

InstructGPT《InstructGPT: Training language models to follow instructions with human feedback》解读
背景
GPT-3 虽然在各大 NLP 任务以及文本生成的能力上令人惊艳,但是他仍然还是会生成一些带有偏见的,不真实的,有害的造成负面社会影响的信息,而且很多时候,他并不按人类喜欢的表达方式去说话。在这个背景下,OpenAI 提出了一个概念“Alignment”,意思是模型输出与人类真实意图对齐,符合人类偏好。因此,为了让模型输出与用户意图更加 “align”,就有了 InstructGPT 这个工作
技术方案
InstructGPT采用了GPT3的网络结构,在GPT3模型的基础上加了如下几个训练步骤:
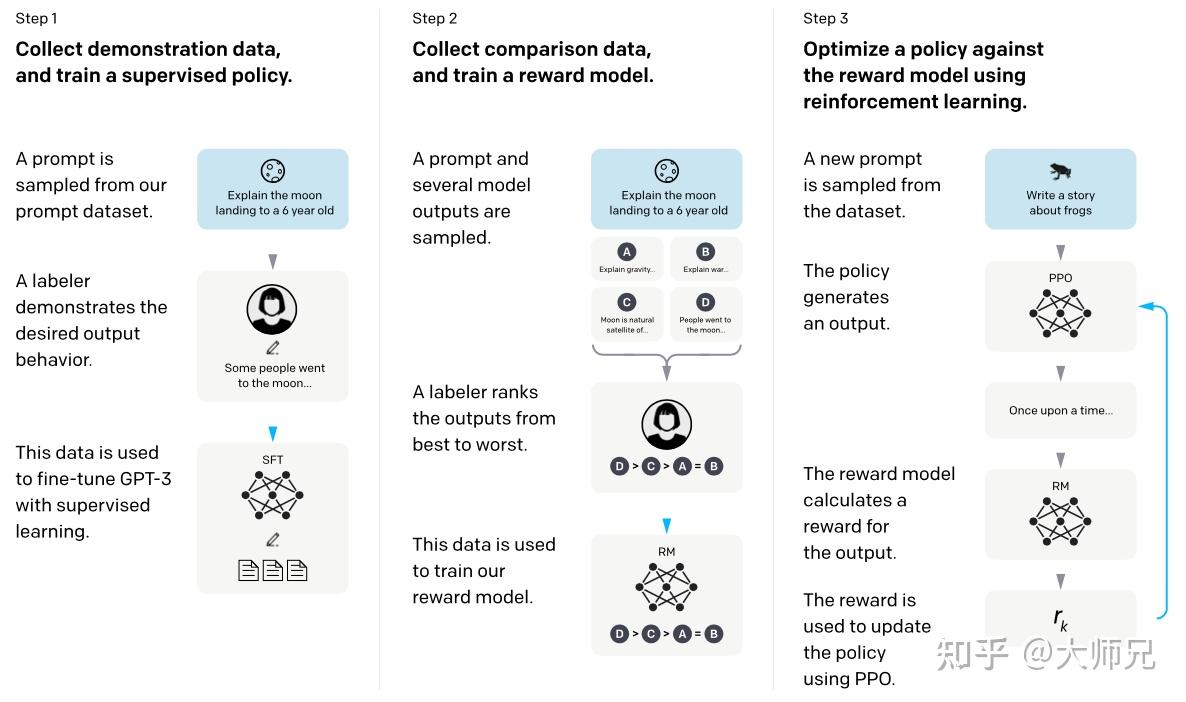
- Step1:在监督数据集上(包含13K的prompts)微调模型(SFT)
- Step2: 在RM数据集(包含33K的prompts)上训练reward model
- Step3:在PPO数据集(包含31K的prompts)上通过RLHF训练出符合人类偏好的模型
其中 Step3 和 Step3可以多轮迭代进行
reward model
输入一个promopt,让InstructGPT随机生成K个回答,然后让labeler对这些回答进行排序,奖励模型的架构和InstructGPT相同,只不过把最后一层换成投影层输出score,训练loss如下:
\(\mathrm{loss} \left( \theta \right) = - \frac{1}{ \binom{K}{2} } \mathbb{E}_{ \left( x, y_w, y_l \right) \sim D } \left[ \log \left( \sigma \left( r_\theta \left( x, y_w \right) - r_\theta \left( x, y_l \right) \right) \right) \right]\)
其中w排在l前面,其实就是最大化正序对score的差值
RLHF(Reinforcement Learning from Human Feedback)
使用初始化的策略模型生成一篇文章的摘要,然后使用奖励模型对该摘要打分,再使用打分值借助 PPO 算法重新优化策略模型,目标函数为:
\[ \begin{align*} \text{objective}(\phi) =& E_{(x,y) \sim D_{\pi_\phi^{\text{RL}}}} \left[ r_\theta(x,y) - \beta \log \left( \frac{\pi_\phi^{\text{RL}}(y \mid x)}{\pi^{\text{SFT}}(y \mid x)} \right) \right] + \\ & \gamma E_{x \sim D_{\text{pretrain}}} \left[ \log \left( \pi_\phi^{\text{RL}}(x) \right) \right] \end{align*} \]
- \(\pi_\phi^{\text{RL}}\) 表示我们最终想要得到的语言模型(Actor模型),其中\(\phi\)是模型参数
- \(\pi^{\text{SFT}}\) 表示第1步的SFT模型
- \(D_{\pi_\phi^{\text{RL}}}\) 是31k Prompt的数据集
- \(D_{\text{pretrain}}\)是预训练阶段的数据集
这个式子的意思是: 对于 \(D_{\pi_\phi^{\text{RL}}}\) 中的每一个Prompt \(x\),通过语言模型(RL算法中的Policy)生成一个回复 \(y\),把 \(x\) 和 \(y\) 喂给打分模型得到分数 \(r_\theta(x, y)\)。通过优化语言模型的参数 \(\phi\) 使得打分模型的分数越大越好。 第2项的意思是说:RL阶段初始的模型是\(\pi^{\text{SFT}}\),实时更新的模型是\(\pi_\phi^{\text{RL}}\),那么PPO算法其实是不希望这俩模型之前差距太大,所以就给目标函数减去了一项KL散度,以减轻过度优化。当\(\pi^{\text{SFT}}\)和\(\pi_\phi^{\text{RL}}\)完全一样时,\(-\beta \log \left( \frac{\pi_\phi^{\text{RL}}(y \mid x)}{\pi^{\text{SFT}}(y \mid x)} \right) = 0\)。 第3项的意思是说:RL阶段希望语言模型的输出更像人类,但是可能对于原来的生成任务而言性能就不那么好了。因此这一项\(\log(\pi_\phi^{\text{RL}}(x))\)的意思是说从GPT-3的预训练文本中采样一些文本 \(x\),希望模型尽量增大生成文本 \(x\) 的概率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号