

ESMM
背景
传统的cvr模型是在click样本上训练的,但是inference是在所有样本上做,这可能会导致样本选择偏差。(据我理解,这个样本上的偏差是不可能完全消除的,因为无论是ctr、cvr模型,都是在send之后的样本上训练的,但是inference的时候是不知道这个样本会不会被send的)
模型结构
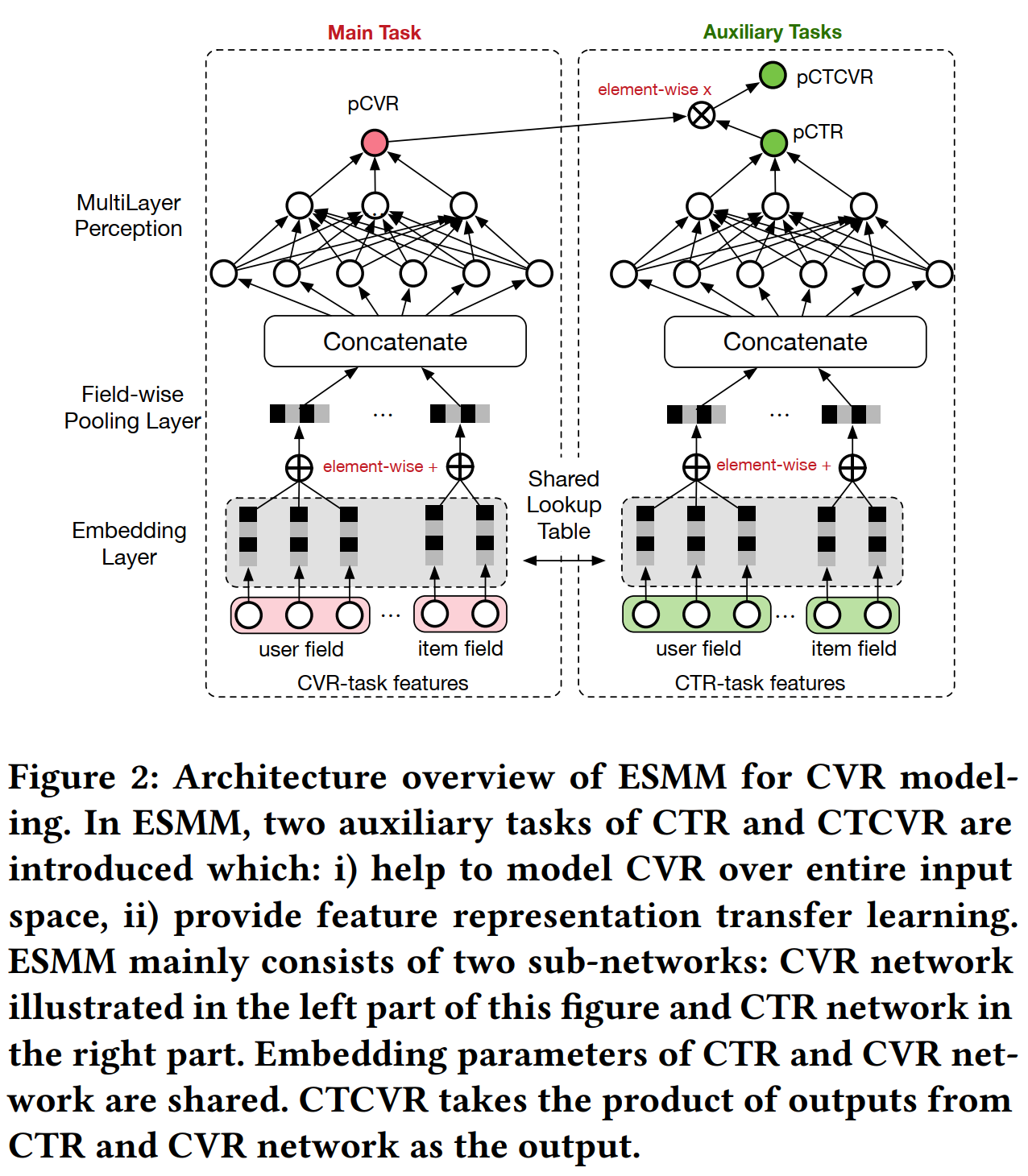
损失函数

计算loss的时候只计算了pCTR和pCTCVR的loss,pCVR是根据这个两个值训练出来的:

主要优点就是通过共享embedding参数,在训练pCVR时,用上了全部的样本。
总结
传统cvr模型的缺点
传统的cvr模型是在所有发生了click的样本上训练的,但是预测的时候是所有的样本都要预测的,也就是说训练样本和预测样本是有偏差的,这样可能导致效果有损。
ESMM的优点
ESMM没有直接去预测cvr,而是预测了ctr和ctcvr,cvr = ctcvr / ctr,利用概率公式间接算出来。由于ctr tower 和 cvr tower 共享 embedding 参数,cvr tower 获得了所有send or show 样本的信息,可以达到更好的训练效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号