

阿里电商搜索重排算法:miRNN
论文地址:Globally Optimized Mutual Influence Aware Ranking in E-Commerce Search
背景
传统的排序算法基本都是point-wise的算法,没有考虑到一起展示的其它商品对当前商品的影响。但是在电商场景下,如果一个商品和它一起展示的同类商品的价格都比它高,那么这个商品会有更大的概率被购买。为了解决这个问题,这篇论文提出了考虑了context信息的rerank算法
问题定义
让S = (1, ..., N )表示待排序的item集合,O表示S中商品所有排列结合,o = (o1 , ..., oN ) ∈ O表示其中一种排列
商品集合一种排列的GMV可以表示为:
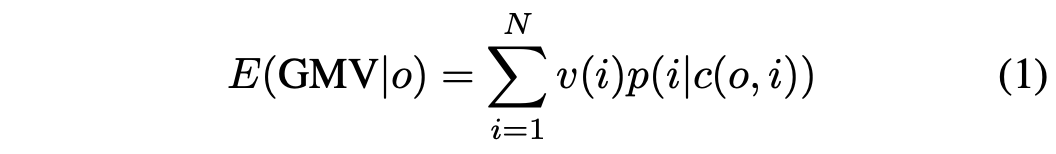
其中 c(o, i) 表示 rank conetxt,p(i|c(o, i)) 表示商品在此排列下的购买概率,v(i) 表示商品i的价格
我们的目标就是找到GMV最大的一种商品排列:
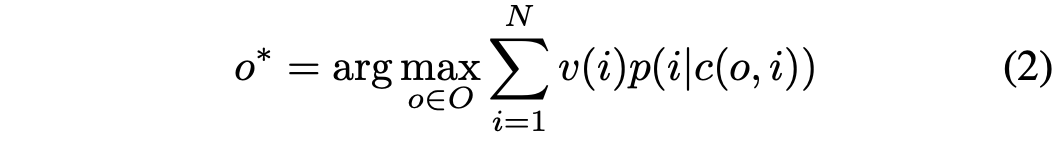
现在可以把上面的等式拆解为两个问题:
- 如果准确的计算p(i|c(o, i))
- 如何高效的找到o∗
问题1使用深度学习方法就可以解决,问题2想要找到最优的排列的时间复杂度式N!,直接计算时间复杂度不可接受,因此论文采用了两种简化处理方法
全局特征扩展
第一种简化处理的方式就是虽然考虑一个排列中其它商品对当前商品的影响,但是不考虑商品具体顺序带来的影响。以价格特征为例,会进行如下处理,得到全局特征(其他特征从处理类似):

可以看到,处理后的全局特征带了context信息,拼接全局特征和这个商品的局部特征过包含3个隐层的DNN,以交叉熵作为loss训练模型,就可以计算p(i|c(o, i))
这样做的缺点是忽视了position信息,那么最终的结果具体如何排序呢,论文中只是简单的按预估GMV从高到低排序
把排序过程看作序列生成
第二种简化方法就是我们只考虑排在这个商品前面的商品对它的影响,不考虑排在这个商品后面的商品对它的影响,可以表示为p(i|c(o,i)) = p(i|o1,o2,...,odi−1),
这个假设有两个好处:
- 符合用户的习惯,用户一般是从上往下浏览,一般只会关注排这个商品前面的商品
- 在这个假设的基础上可以采用beam search算法高效的搜索出接近最优的商品排列组合
有了上面的假设之后,论文采用了两种模型来预估:
The Basic RNN Model
第一种是使用RNN模型来预估p(i|c(o, i)) :
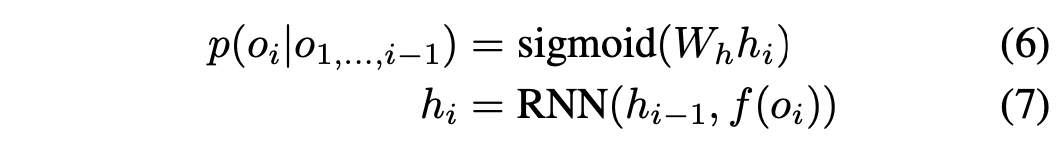
具体来说就是把最优排列的选择当作一个序列生成问题,每一步都选去top k个候选item,直至得到想要长度的序列,从这k个序列中选取GMV最大的序列作为最终的结果
RNN Model with Attention
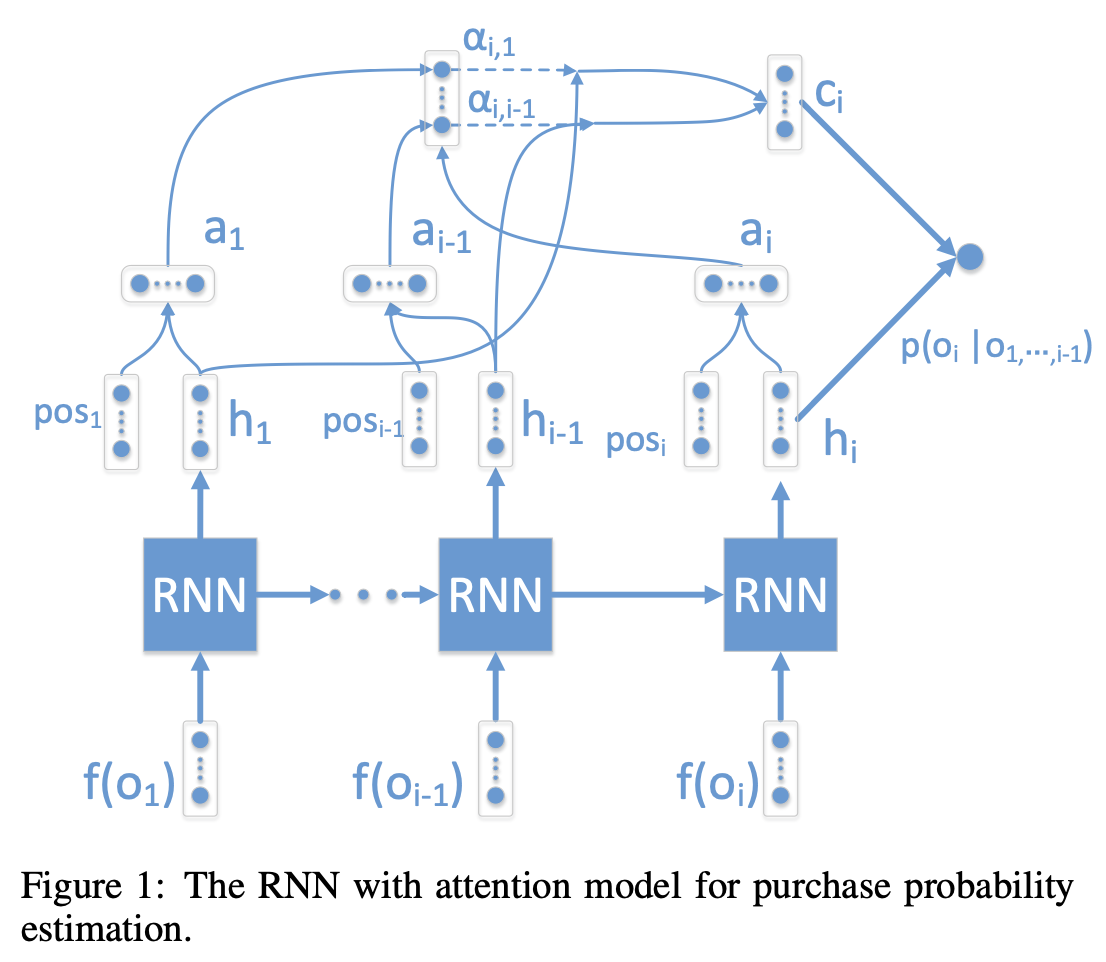
论文中使用了LSTM来训练预估,发现LSTM学不到长期依赖,具体来说在计算第20位的商品时,排在前4位的商品对它几乎没有影响。这不符合排在前几位影响最大的直观感受,因此论文提出了结合了attention机制的RNN模型(模型结构如上图所示):
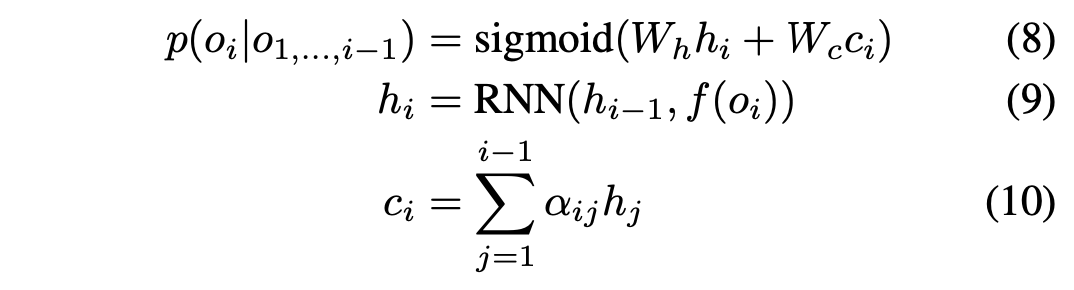
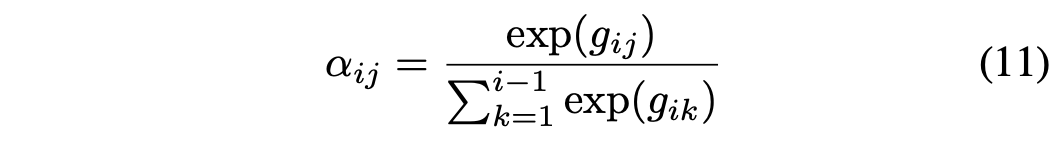
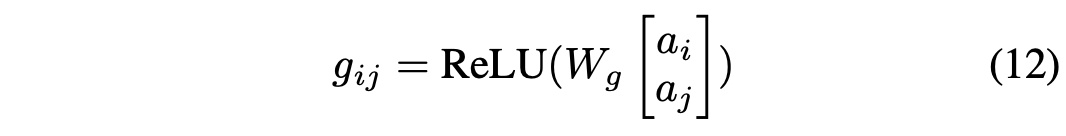
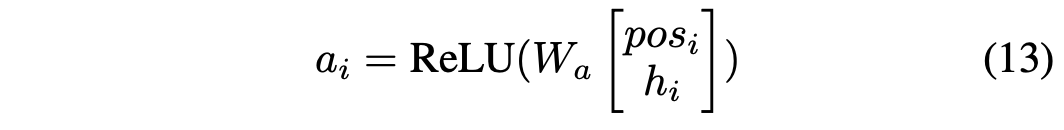


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫
2023-05-23 经典的Graph Embedding方法:DeepWalk 和 Node2vec