

推荐系统中常用的特征选择方法
背景
推荐系统已经迈入了深度学习时代,模型结构比较复杂,下面介绍在深度学习背景下常用的特征选择方法
1. 根据特征在正负样本上分布的差异
直观感觉上一个特征越重要,那么它在正负样本的分布差异应该是越大的,基于此我们可以用KL散度来表示特征重要性,但是KL散度是非对称,我们可以采用JS散度来表达特征重要性,JS散度的计算公式如下所示:
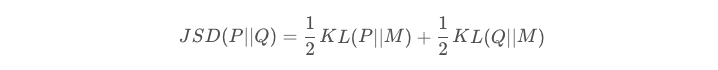
2. 根据删除特征后auc变化
二分类问题中常用的离线评价指标就是auc,一个直观的想法是我们先用全量特征训练一个模型,然后逐个删除特征看auc变化来判断特征重要性,但是这样每次都要重训模型,费时费力。可以采取折中的方法,改为只在预估的时候把该特征全部置位0(或者是在一个batch样本中打乱该特征),看auc变化
3. 根据该特征在模型中的权重大小
还有一种想法是直接查看该特征在模型中相关的权重大小来作为特征重要性,如bias、embedding、这个这个slot在第一层NN的权重。或者单独训练一个模型,如LR模型,或者把embedding压缩到1维
4. AutoFIS
AutoFIS是华为2020年发表的论文《AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction 》,该论文提出了一种选择交叉特征的方法。简单来说就是在FM的基础上,在每个交叉特征前面加了个权重来学习特征重要性
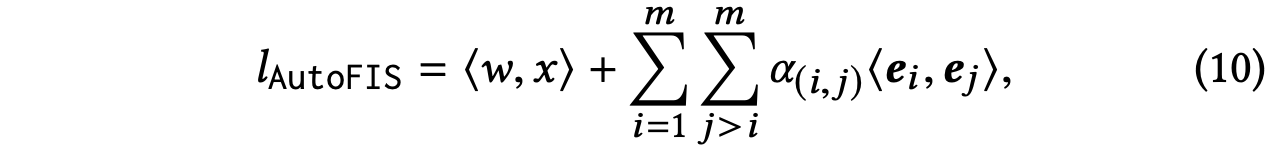
5. 基于图
待补充,见这篇论文《Detecting Beneficial Feature Interactions for Recommender Systems》


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2020-05-29 Git基本命令