

粗排模型总结
双塔模型介绍
由于粗排的候选数目比精排多很多,粗排无法做的和精排一样复杂。现在业内比较通用的方案是采用双塔模型,左边塔建模user embedding,右边塔建模item embedding,由于用户的行为经常发生变化,user tower需要经常更新,但是item状态很少发生变化,可以离线算好所有的item embedding。计算user embedding和item embedding的相似度即可得到 user和item的预估分,在线serving的时候可以通过ANN算法快速检索出top k item

算塔模型的局限性:
1. user和item最后才交互,此时的user embedding和item embedding已经丢失了许多原始特性信息,导致效果有损
2. 无法引入user-item交叉特征
SENet双塔模型
在user tower和item tower中都加了SENet做特征选择,但是并没有解决u侧特征和i侧特征交互过晚带来的效果损失的问题

美团Dual Augmented Two-tower Model

user tower多了一个输入au,对于一个正反馈,拟合au和item embedding相似
item tower多了一个输入av,对于一个正反馈,拟合av和item embedding相似
au和av称为增强向量
loss 函数如下所示,论文称为mimic loss,mimic loss的目标是通过所有正反馈交互,来让增强向量去拟合另一个tower对应的query或者item:
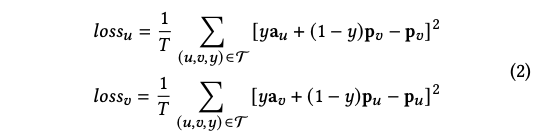
可以看到,对偶增强双塔特征进DNN前通过增强向量引入了user-item之间的交互信息,但是引入的交互信息是user正反馈的均值,不是user_id和item_id粒度的正反馈
粗排deep化
如阿里COLD,COLD已经不能算双塔模型,而且和精排类似的模型结构,user特征和item特征直接进NN进行交互,带来的问题就是延迟上涨,需要做大量的工程优化
也可以保留原来的双塔结构,concat(user embedding,item embedding)过NN
引入user和item交叉特征
如可以引入match bias特征

