

快手长短期序列建模论文CLSR
背景
用户是否点击一个物品可能受长期兴趣和短期行为的影响,用户的长期兴趣一般比较稳定,短期兴趣会不断变化。现有的工作中对长期兴趣和短期兴趣的建模师混合在一起的,这片论文提出了一种对长期兴趣和短期兴趣分开建模的方法。
方法
用户兴趣建模
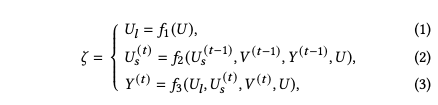
U:用户属性,包含了用户ID和行为序列
Ul:用户的长期兴趣表示
Us(t):用户在t时刻的短期兴趣表示
V(t-1):t-1时刻交互的item
Y(t):融合用户的长短期兴趣,表示t时刻用户是否会和V(t)发生交互
- 长期兴趣:长期兴趣相对稳定,因此这里是从整个序列中提取。
- 短期兴趣:随着用户不断与推荐商品进行交互,短期兴趣会不断变化。例如,用户可能会在点击某个商品后建立新的兴趣。同时,用户也可能逐渐失去某些兴趣。也就是说,短期利益是时间相关的变量,因此利用前一时刻的兴趣来建模当前时刻的兴趣。
- 交互预测:利用长短期兴趣和交互数据进行预测。
下面详述具体的建模过程
为长短期兴趣生成查询向量
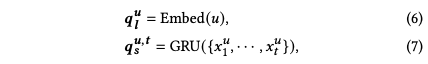
得到长短期新闻的query表示之后,分别对长短期兴趣进行编码,得到长短期兴趣的表示:
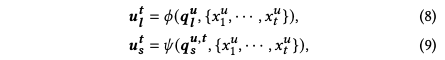
长期兴趣编码
长期兴趣编码就是一个self-attention结构,公式如下,其中W为可学习参数,τ表示多层MLP,||表示拼接,E(x)表示商品的embedding
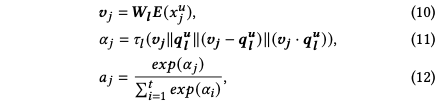
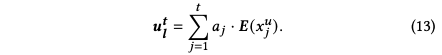
短期兴趣编码
利用循环神经网络捕获短期兴趣,其中W为可学习参数,ρ表示循环神经网络模型,例如LSTM,GRU等
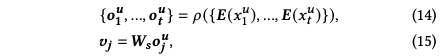
利用长期兴趣中计算注意力系数的方式可以同样利用现有的v可以求得短期兴趣的注意力系数b。加权求和后得到短期兴趣embedding,如下:
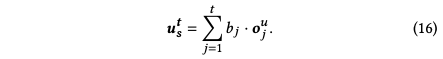
自监督解耦长短期兴趣
上面提到了使用两个编码器来分别建模用户的长短期兴趣,但是对于用户的长短期兴趣,我们是无法获得显式label的,那么如何训练呢?
论文采用了用户整个交互历史的平均表征作为长期兴趣的代理(label),并使用最近 次交互的平均表征作为短期兴趣的代理:
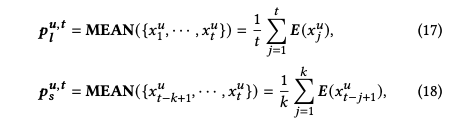
有了label之后,我就训练用户的长期兴趣和短期兴趣表示,具体的,我们希望:
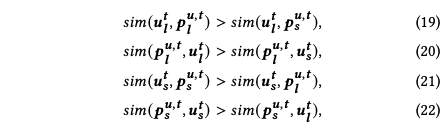
以长期兴趣为例,长期兴趣保证和长期兴趣代理表征的相似度要大于长期兴趣和短期兴趣的表征,并且大于短期兴趣和长期兴趣代理之间的相似度
论文中采用BPR损失或Triplet loss来对上述的约束关系构建损失函数,公式如下:
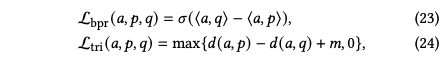
损失函数就是把四个损失函数相加,如下,其中f()表示上诉两种损失函数之一:
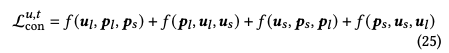
长短期兴趣融合
有了长短期兴趣表示后,我们需要融合用户的长短期兴趣预测用户下一刻的兴趣。简单的聚合器,如sum和concatation,假设长短期兴趣的贡献是固定的,这在许多情况下是无效的。事实上,长期还是短期更重要取决于历史顺序。例如,当用户持续浏览同一类别的物品时,他们主要是受短期兴趣的驱动。同时,长期利益的重要性也取决于target。例如,一个运动爱好者可能仍然会因为长期的兴趣点开一个推荐的自行车,即使他/她已经浏览了几本书。因此,我们将历史序列和目标项都作为聚合器的输入,其中历史序列使用GRU进行压缩。
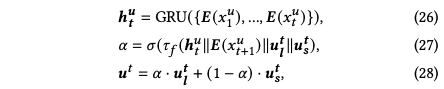
最后再经过两层MLP进行预测:
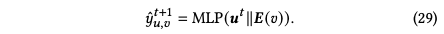
损失函数
和常用的模型一样,论文采用了对数似然损失:
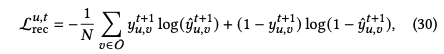
加上前面的自监督损失,完整的损失函数如下损失:
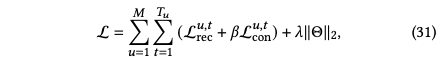
参考资料
https://zhuanlan.zhihu.com/p/476984577
