


《CAN: Revisiting Feature Co-Action for Click-Through Rate Prediction》论文阅读
背景
作者发现把预估商品信息(如item_id)和用户用户历史行为序列(如item_id sequence)做笛卡尔积,形成一个新的id suquence, 对其做embedding后pooling效果会在din/dien的基础上有明显的提升。DIN/DIEN等建模方式的特征交叉最终算出了一个weight,是个标量而没有方向,输出的只是对序列embedding的reweight结果,相比笛卡尔积的直接建模P(y|A&B) 能力会弱一些。但笛卡尔积有个严重的问题是这样参数量会急剧增加,并且同个特征和不同特征做交叉时没有任何共享信息,泛化性不强,对于没有出现过的特征组合预估不准。
论文中把和label关系密切的特征组合称为feature co-action,CAN这片论文提出了一种特征交叉方法,这种特征交叉方法不仅可以用与普通特征交叉,而且还可以用与序列特征处理
网络结构
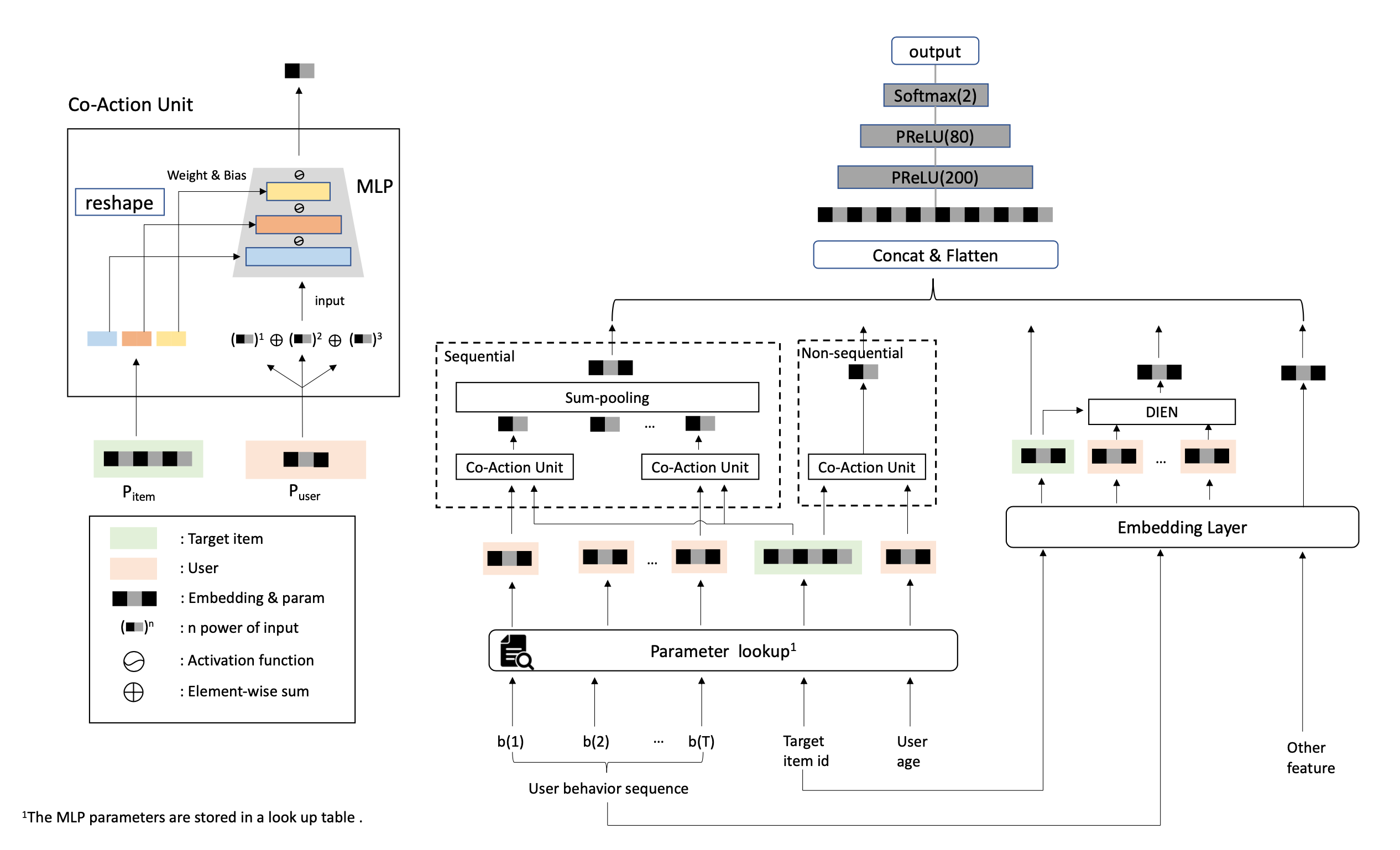
这片论文的网络结构如上图所示,这个网络的右半部分就是一个用DIEN进行序列建模的传统DNN,我们重点关注左半部分,对于一个候选item id,这篇论文不仅用item id特征和use age这种非序列特征交叉,而且还用用于和用户历史行为的序列特征交叉,用于交叉的结构称为Co-Action Unit, Co-Action Unit如上图最左边所示
Co-Action Unit实现特征交叉的步骤可以总结为:
1. 从user侧选取部分特征构成Puser,从item侧选取部分特征构成Pitem,
2. 把Pitem reshape层一个行向量,然后切分成3段,每段都是MLP中的w和b
3. 然后输入Puser到这个MLP中做运算
注意:这里选取item作为MLP参数的原因时因为候选item一般比user或user点击序列item数目少很多
理解:相当于FM -> FFM
实验
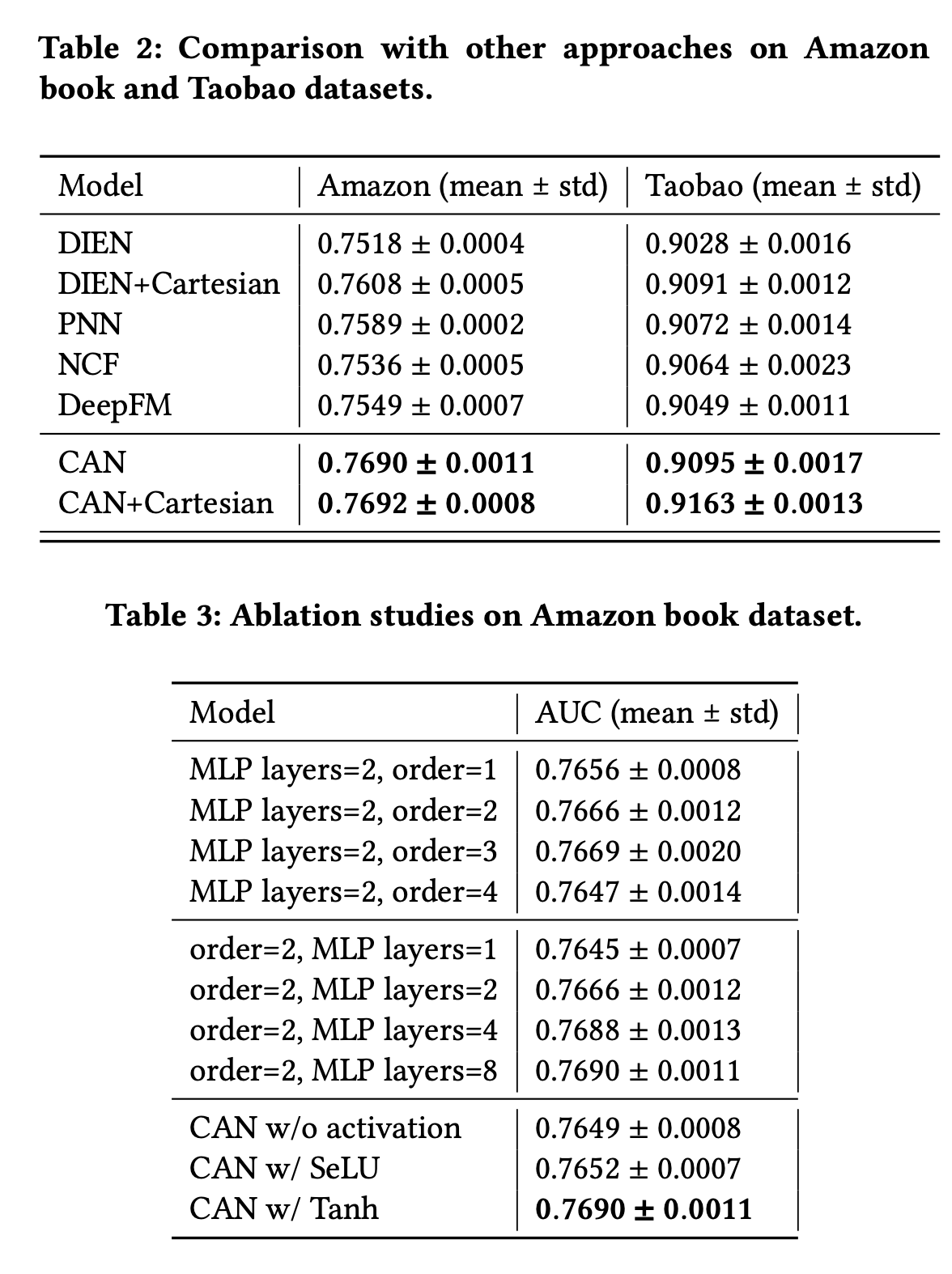
作者以DIEN模型为基线,对比了DIEN加CAN的结果,还通过消融实验分析了CAN输入user特征阶数、CAN MLP层数、CAN MLP激活函数对实验结果的影响
实践经验
非序列特征交叉
- 按特性重要性选取top k特征作为CAN MLP的参数(可以把这些特征的emb concat后过一个MLP得到想要的维度)
- 所有特征emb和这个CAN做运算后再进NN
序列特征交叉
