


对比学习《Self-supervised Learning for Large-scale Item Recommendations》
背景
在推荐系统中存在用户行为稀疏的问题,特别是在召回阶段,用户有过交互的item只占非常少的一部分,只有这部分数据我们能用来训练,但是serving时要serving全库item,这可能会导致倾向热门的item,特别是对冷启动非常不友好。这篇论文引入来在CV、NLU中取得成功的对比学习方法,通过一个辅助任务来帮助主任务模型和底层embedding得到更充分的训练。
模型结构
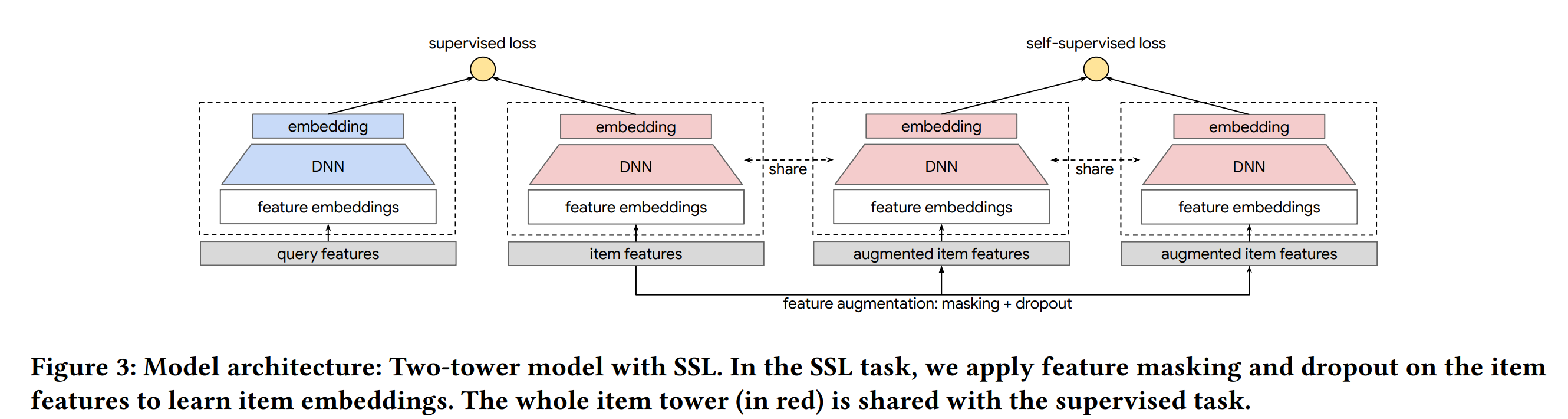
模型结构如上图所示,在主任务的基础上增加一个辅助任务,两个任务共享底层的embedding(也可以共享nn参数),两个任务联合训练

辅助的任务的作用是在对样本进行变换后,辅助tower仍能区分出是不是同个样本,这样可以避免样本被少数强特征主导,是特征能学习的更充分。
正负样本构造方法
正样本:同个样本经过不同变换得到的两个样本构成正例
负样本:在batch内的其它样本经过变换后
样本变换方法
样本变换分位两个步骤:
- 首先是mask一部分特征,有两种mask方法:
- 随机mask一般feature得到样本1,然后mask另一半feature得到样本2(这两个样本会构成一个训练pair)
- 首先随机选择一个种子特征(如id特征),然后选择和这个种子特征互信息最大的一半特征mask后得到样本1,mask另一半特征得到样本2
- 是进NN前通过一个dropout层,在特征粒度drop掉部分特征(论文提到dropout只对多值类别特征做)
损失函数

这个loss鼓励:
1. 同个样本经过不同的变换后,经过神经网络后得到的embedding有最大的余弦相似度
2. 不同样本经过不同的变换后,经过神经网络后得到的embedding有最小的余弦相似度
数据流
1. 直接用主模型的数据流
主模型的数据流一般用的是进精排的item构造的数据流,存在select bias,即高热item的样本占比过高
2. 构造unbias数据流
实践经验
广告召回ltr模型,广告侧tower构造对比损失,让长尾广告能得到更充分的学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏