


阿里pdn召回
背景
目前最常见的召回可以分两类:
1. 以item cf为代表的i2i召回
2. 以双塔模型为代表的u2i召回
下面是这两种召回的优缺点:
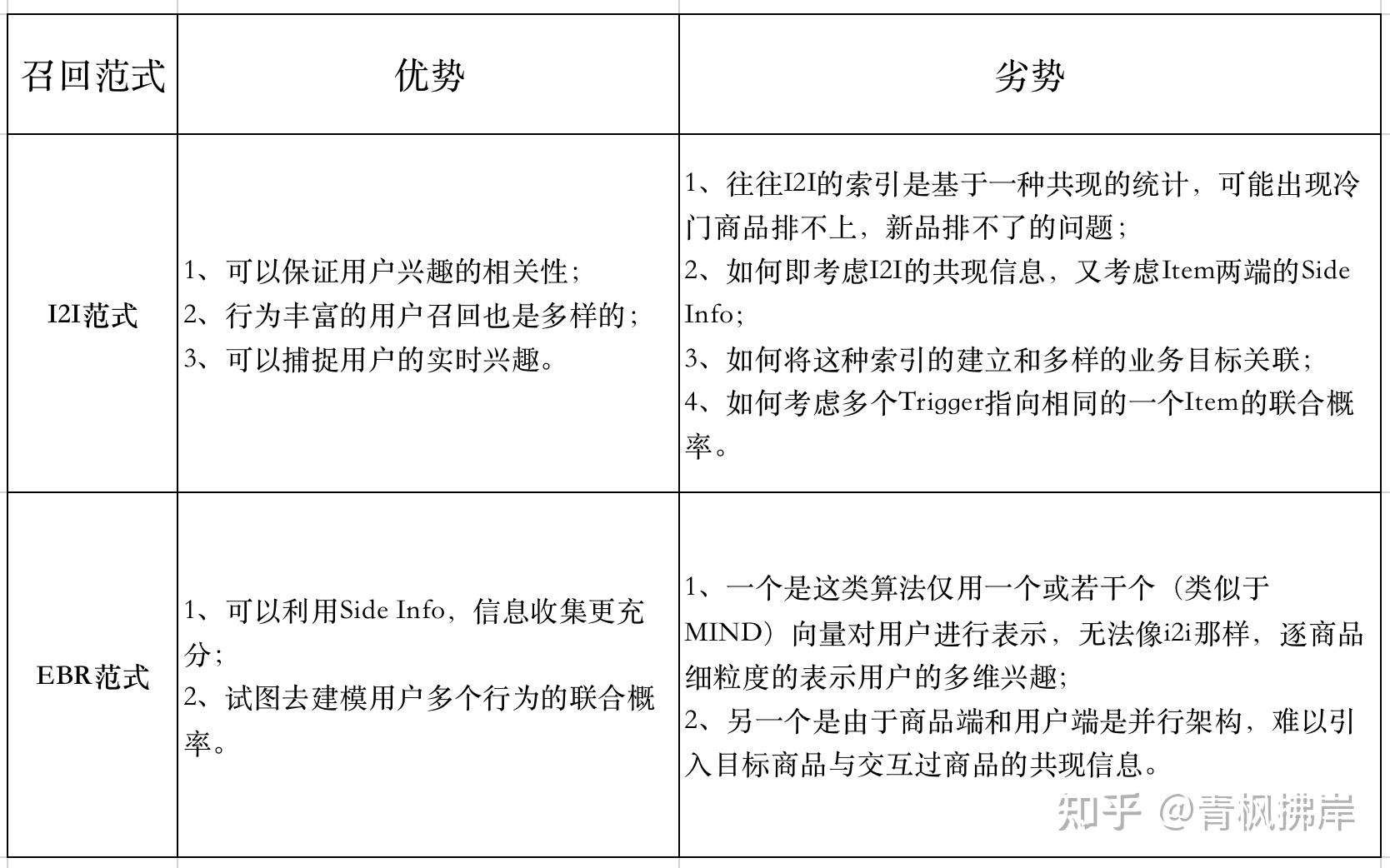
总结来说就是i2i不好加入side info信息,u2i不好逐个行为粒度的表示用户兴趣,pdn算法正结合两种方法的优点
模型结构

pdn的模型结构如上图所示,下面是相关符号定义:

pdn模型可以用下式表示:
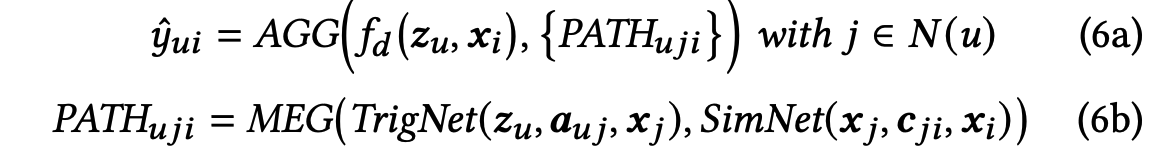
pdn模型主要由两个部分组成:
1. direct net:就是一个u2i的双塔
2. merge(TrigNet, SimNet):对于用户交互过的每个item 和 target item (一条2跳的path)用 TrigNet 和 SimNet建模,并对所有的路径建模结果求和
因此pdn模型也可以表示为:
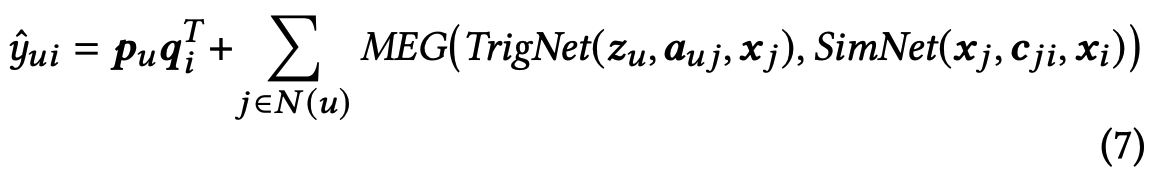
TrigNet
TrigNet 可以看做是传统U2I的过程的plus版本,PDN利用TrigNet计算用户对每个交互item j的喜爱程度来得到用户的多种兴趣得分(一个路径算一种兴趣),TrigNet的计算方式如下所示:
Similarity Net
SimNet可以看作是带side info的i2i,SimNet的计算方式如下所示:
![]()
MEG
最后融合TrigNet和SimNet的计算结果,计算方式如下:
![]()
为了确保PDN收敛到更优的区域,在Trigger Net、Similarity Net的最后一层,我们利用exp()代替其他激活函数来约束输出为正,
为什么不允许两个网络输出结果为负,文中给出了解释:
如果允许负权重的输出,导致PDN在更宽泛的参数空间中搜索局部最优值,这很容易导致过度拟合。由于在真实使用的时候,Similarity Net是用于生成Index,而Trigger Net是用于Trigger Selection。这种过拟合的后果可不是效果差一些,而很可能导致学习出来的索引不可用。
损失函数
用户是否会点击该商品可以被看作是二分类任务。因此,PDN融合了n+1条路径的权重以及偏差得分得到用户与商品的相关性得分,并将其转化为点击概率:
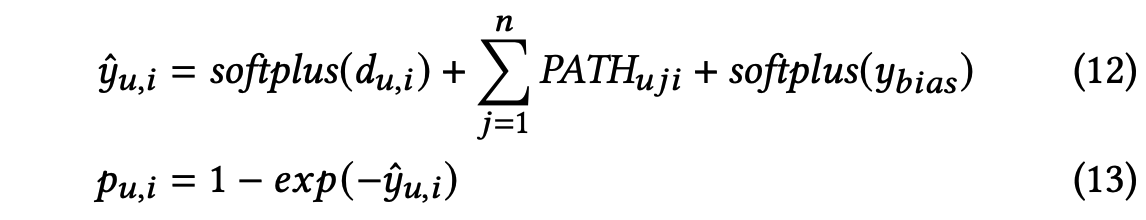
最终采取交叉熵损失作为PDN的loss function:
![]()
在线服务

