


Weighted LR (WCE Weighted cross entropy)
在推荐系统中,我们常常需要用用户的观看时长作为目标来进行建模,那么如何训练一个模型来预估模型的用户的播放时长呢?
很容易想到把播放时长的预估问题作为一个回归问题,采用mse loss,但是mse loss存在两个问题:
- 分布假设:假设是预估label、误差项符合正态分布
- 预估局限:对离群值敏感
Youtube在经典论文 (Deep Neural Networks for YouTube Recommendations) 提出了WCE损失函数,巧妙的用一个分类任务来预测播放时长
我们知道LR的对数几率可以表示为:
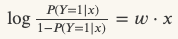
正好就是模型过sigmoid函数之前的值,Youtube在论文中中指出可以把正样本的label置为ti(观看时长),负样本的label为0,这样损失函数可以写为:
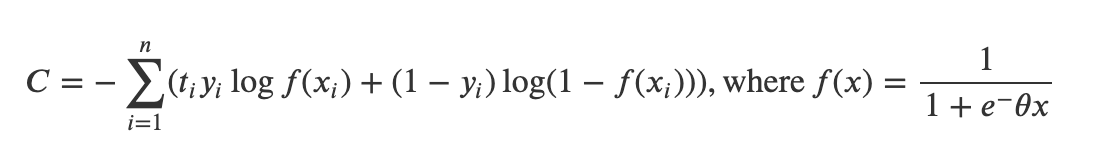
做如下推导:
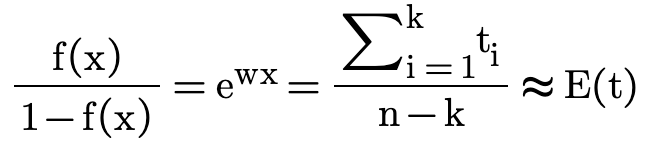
其中n是正样本的数目,k是负样本的数目,得出可以用ewx来表示预估的观看时长
可以为每一个正例增加一个负例来解决近似的问题,用y表示时长,loss变为:
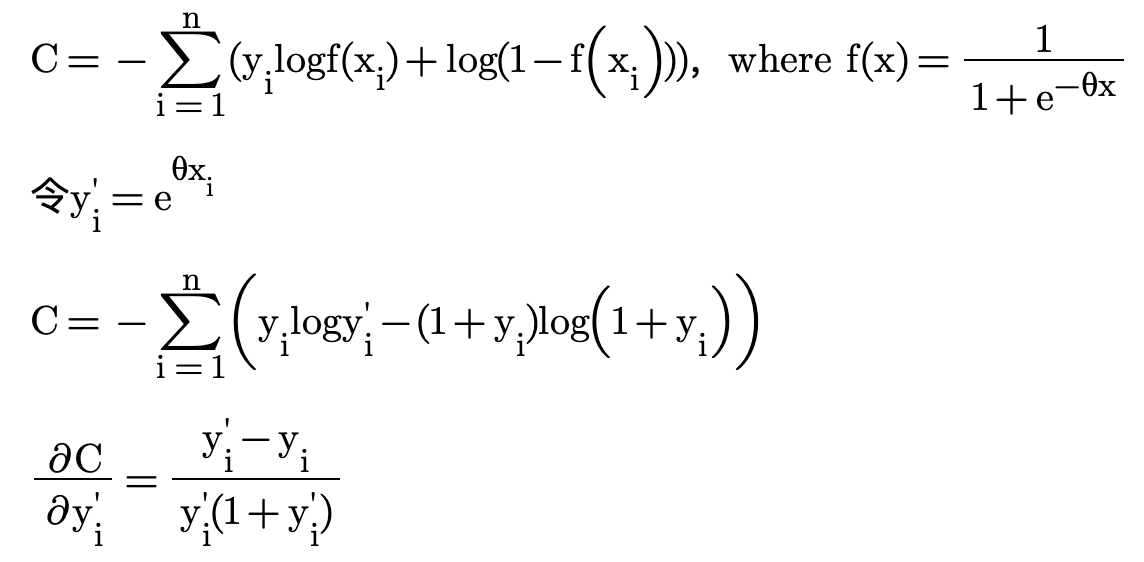
可以得出wce loss在低估(y'<y)和高估(y'>y)时梯度不是对称的,低估时梯度很大,高估时梯度很小,很容易导致模型高估
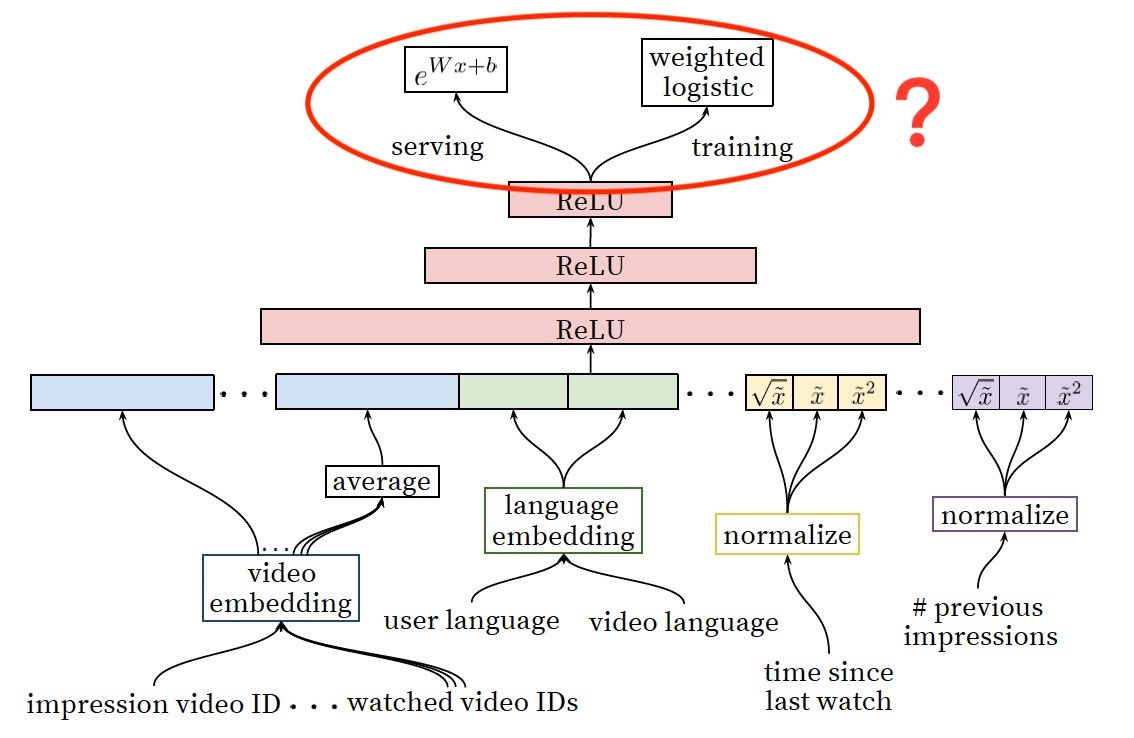
可以看到,训练时,还是当成一个二分类问题来训练就可以了
serving时,计算ewx就是观看时常的预估值,完美的把一个回归任务转换成了一个分类任务
训练Weighted LR一般来说有两种办法:
- 将正样本按照weight做重复sampling,然后输入模型进行训练;
- 在训练的梯度下降过程中,通过改变梯度的weight来得到Weighted LR。
WCE其实假设了样本分布服从几何分布,如果样本分布不是几何分布,可能导致效果不好
参考资料
https://zhuanlan.zhihu.com/p/61827629
https://www.cnblogs.com/hellojamest/p/11871108.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏