

《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》论文阅读
背景
这篇论文是YouTube在《Deep Neural Networks for YouTube Recommendations》这篇论文后提出的一个在推荐系统的召回阶段的研究,应用场景类似猜你下个可能观看的视频
论文中的网络采用现在业内非常常用的双塔结构,这篇论文的主要创新点在负样本的采样和损失函数的构造上。论文把召回当作极端多分类问题。也就是把用户当前观看的item当作正例,视频库里所有其它item当作负例,用softmax函数来计算。
这样引来了两个问题:
1. 视频库中的视频数目是不断变化的
2. 视频库中的视频数目非常巨大,造成训练缓慢
这两个问题可以通过in batch负例来解决,也就是在同个batch中随机采用固定数目的item作为负例,但是随机采用会容易采样到热门item,这样会造成对热门item的打压,这片论文的创新点就是在流式训练时会预估每个item的采样频率
模型结构
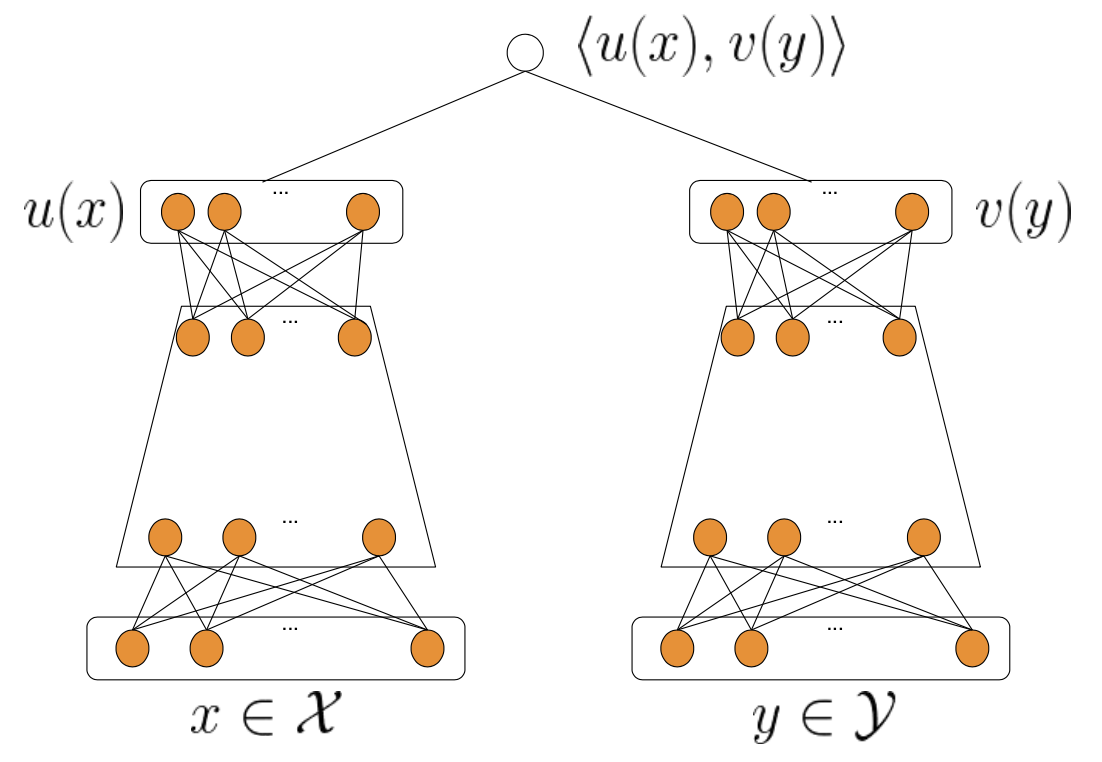
这篇论文采用了双塔模型,左塔学习user的embedding,右塔学习item的embedding,最后通过计算这两个embedding的内积得到user和item的相似度:
![]()
论文中还提到了两个小trick:
1. 对embedding进行normalization后再计算相似度,论文中提到这样提高训练时的稳定性
![]()
![]()
2. 加一个温度参数去控制相似度的最大值,论文中提到这样可以最大化准确率和召回率
![]()
Loss和训练
论文中用如下式子表示训练中的一个样本,x表示query(user相关信息),y表示item,r表示反馈(如观看时长)
![]()
论文把召回看作连续反馈下的多分类问题,对于一个query(request),用softmax函数来计算每个item被选择的概率
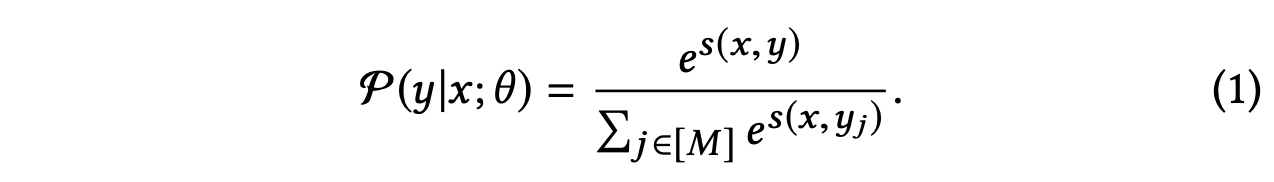
结合反馈 ri 可以用加权对数似然函数来计算loss:

全量的视频库是非常大的,很难训练,论文采用来in-batch negatives,也就是把同个batch里的其它样本作为负例
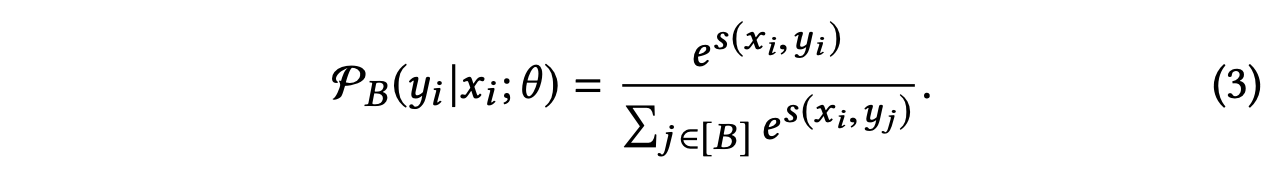
但是,这样存在一个问题,那就是item的分布是一个power-law distribution,这样会导致约热门的item越容易被采样为负例,会造成对热门item的打压。为解决这个问题,论文中会有一个任务预估每个item被采样为负例的概率,并且用这个概率去纠正原来的loss

估计item被采样为负例的算法如下所示:

h是hash函数,帮item哈希成一个整数
t是当前step数,数组A记录每个item最近一次出现的step数,数组B记录同个item出现两次的step间隔的滑动平均值
完整模型架构

YouTube把这个召回系统应用在类似猜你喜欢的场景中,用户在观看一个视频的时候,会为他推荐候选视频。论文把用户点击的视频作为正例,r表示观看时长

 浙公网安备 33010602011771号
浙公网安备 33010602011771号