

Twitter延迟转化论文《Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction》阅读
背景
由于用户的兴趣是实时变化的,现代推荐、广告系统采用了流式更新的方式来捕捉用户实时兴趣的变化。实时训练的方式面临的一个难题就是正样本的回传是有延迟的,一个实时发送的负样本其实是无法确认是否是真的负样本的。也就是说实时观测到的数据流是一个有偏数据流,并不是真实的数据。如果模型在这个有偏分布上学习,效果会变差,大多表现为会低估ctr、cvr
Twitter这篇论文比较了LR、Wide&Deep两种模型架构,使用4中不同方式:Delayed feedback loss、Positive-unlabeled loss、Fake negative weighted、Fake negative calibration在解决延迟反馈上的表现
解决方案
1. Delayed feedback loss
这个是Criteo在《Modeling Delayed Feedback in Display Advertising》中提出一种延迟转化转化建模的方案,基本思想是用一个模型建模正样本的回流分布,用这个分布来纠偏主模型。
最终的loss为:
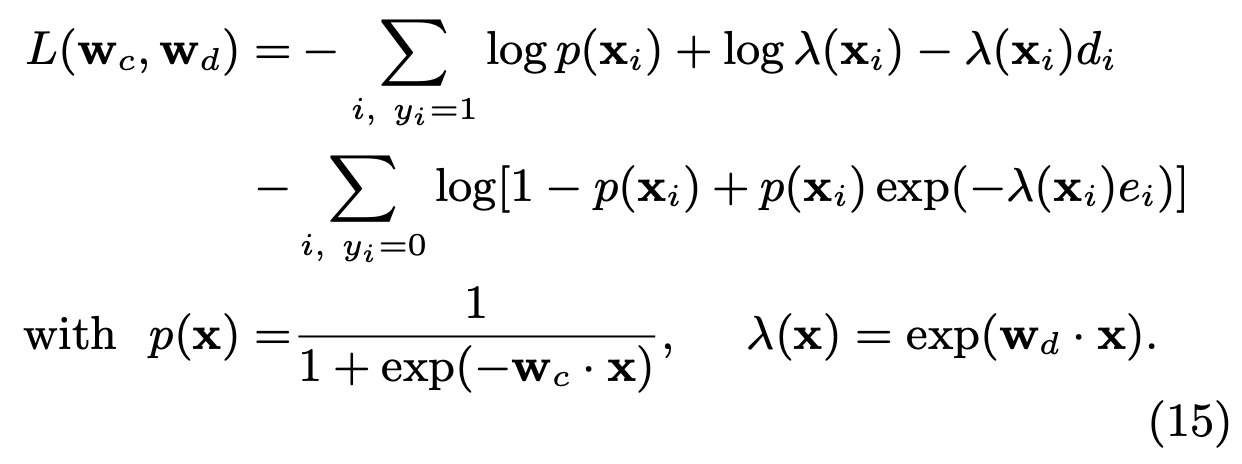
2. Positive-unlabeled loss
PU loss的基本思想是把负样本当作没有label的样本,可以推导出下面的损失函数:
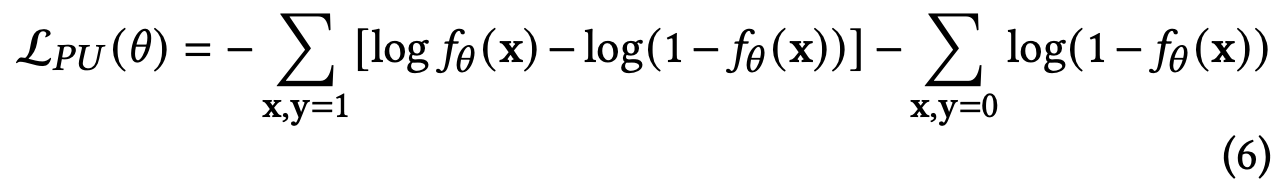
直观上来看,就是在观察到一个实例的正样本到达时,除了使用正样本进行梯度下降,还会对相应的负样本进行一个反向的梯度下降,抵消之前观察到的FN样本对loss的影响
3. Fake negative weighted
待补充
4. Fake negative calibration
当一个样本到来时,首先当作负样本加入到训练流中,如果这个样本后面回传了正反馈,就把这个样本当作正样本加入训练流中。也就是说每个正样本被训练两次(一次是作为负样本,一次是作为正样本),这样导致进入模型的样本是有偏的,所以需要纠偏。
我们假设:
![]()
其中:b 是观察到的数据分布,p 是真实的数据分布
我么可以得出:
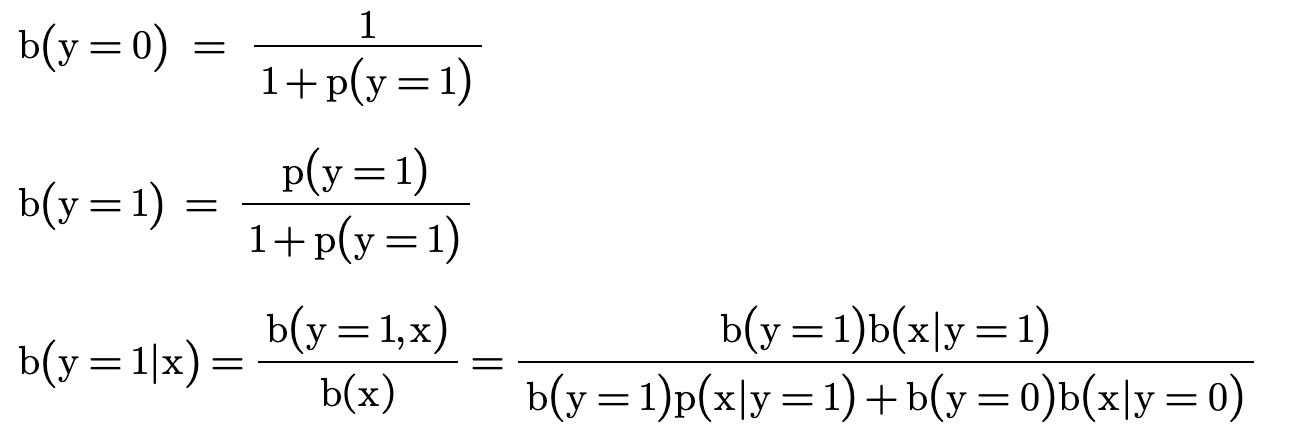
带入上面公式,可以得到:
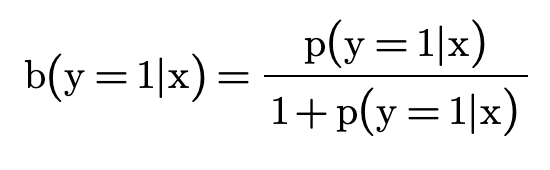
![]()
这里可以采用两种纠偏方式:
1. training时纠偏,即模型预估真实分布p,但是由于label时有偏分布,所以在计算loss时需要纠偏成有偏分布:
2. serving时纠偏,即模型预估有偏分布b,但是serving时纠偏成无偏分布:
![]()
实验结果
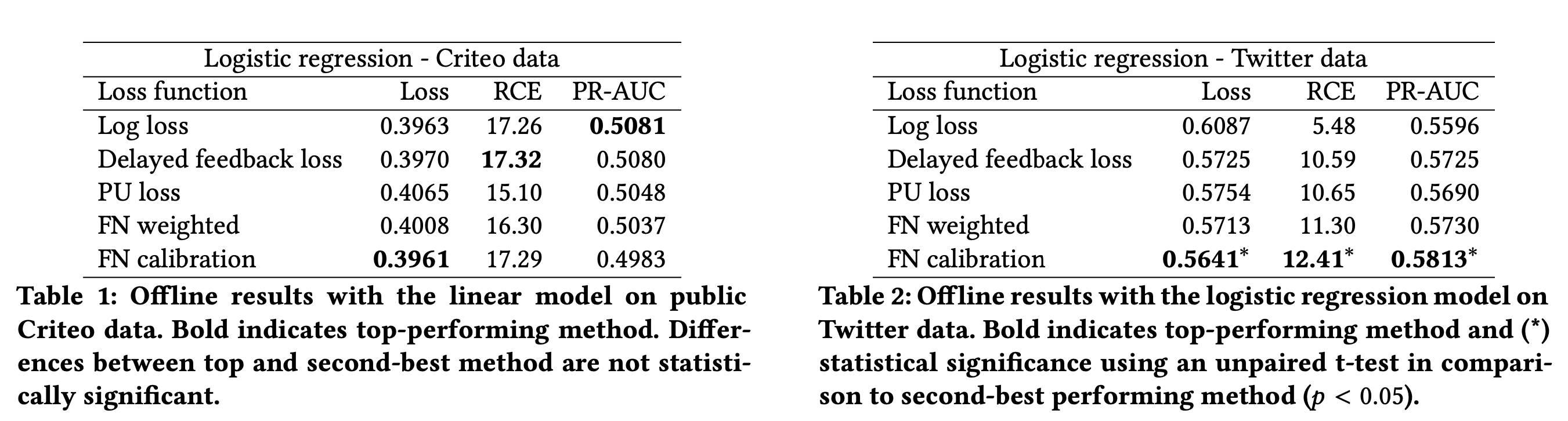
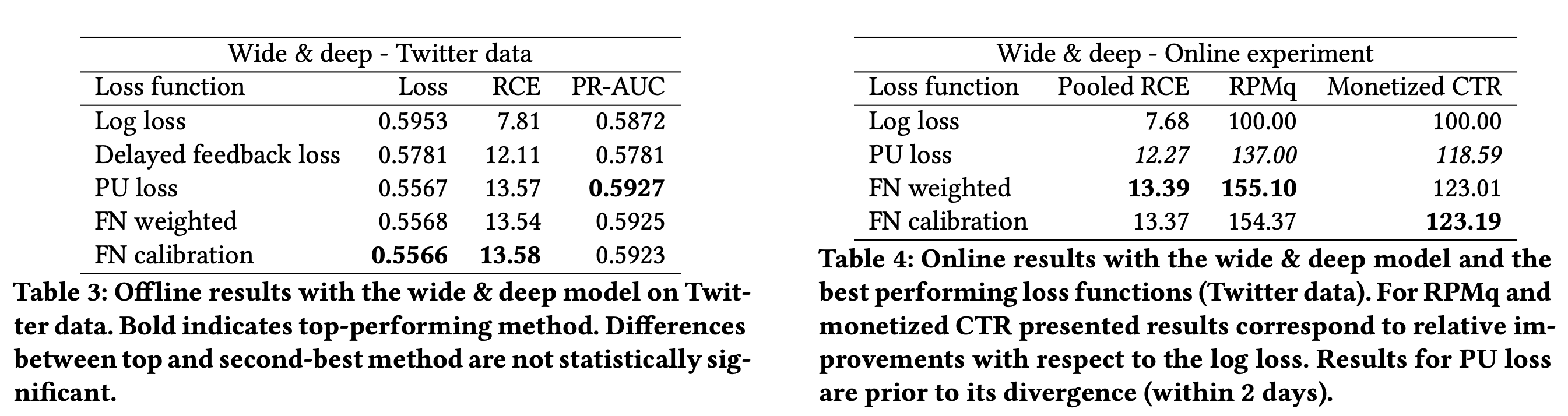
参考资料
https://mp.weixin.qq.com/s/aQOcnWV2L_VY3ChrSXXxWA
https://zhuanlan.zhihu.com/p/554911587

