还训练了next模型预估浏览下一个item的概率,这两个目标就是普通的point-wise的建模方式。得到候选item的ctr score和next score后,融合这两个分数,采用beam search算法生成候选序列

PRank stage
设计了DPWN模型来计算LR(List Reward)指标,DPWN主要有Bi-LSTM和几层DNN组成。
首先使用Bi-LSTM来计算序列的隐含状态,下面是Bi-LSTM的前向计算过程,可以得到前向隐含状态h𝑡->,同理可以得到反向隐含状态,拼接前向隐含状态和方向隐含状态可以得到完整的隐含状态ht
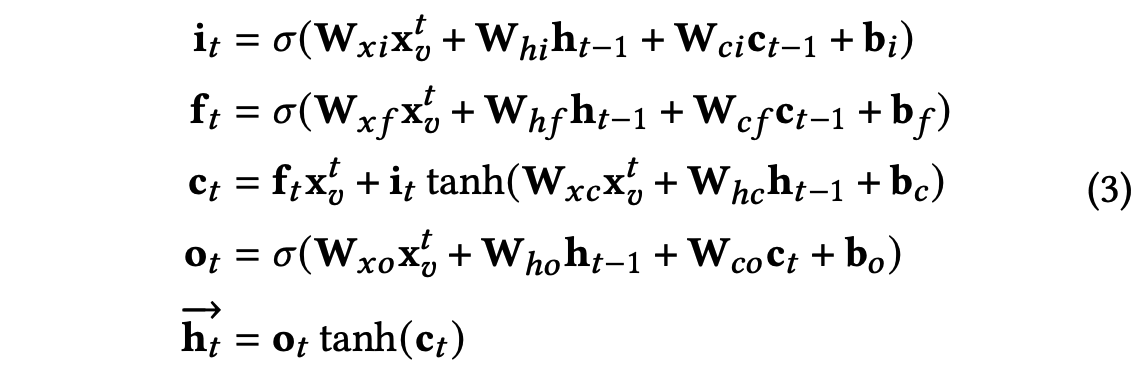
然后拼user feature、item feature、ht过几层DNN得到最终的预估结果:
![]()
最后采用交叉熵损失来训练模型: