

快手POSO论文阅读
背景
我们知道,对于冷启动的用户,由于用户行为数据比较少,预估难度较大。常用的解决方案如采用泛化特征代替id类特征、用泛化特征训练一个辅助tower帮助主tower学校、元学习等方案。这些方法把冷启动问题聚焦在用户行为数据的缺失上。POSO论文提出了冷启动中存在的另外两个问题:
1. 冷启动数据量少(快手中占5%),模型容易被非冷用户主导
2. 冷启动用户的行为分布和非冷用户的行为分布存在很大差异
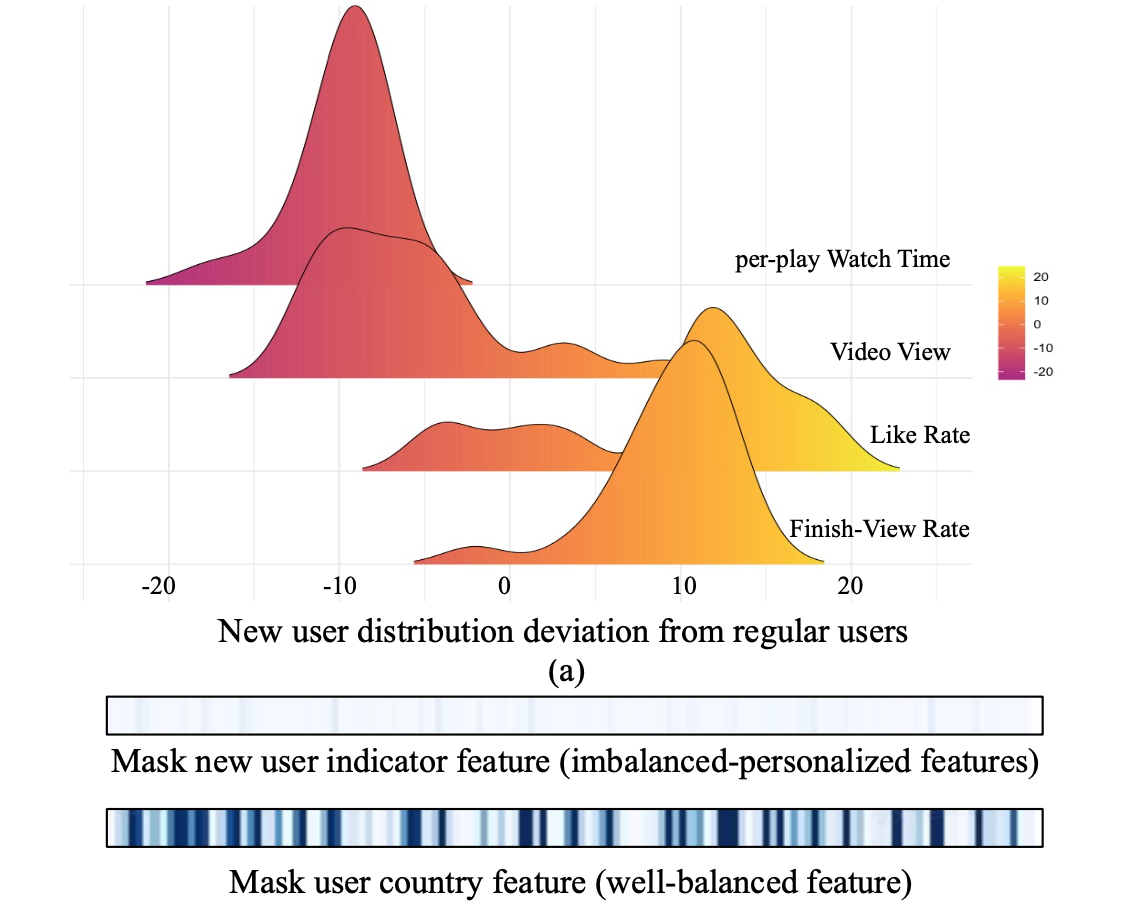
在上图中可视化了新老用户的分布差异,老用户的完播,点赞率,vv和watch time平均后都缩到了原点,然后把新用户的相对差异画出来。很明显,新用户的watch time和vv小,这个好解释,他们还没有行成粘性,大多数就是上来看看随便逛一下。新用户的点赞率会偏高,因为什么东西他都第一次见,新鲜感还在,而老用户相似的东西见的太多,点赞率就下降了。另外,新用户的完播率会偏高,这是快手在机制上做的处理,给他们推了更多的短视频(这涉及到一个产品的问题,为了让用户更快的积累完成感)。
想象中,一个模型想要hold住两种不一样的分布,至少得有一个特征,比如is-new-user来进行区分。模型响应这个特征,依据其不同取值有不同的feature map。但如果论文作者试一下就会发现并非如此:图中上面的部分是某层feature map的可视化,这里分别计算is-new-user=0和=1两种情况做差(累积多个样本),可以发现影响很小,而下图中是将用户所在的国家这个特征改变得到的差别。可以明显看出模型在响应用户所在国家,而几乎忽略了is-new-user,那么is-new-user就无法发挥出上面我们期望的作用了。产生这个现象的原因是冷启动用户的样本占比太低,is-new-user的特征被非冷用户“淹没”了
POSO原理
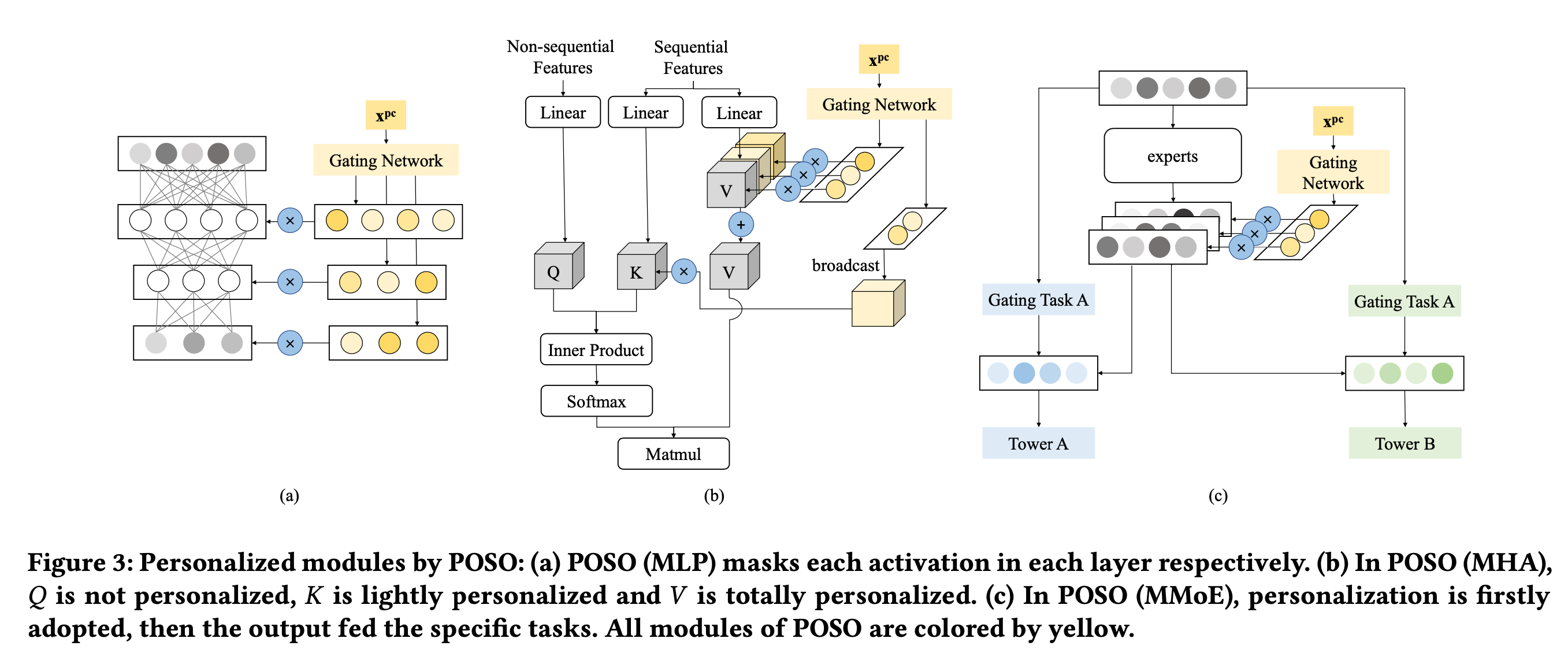
为了解决在模型中冷启动用户被非冷用户淹没的问题,最简单的想法是给每个用户单独训练一个模型,但是这种方法无论是从数据还是算力成本的角度上看都是不可行的。可以借鉴MMOE的思想,训练一组基底模型,每个用户的输出是这组模型的加权和:

那这个想法应用到模型的某一层中,得到:
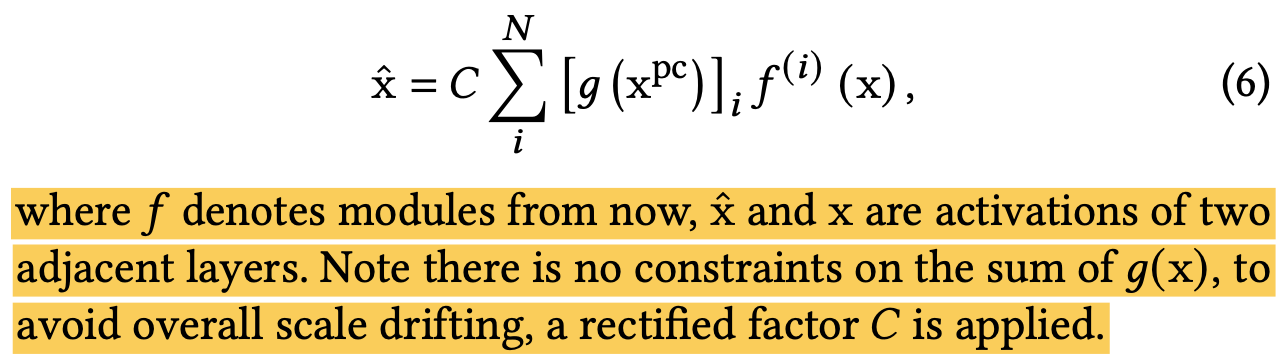
POSO的线性模型版本

POSO的MLP版本
![]()
POSO的 Multi-Head Attention 版本
待补充
POSO的 MMOE 版本
待补充
POSO实践
1. 在实践中C一般设为2
2. 在实践中,embedding层一般采用featurewise(因为embedding层相对于隐层保留了特征的原始信息,featurewise的方式不会改变feature的特征分布,只是对特征加权/降权),非embedding层采用bitwise
思考
1. POSO的MLP版本和LHUC有什么不同?
本质上没有什么不同,都可以看作特定slot在模型作用的加强。但是从原论文上看存在以下几个区别:
1. LHUC倾向于选取bias显著的泛化特征(如age,gender,ea等),poso则倾向于选择如uid,gid这种个性化特征
2. LHUC一般只作用在隐层,POSO主要作用在embedding层
