

《Deep Neural Networks for YouTube Recommendations》论文阅读
背景
google 在这篇论文中介绍了在 YouTube 中使用两阶段推荐系统(召回和排序)
召回:和协同过滤原理相似,根据不同用户的历史行为召回用户可能感兴趣的视频
排序:根据用户对视频可能的观看时间对候选视频进行排序,最大化YouTube的商业化价值
和其它论文不同,这篇论文不是在介绍某个技术点上的创新,而是在分享搭建一个工业级推荐系统的经验
YouTube 推荐系统中主要面临的 3 个挑战:
1. 规模问题,YouTube 的用户规模和视频规模是非常庞大的,如何在大规模场景下搭建一个低延迟的推荐系统是非常有挑战性的
2. 新鲜度问题,YouTube 每秒都有新视频被上传到网站中,推荐系统要能对性视频的交互足够敏感,要能平衡 exploration/exploitation
3. 噪音问题,用户有过交互的视频是非常稀疏的,而且还存在一些我们无法观察到的数据,我们很难获得用户真实的喜好
我们后面在逐条看一下这篇论文是如何解决这个问题的
YouTube 推荐系统由召回和推荐两个网络构成,完整的推荐架构如下图所示:
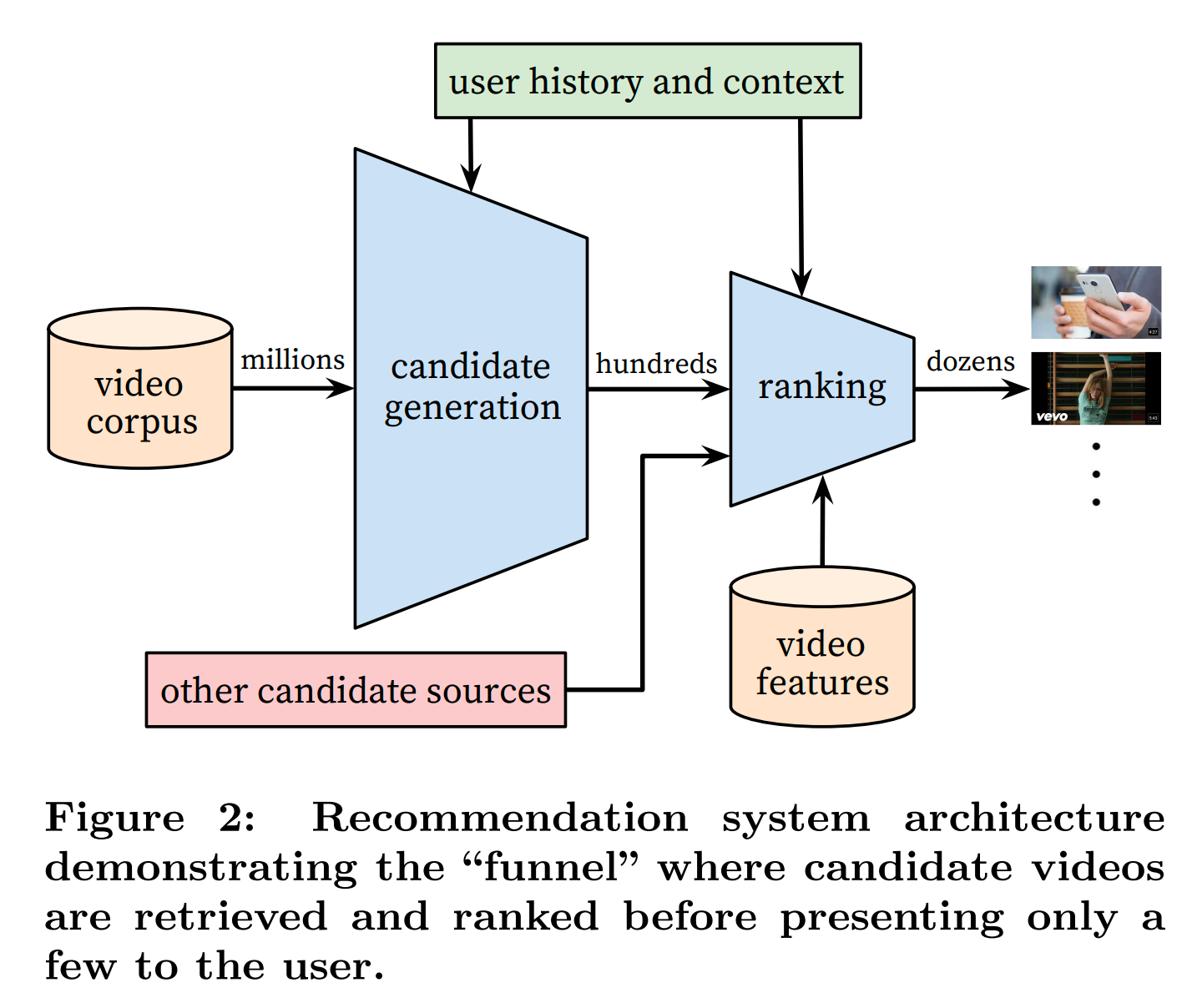
召回网络
召回网路的结构如下图所示:
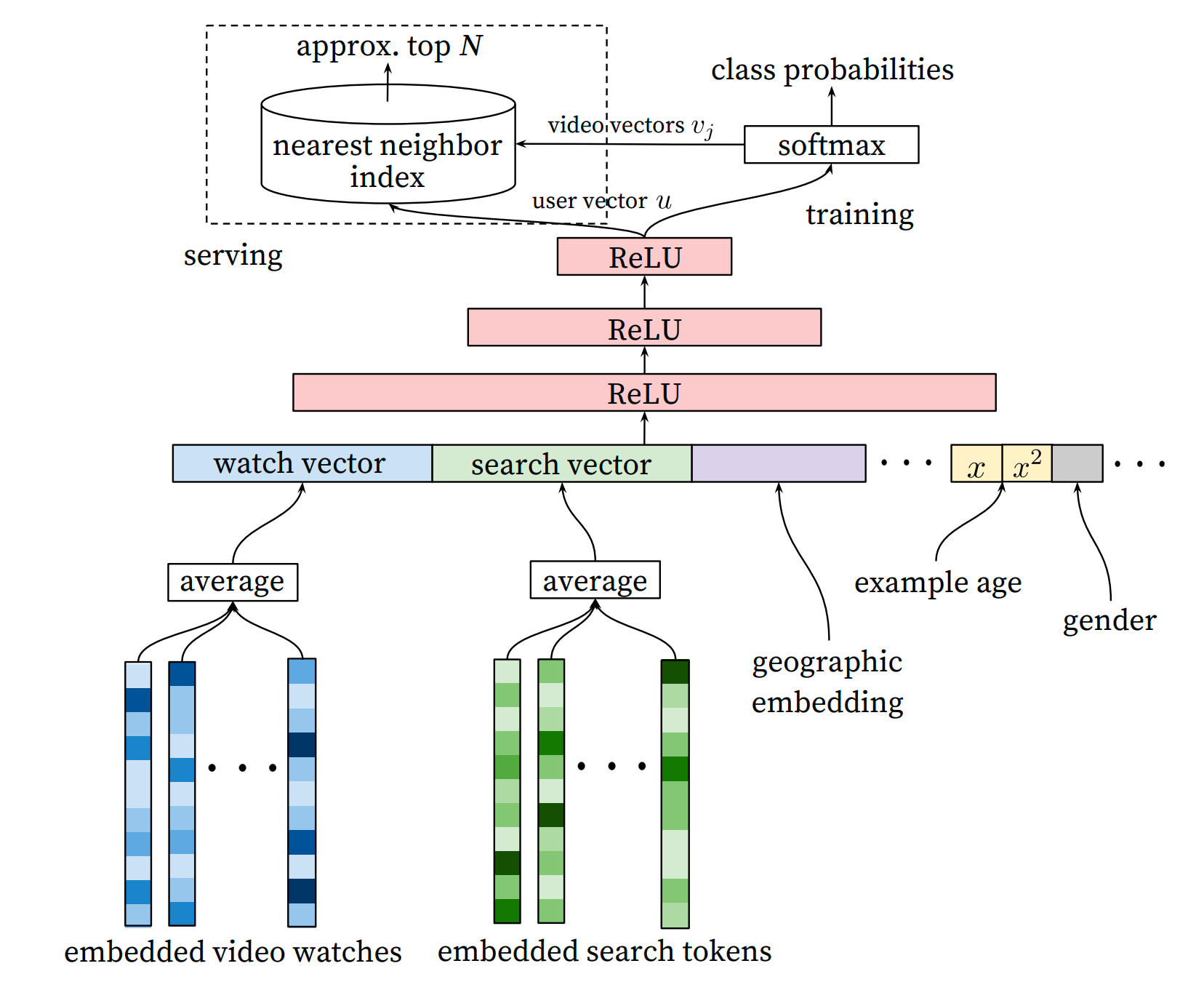
在这里,YouTube把召回建模成一个极端多分类问题(视频库中的每个视频都看成一类),具体的来说,就是在当前时刻,给定用户信息和用户历史行为信息,预测接下来用户会看哪一个视频的概率,很自然的我们会想到用softmax函数来建模:

这里有两个地方容易让人迷惑:
1. 公式中的用户向量 u 和 每个视频对应的视频向量 vi 是怎么得到的?
其实 u 就是 nn+softmax 层的前一层的输出结果,假设该层的维度为 n,视频数目为 m,那么这两个层之间的权重维度就是 n * m,第 i 个视频的 embedding 其实就是这个权重矩阵第 i 列向量
2. 在softmax其实只在training的时候用到,在serving的时候为什么要用最近邻检索?
用一些最近邻或近似检索算法可以加快检索效率
3. softmax 分类数目固定的,但是Youtube视频数目是不断变化的,这个怎么解决的?
直接训练所有视频类别的softmax是非常低效的,论文中采用负例采样的方法去训练该模型:

在这里仔细分析一些召回网络输入的特征:
1. embedding video watches
embedding video watches 是用户历史观看的视频对应的 embedding,最后会把这些embedding求average输入到图中。
那么如何得到这些视频对应的embedding?
最直接的方法就是不加任何先验,在召回网络中直接训练这些embedding
论文中提到了他们采用了类似word2vec方法训练得到这些视频对应的embedding,并且这些embedding也是会在召回网络上得到更新的

2. embedding search tokens
用户的检索历史处理方法和视频观看历史处理方法相似

3. geographic embedding
这个特征就给用户的设备、地理位置等信息,还有用户其它的如年龄、性别、登录状态等信息也被输入到网络中

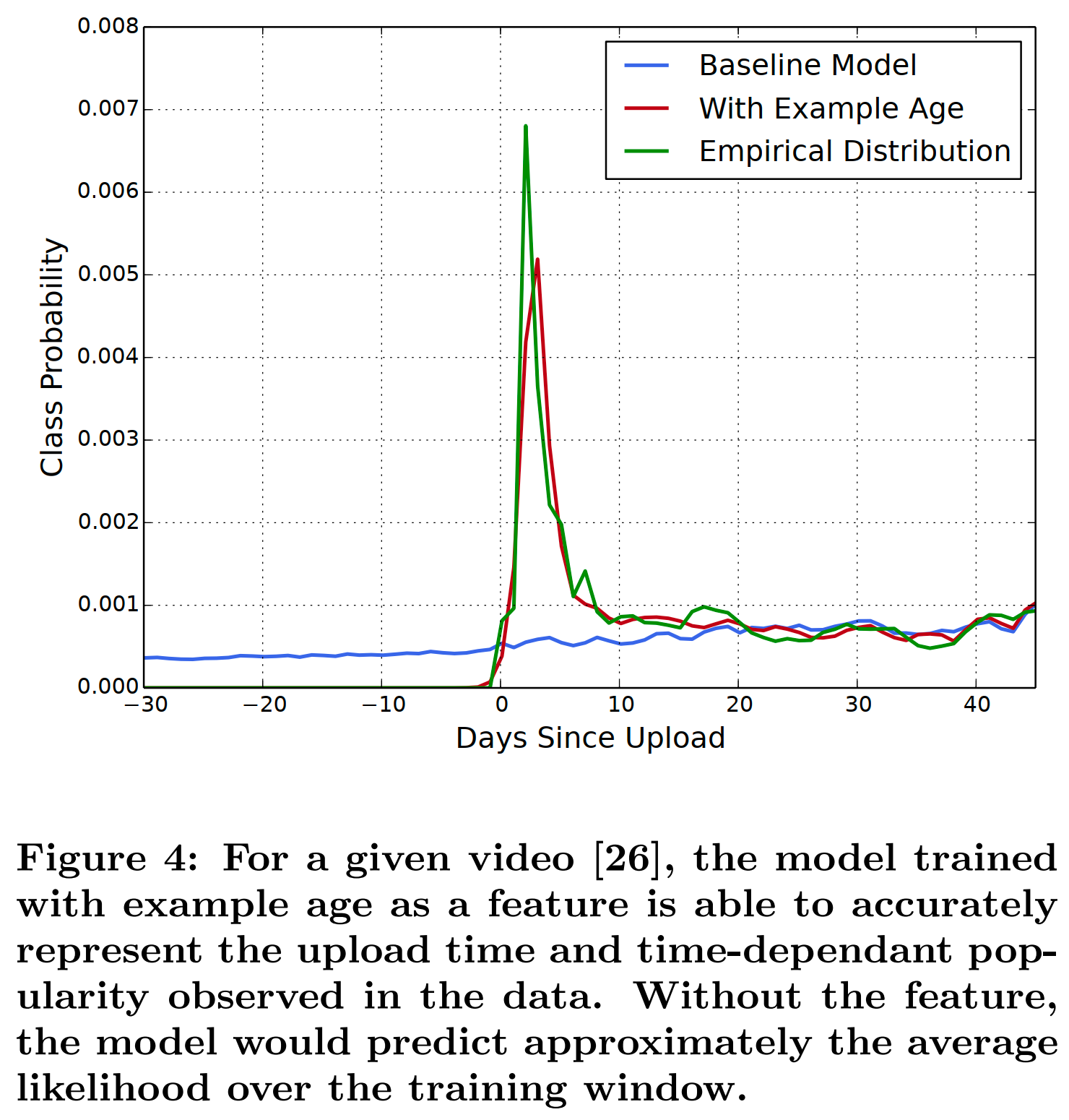
4. example age
这个特征就是每条样本的生成时间(在训练的时候这个值应该是样本生成时间和训练时刻的时间差?),在serveing的时候,这个特征被设为0
因为推荐系统其实是对未来的一个预测,所以需要感知样本分布随时间的变化
作者在论文在还分析了这个特征的影响:
样本和label的构造
为了防止模型被少数活跃用户主导,所以对每个用户构造了相同的样本,具体怎么实现的呢?
论文还提到了 surrogate problem
排序网络
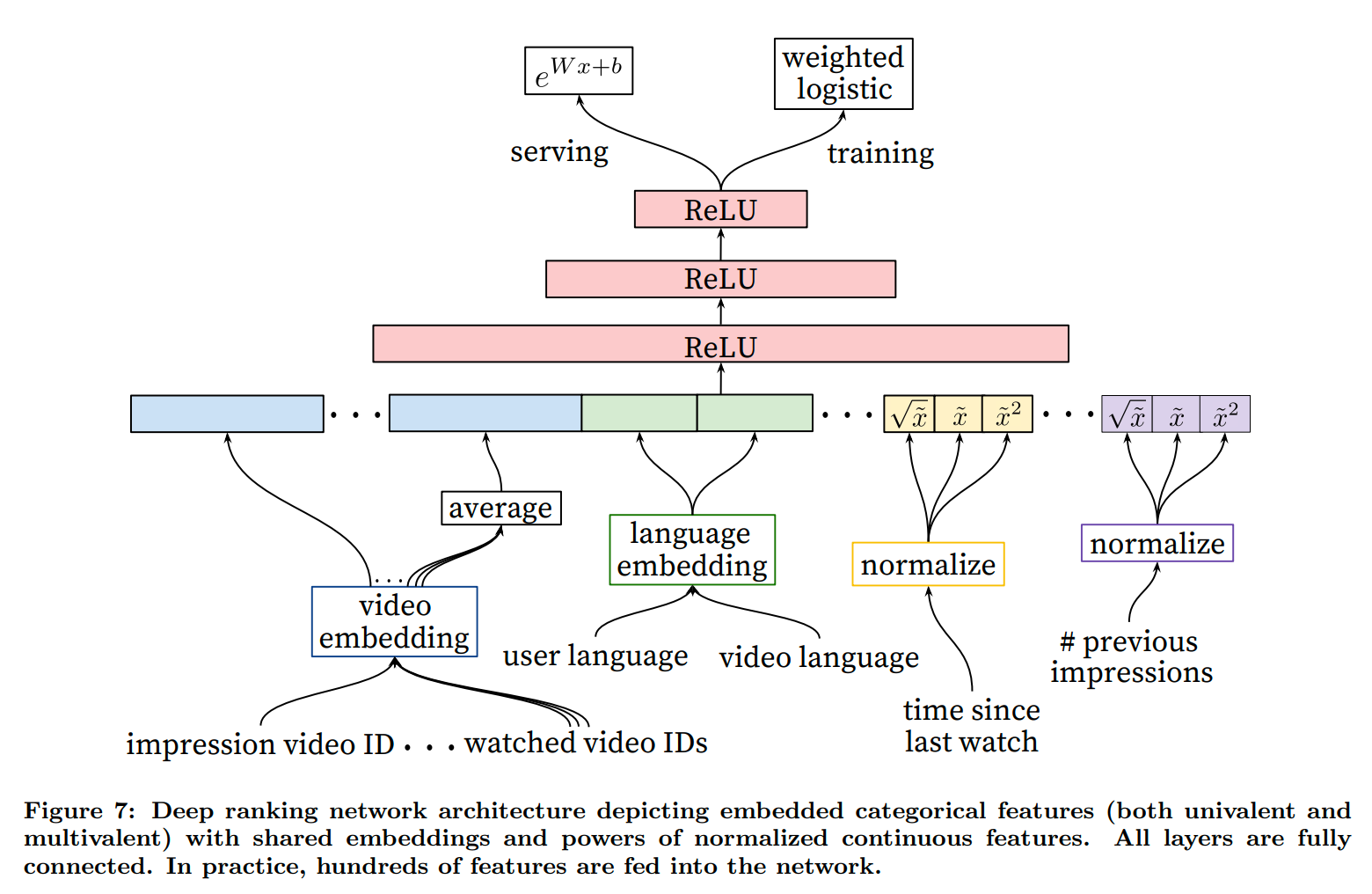
排序网络预测的是用户对候选视频的光看时常,用了weighted LR来计算,具体细节可以看https://www.cnblogs.com/xumaomao/p/15207305.html

