

决策树分裂时的特征选择
分类任务
1. 信息增益

信息增益直观理解:在选定特征对数据进行划分后,数据分布不确定性减少的程度,信息增益越大的特征越好。
信息增益的缺点
信息增益倾向于选择类别数较多的特征
这怎么解释呢?从信息增益的计算公式可以看出,不管是选择什么特征,H(D) 项表述的是原数据分布的熵,是一样的,那我们只需要分析 H(D|A) 这一项就可以了,特征类别越多, H(D|A) 会越小吗?

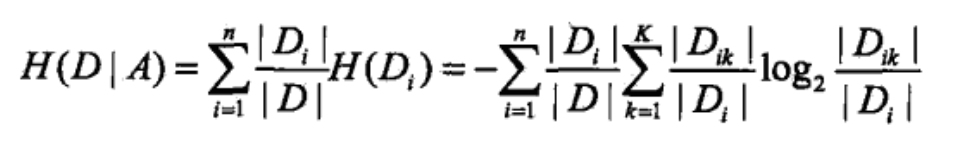
假设总样本数目为100, A1 特征有2个类别, A2 特征有10个类别,并且每个类别内的数据都是01均匀分布,那么:
H(D|A1) = 1/2 * (H(D, A1=1) + H(D, A1=2))
H(D|A2) = 1/10 * (H(D, A2=1) + H(D, A2=2) + ... + H(D, A2=10))
可以看出,如果落到每个特征类别上的分布一样的话,这两种特征的条件墒是一样的。
但如果是极端情况,特征多的类别,每个类别只有一个样本,那么其条件墒是0 (墒是大于等于0的数),最小。
在现实中,我们的样本数量往往是有限的,类别越多的特征,分到每个特征类别下的样本会越少,那么出现样本类别不平衡的可能性越大,即条件墒越少,信息增益越大
2. 信息增益率
特征 A 对训练数据集 D 的 信息增益比:
gR(D, A) = g(D, A) / HA(D)
其中HA(D)是把特征 A 当作随机变量来计算的熵,而特征类别越多,熵往往越大。
举个例子:
只有一个类别的特征,熵为0
有n个类别,且是均匀分布的特征的熵是:log(n),是一个单调递增的函数。
因此,用信息增益比来作为选择特征的标准,可以弥补信息增益倾向于选择多类别特征的缺点。
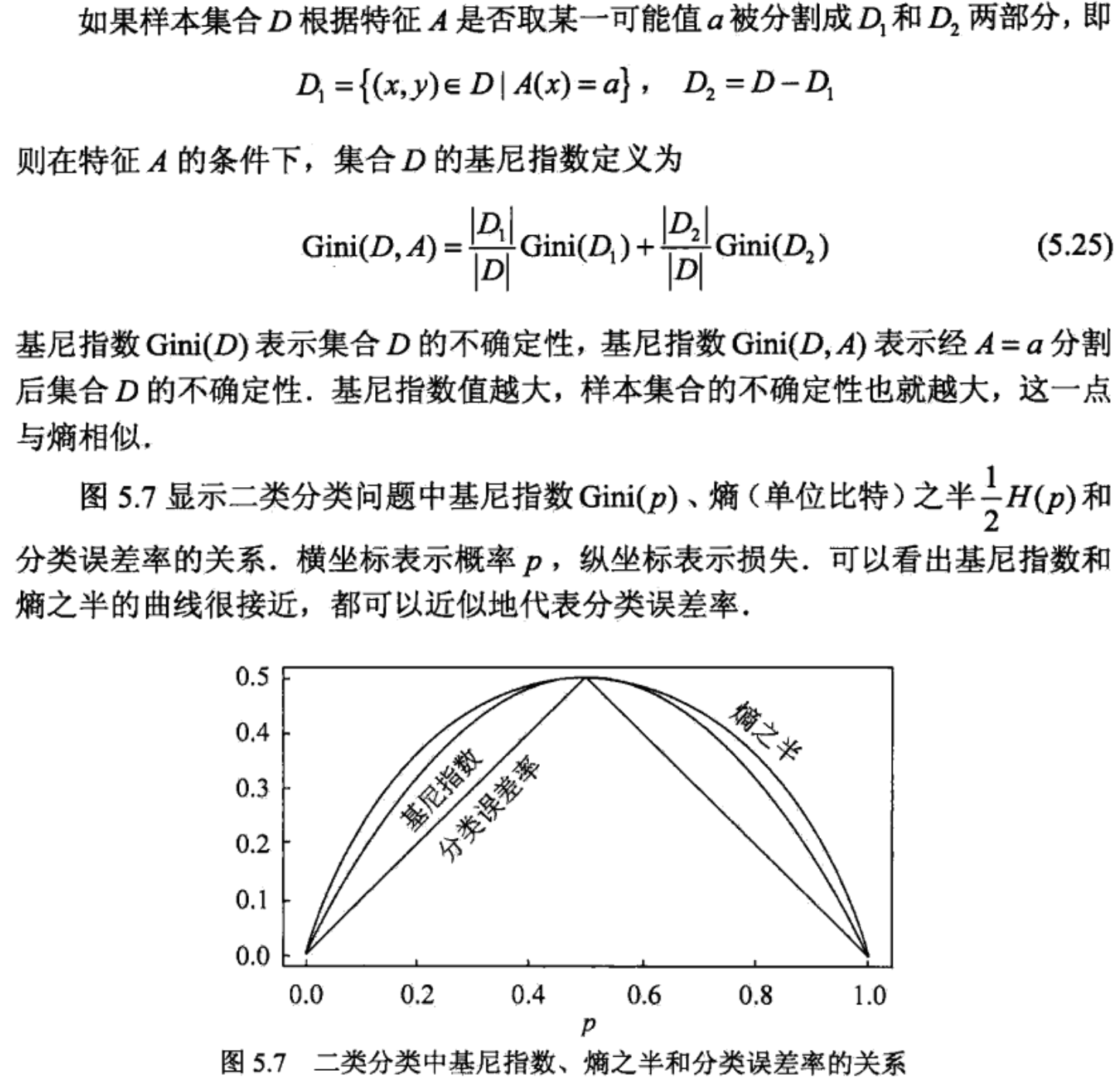
3. 用基尼系数替代熵
我们知道熵中有复杂的对数运算,用基尼系数代替熵可以加快运算效率
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
注意: Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。
即 基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率

回归任务
均方误差最小化
