


Graph Embedding:LINE算法
背景
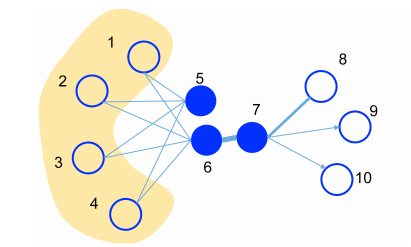
如上图所示,结点6和7是相邻结点,他们应该是相似结点,结点5和6虽然不是相邻结点,但是它们有共同的相邻的结点,因此它们也应该是相似结点。
基于词观察,LINE算法提出了一阶相似性算法和二阶相似性算法
First-order
我们首先如如下公式来计算结点i和j的联合概率分布:
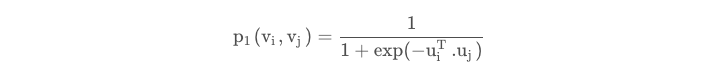
其中ui,uj分别为节点i和节点j的embedding向量表示,同时我们依据边的权值,也可得经验分布:
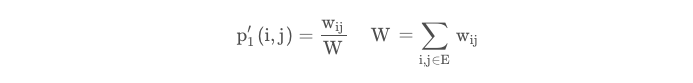
其中W为图中边的权值之和,这样我们可以用交叉熵来计算loss:
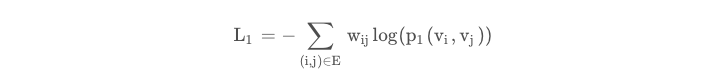
上面的公式可以看出,两个向量的内积越大,p1越大。且由于内积没有方向,所以First-order只适合无向图
Second-order
这里对于每个顶点维护两个embedding向量,一个是该顶点本身的表示向量ui,一个是该点作为其他顶点的上下文顶点时的表示向量ui'。
我们用如下公式来计算结点i和j的转移概率分布:
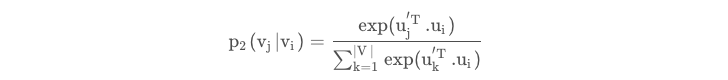
其中|V|为结点i的邻居结点数目
同时我们给出second-order 的经验分布定义:
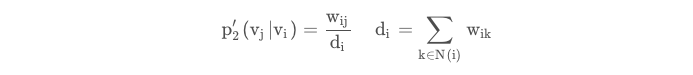
其中di为节点i的出度,N(i)为节点i的邻居结点。
同时我们给出second-order 的经验分布定义:
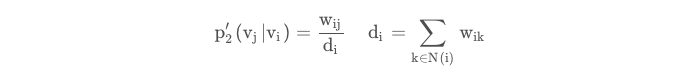
其中di为节点i的出度,N(i)为节点i的邻居节点。
可以看出first-order是在边的粒度优化的,而second-order是该以一个节点的一阶领域来优化的,econd-order不仅能用于无向图,也可用于有向图
Second-order训练加速
由于计算2阶相似度时,softmax函数的分母计算需要遍历所有顶点,这是非常低效的,论文借鉴了word2vec,采用了负采样优化的技巧,目标函数变为:
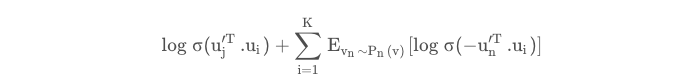
其中Pn(v)表示结点n被采样的概率,结点n被采样的概率和结点的度数dv3/4成正比
参考资料
https://zhuanlan.zhihu.com/p/56478167
https://blog.csdn.net/weixin_38877987/article/details/118422847


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏