

阿里多兴趣序列建模论文MIND
背景
现有的工作只把用户表示成一个向量,但一个用户兴趣向量很难捕获用户多方面的兴趣,MIND是阿里提出的用于召回阶段的多兴趣建模论文,这篇论文把用户表示成了多个兴趣向量
方法
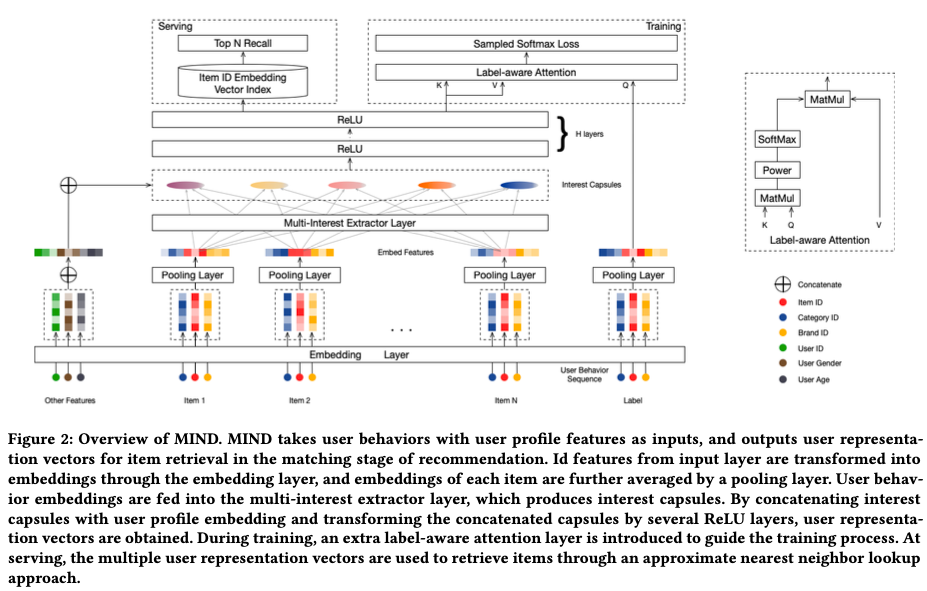
MIND的模型结构如下图所示,和常用的召回模型一样,先把每个用户表示成向量:
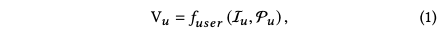
其中 Iu是用户的行为序列,Pu是用户属性特征,Vu是d*k维的向量,d用户兴趣向量的长度,k是用户兴趣向量的个数
然后把item也表示成一个向量:
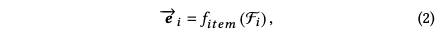
其中ei是d*1维的向量,Fi是item属性特征
得到用户的兴趣向量和item向量后,计算score,并做topk检索:
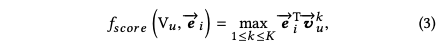
为了学习用户的多个兴趣向量,这篇论文通过类似聚类的方法,将用户的历史行为聚合分组为多个cluster,一个cluster代表用户一个方面的兴趣
capsule network
提取用户兴趣向量主要借鉴的方法是capsule network(胶囊网络),因此在进入Multi-Interest Extractor Layer讲解之前,需要搞清楚capsule network的原理。capsule network由low-level的capsule和high-level的capsule组成,目的在于通过 Dynamic Routing(动态路由)的方式,根据low-level capsule来计算得到high-level的 capsule。
动态路由的目标是通过多轮迭代的方式根据low-level capsules计算出high-level capsules,计算过程如下所示:

bij被初始化为0,计算过程一般迭代3次,然后固定high-level capsules的值作为下一层的输入
B2I Dynamic Routing
论文对经典的capsule network作了一些调整,称为Behavior-to-Interest (B2I) dynamic routing,可以从字面意思理解,就是通过用户的行为,通过动态路由的方法得到用户兴趣向量。在这个场景下,low-level capsule对应用户的行为序列,high-level capsule对应用户的多个兴趣capsule。主要包含了一下三个方面的调整:
1. Shared bilinear mapping matrix
整个胶囊网络共享映射矩阵S,这样做有两个好处:
- 提升模型的泛化性
- 把用户不同的兴趣胶囊映射到同一个向量空间
2. Randomly initialized routing logits
前面提到routing logit bij 初设化为0,但由于共享了双线性映射矩阵S,这就会导致相同的兴趣capsule,即第一次动态路由iteration时K个初设兴趣capsule相同。所以将 bij 初设化修改为高斯分布 N(0, δ2)
3. Dynamic interest number
根据用户行为序列长度不通,设置不通的兴趣胶囊数目,这样做的好处可以降低模型的学习难度,减少资源开销
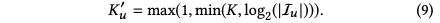
完整的算法流程如下所示:

Label-aware Attention Layer
在上一步提取K兴趣capsule之后,与用户基础属性embedding进行拼接,然后输入到H层relu全连接层网络,得到K个最终能够表征用户兴趣的向量Vu
在得到k个用户兴趣向量后,引入注意力机制,计算target item和k个用户向量的加权和:
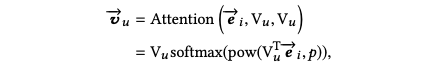
其中p是一个超参数:
- 当p接近0时,则每个兴趣向量趋于相同的注意力权重
- 当p趋于无限大时,则会变成一种hard attention:只有最大注意力的兴趣向量起作用,而其他兴趣向量几乎被忽略,可以理解是每次只激活一个兴趣向量。
论文指出,采用hard attention可以更快收敛。
Training & Serving
Train
和youtobe模型类型,采用了softmax作为激活函数,负样本来自于随机采样:
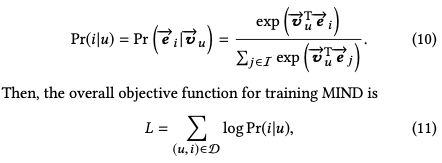
Serving
用户向量和item向量做近邻检索
