


重排模型DLCM
论文名:Learning a Deep Listwise Context Model for Ranking Refinement
背景
在搜索场景下,给定一个查询q,q和d特征的向量表示x(q,d),rank阶段的loss可以表示为:
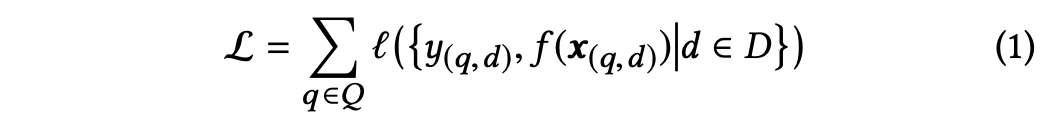
其中:Q是query的集合,D是doc集合,f是rank模型函数
可以看到,传统的rank模型是一种point-wise的建模方法,没有考虑不同doc之间互相的影响。因此这篇论文提出了考虑上下文影响的rerank模型DLCM,其loss可以表示为:
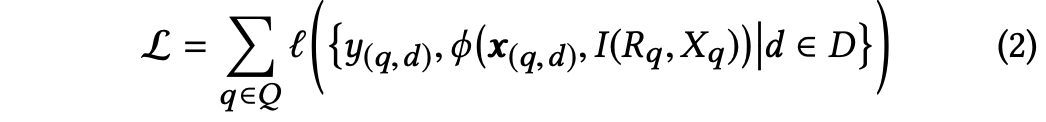
其中:Rq是rank模型 f 的排序结果,Xq = {x(q,d)|d ∈ Rq} ,I 表示local context model,建模上下文信息,φ是最终的打分函数
重点在于如何找到最优的 I 和 φ 来最小化loss
模型结构
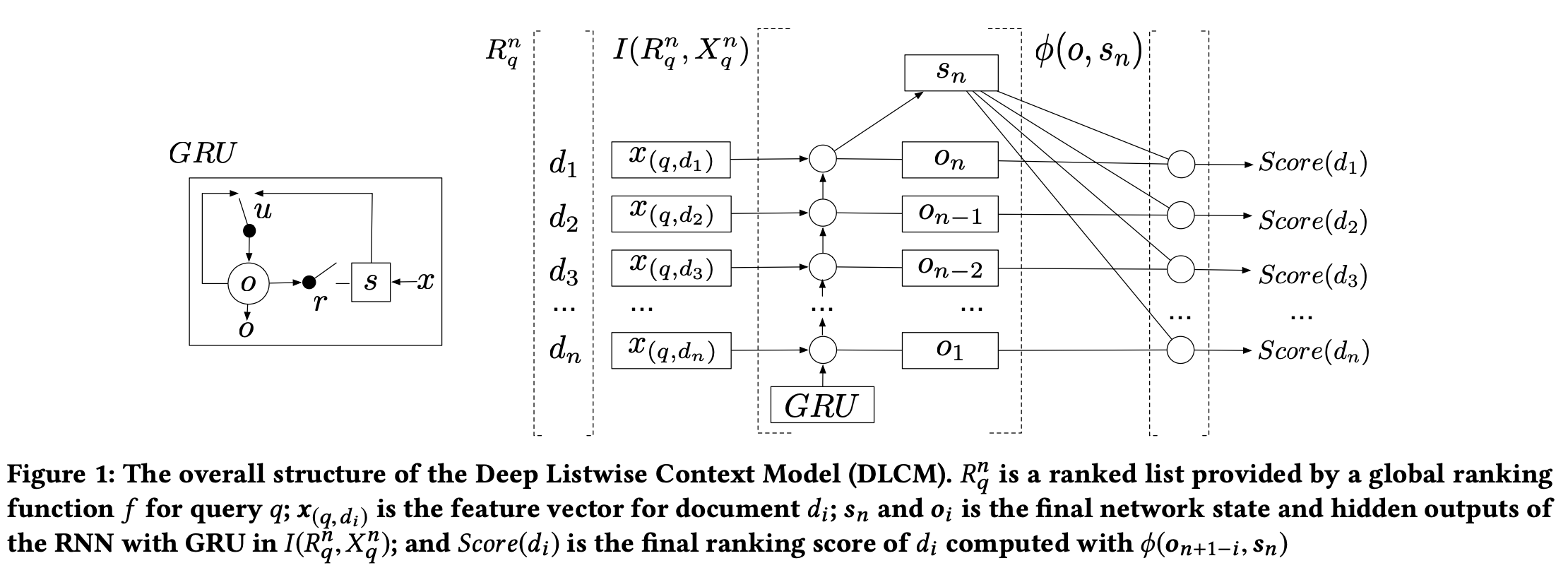
DLCM模型主要包含3个步骤:
1. 用rank模型对doc排序,并用embedding层把(q,d)表示为特征向量x(q,d) (这个特征向量是从rank模型的计算结果,还是rerank阶段通过embedding层训练出来的?)
2. 按rank模型排序位置从低到高把特征向量x(q,di)输入GRU中,最终产生一个隐向量sn和n个隐层输出oi,i∈[1,n],这个模型被称为local context model - I(Rq,Xq)
3. 使用局local ranking function φ(sn, o)进行重排,得到最终的结果
特征提取层
1. 使用两层的神经网络来提取(q,d)的高阶特征,使用了elu作为激活函数:
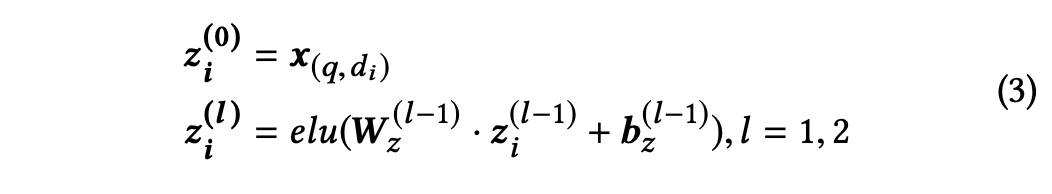
2. 然后concatenate zi2和原始特征向量x(q,d)得到x'(q,d)作为下一部分的输入
listwise局部上下文信息编码层
前面得到了文档在rank阶段的排序结果,以及(q, d)的特征表示x'(q,d),按rank阶段排序结果由低到高输入到GRU中,GRU内部计算逻辑如下:
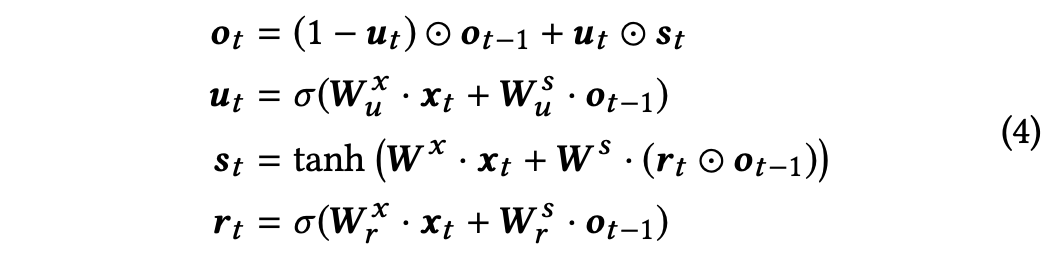
得到结合局部上下文信息的(q,di)表示 oi,以及最终的网络状态表示sn
结合局部上下文信息重排层
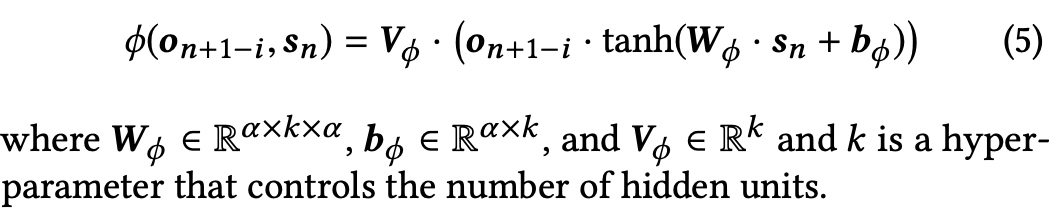
损失函数
论文尝试了常用了两个损失函数ListMLE和SoftRank,并提出了一个新的损失函数AttentionRank
AttentionRank loss的计算流程如下:
1. 计算attention分数:
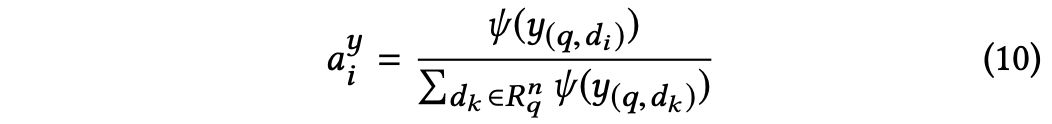
其中ψ(x) = ex if x > 0 else 0
2. 使用交叉熵函数计算label 和 pred attention分布的 loss:
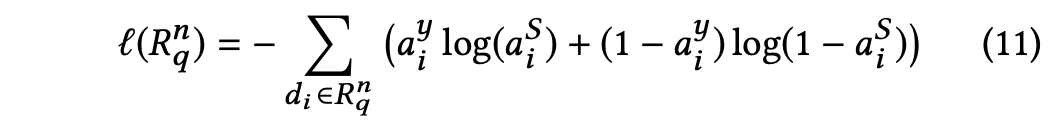
参考资料
https://zhuanlan.zhihu.com/p/390857478
