
推荐广告中常用的特征交叉方法
背景
在LR模型时代,特征交叉一般依赖人工经验,存在以下几个缺点:
1. 依赖人工经验很难构建高阶交叉特征,一般只能构建二阶交叉特征
2. LR中构建的二阶交叉特征必须是这两个特征值一起在样本中出现过模型才能学的到,而在推荐系统中特征是非常稀疏,很多特征其实是没有共现过的
到了深度学习时代,DNN可以隐式的学习任意阶的特征交叉,似乎已经不再需要显式的特征交叉了,但是实践中DCN等特征交叉方法仍然取得了效果的提升,个人认为主要是以下几个原因导致的:
1. 三层的神经网络虽然理论能拟合任意分布,但是这是建立在宽度足够大、数据量足够多的情况下,而显式的特征交叉方法可以缩小假设空间,降低模型的拟合难度
2. DNN同层的元素之间只有加法能力,没有乘法能力,DCN等特征交叉方式引入了乘法能力
下面介绍一下推荐广告中常用的特征交叉方法
FM
FM是推荐系统用的最广泛的特征交叉方法了,FM的式子如下:
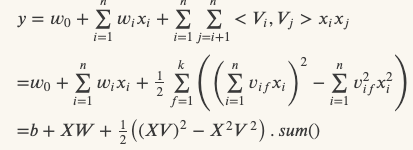
原始式子的时间复杂度是O(kn2),经过化简后时间复杂度是O(kn),其中k是embedding维度,n是特征数目
FM在推荐模型中实际使用时,其实就是两个特征对应embedding的点乘求和,并且为了减少计算量,不可能对任意两个embedding作交叉,一般是在item侧选取部分embedding作为一组,然后在user侧选取部分embedding作为另一组,先对组内embedding做pooling后再做交叉
FM的缺点是一般只能用与做二阶特征交叉,如果做高阶特征交叉,时间复杂度太高
NFM
NFM模型是将FM与DNN进行融合,具体来说是把过FM得到的二阶交叉特征concat或者pooling后输入到DNN中
DCN
DCN中用于特征交叉的部分叫Cross Net,一层Cross Net的结构可以用如下公式表示:
![]()
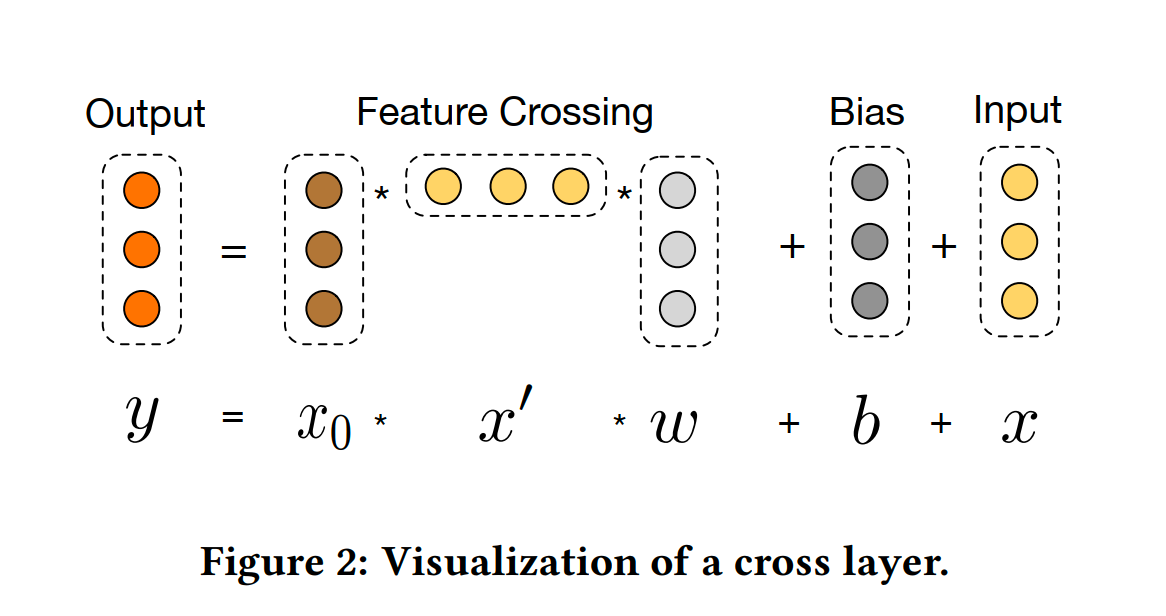
其中x0为输入embdding的拼接,xl为第l层Cross Net的输出
DCN特征交叉的阶数由Cross Net的层数决定,最后一层的输出包含了所有阶数的交叉
DCN的时间复杂度为O(ml2),其中m是Cross Net的层数,l是embedding维度和。在实践中,可以先计算xlTWl这样时间复杂度可以降到O(ml)
DCN-V2
DCN-V2用于特征交叉的部分可以用如下公式表示:
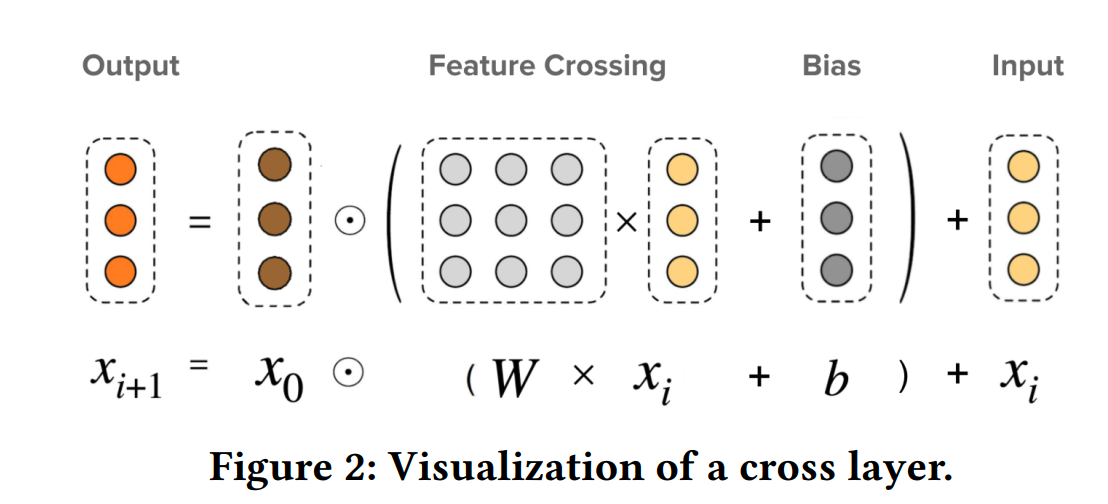
对比dcn-v和dcn-m和可以发现,dcn-v中不同行的权重是相同的,不同行无法引入差异化的特征组合。dcn-m中不同行的权重是不同的,不同行可以引入差异化的特征组合
DCN-V2的时间复杂度是O(ml2),其中m是Cross Net的层数,l是embedding维度和。在实践中,可以采用矩阵分解的方法把时间复杂度降到O(Omrl)
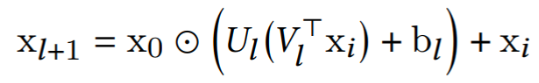
DCN、DCN-V2是bit-wise的交叉方式,同个embeding内bit也会做交叉,可能会增大模型的学习难度
xDeepFM
xDeepFM中用于做特征交叉的网络叫CIN,CIN的结构可以如下公式表示:
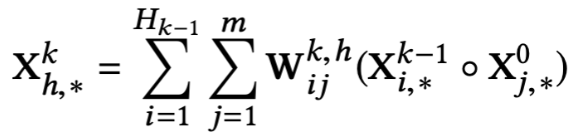
CIN特征交叉过程可以用如下两步表示:
1. 对输入的m个特征向量和和k-1层输出的Hk-1个特征向量两两做点乘,得到m*Hk-1个向量
2. 求这m*Hk-1个向量的加权和,重复Hk次
和DCN不同,xDeepFM中的第k层输出,只包含了k阶特征交叉,所有最后要求所有层的sum pooling
xDeepFM的时间复杂度为O(mhkn2),其中m是CIN层数,h是每层求加权和的次数,k是embedding维度,m是特征数目
按xDeepFM原公式直接上线会使延迟大幅上涨,一般需要简化,原公式是先对两层特征向量作交叉然后求加权和,可以简化为先求每层特征向量的加权和,然后做交叉
Senet
1. 先对每个embedding求mean、min、max,然后concat在一起
2. 然后通过一个DNN,得到一个slot_num * 1的权重向量,复制最后一维,得到slot_num * emb_dim的向量,reshape成一维向量,得到权重向量
3. 最后把embdeding concat和权重向量做点乘


def swish(x,alpha = None): if alpha is not None: return x * tf.math.sigmoid(alpha * x) return x * tf.math.sigmoid(x) def se_block(features, model_name, kernel_initializer = he_initializer()): print("features: ", features) # (batch_size, feature_num, dim) mean_pool = tf.concat([tf.reduce_mean(features,-1,keepdims=True),tf.reduce_max(features,-1,keepdims=True),tf.reduce_min(features,-1,keepdims=True),tf.math.reduce_std(features,-1,keepdims=True)],axis = -1) print("mean_pool: ", mean_pool) mean_pool_middle = tf.reshape(mean_pool,[-1,mean_pool.shape[-2] * mean_pool.shape[-1]]) mean_pool_middle = tf.layers.dense(mean_pool_middle, mean_pool_middle.shape[-1], kernel_initializer=kernel_initializer, name=model_name+"_se_layer0") mean_pool_middle = tf.compat.v1.layers.batch_normalization(mean_pool_middle, trainable=is_training, name=model_name+"_se_bn_0") mean_pool_middle = swish(mean_pool_middle,5.0) print("mean_pool_middle: ", mean_pool_middle) print("features.shape[-2]: ", features.shape[-2]) slot_weight = tf.layers.dense(mean_pool_middle, units = features.shape[-2], kernel_initializer=kernel_initializer,name=model_name+"_se_layer1") print("slot_weight: ", slot_weight) slot_weight = tf.compat.v1.layers.batch_normalization(slot_weight, trainable=is_training, name=model_name + "_se_bn_1") slot_weight = tf.expand_dims(tf.math.sigmoid(slot_weight),-1) print("slot_weight: ", slot_weight) return slot_weight * features
CAN
AutoInt
用attention的方式来实现特征交叉,其实现特征交叉的方式分为以下两步:
1. 利用attention的方式计算两个特征的相似性权重
2. 对一个特征,求其与所有的特征的加权和

 浙公网安备 33010602011771号
浙公网安备 33010602011771号