


用反事实推理缓解数据流行度偏差《Model-Agnostic Counterfactual Reasoning for Eliminating Popularity Bias in RS》
背景
在推荐场景,广泛存在长尾分布的现象,即少量的物品频繁的出现,导致正常训练的推荐模型更倾向于推荐流行物品,从而导致马太效应,即流行的物品被更频繁地推荐,并变得更加流行。目前针对这个问题的去偏算法主要可以分成三类:
(1)逆权重分数:估计物品流行度的倾向性权重,并对每条数据样本利用逆权重分数进行加权。
(2)加入无偏数据:通过从额外的无偏数据中学习来纠正流行度偏差。
(3)分解嵌入表示:将兴趣和流行度分解为两套嵌入模型,并调整使得模型学习到更鲁棒的模式。
这篇论文引入了因果推断的思想来对模型进行纠偏
模型结构
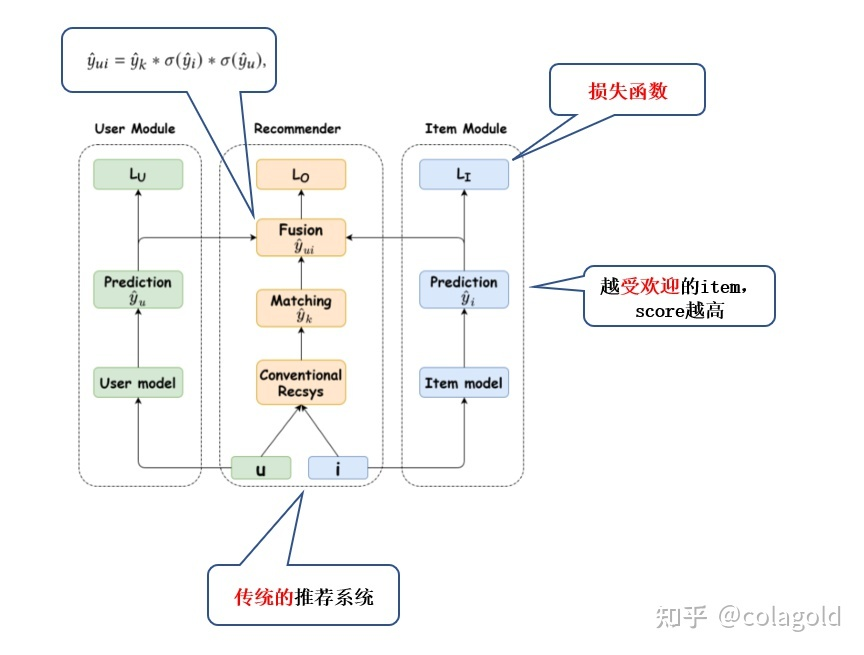
论文提出上图所示的模型结构,模型主要包含3个head:

损失函数
![]()
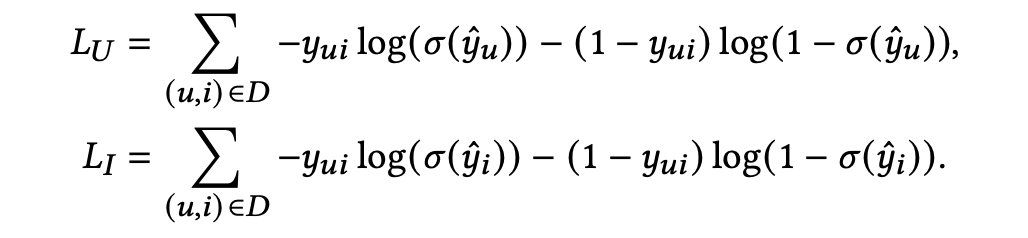
![]()
最终的预测结果

参考资料
https://mp.weixin.qq.com/s/b1DCPuO-yzR4oZpzx3xVfg


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具
2019-11-15 Linux文件目录命名规则
2019-11-15 Linux根文件系统详解