MapReduce深入
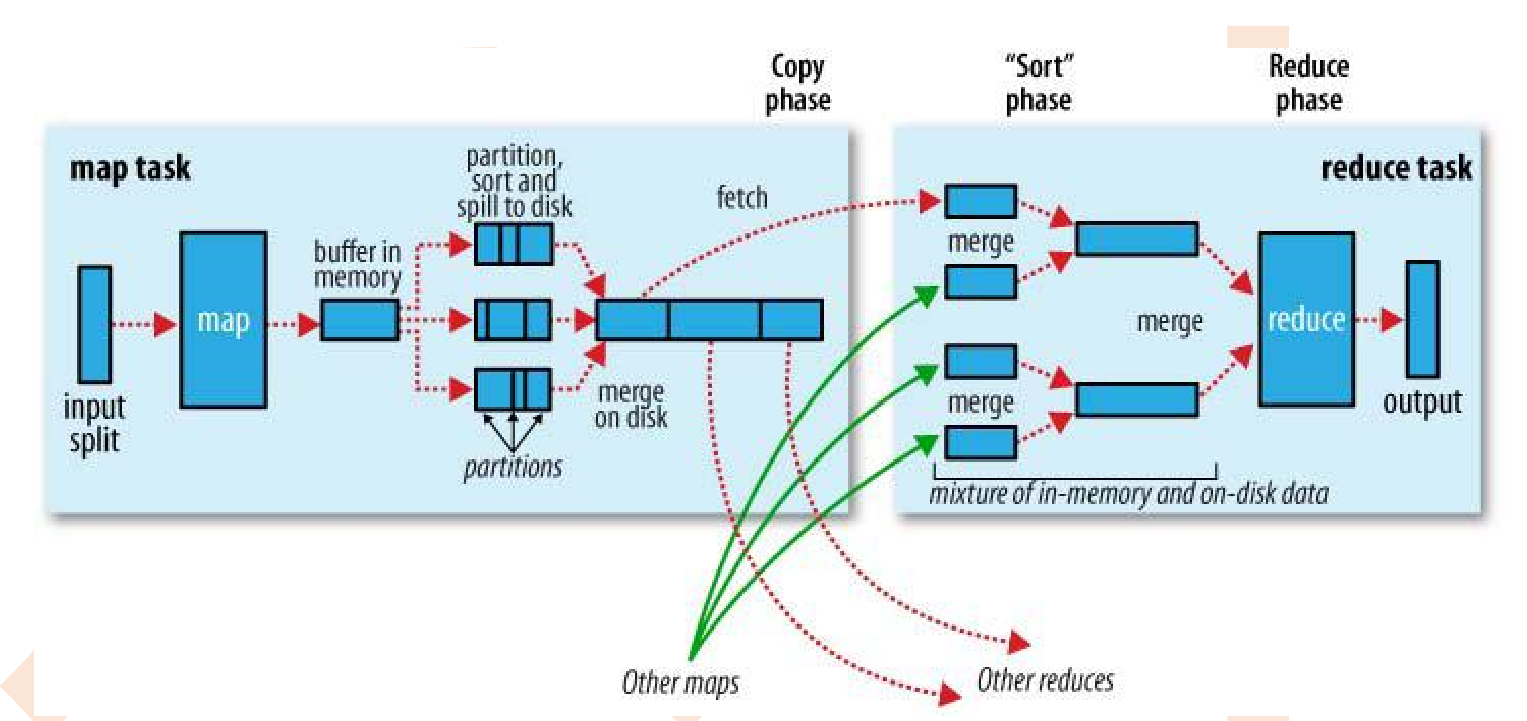
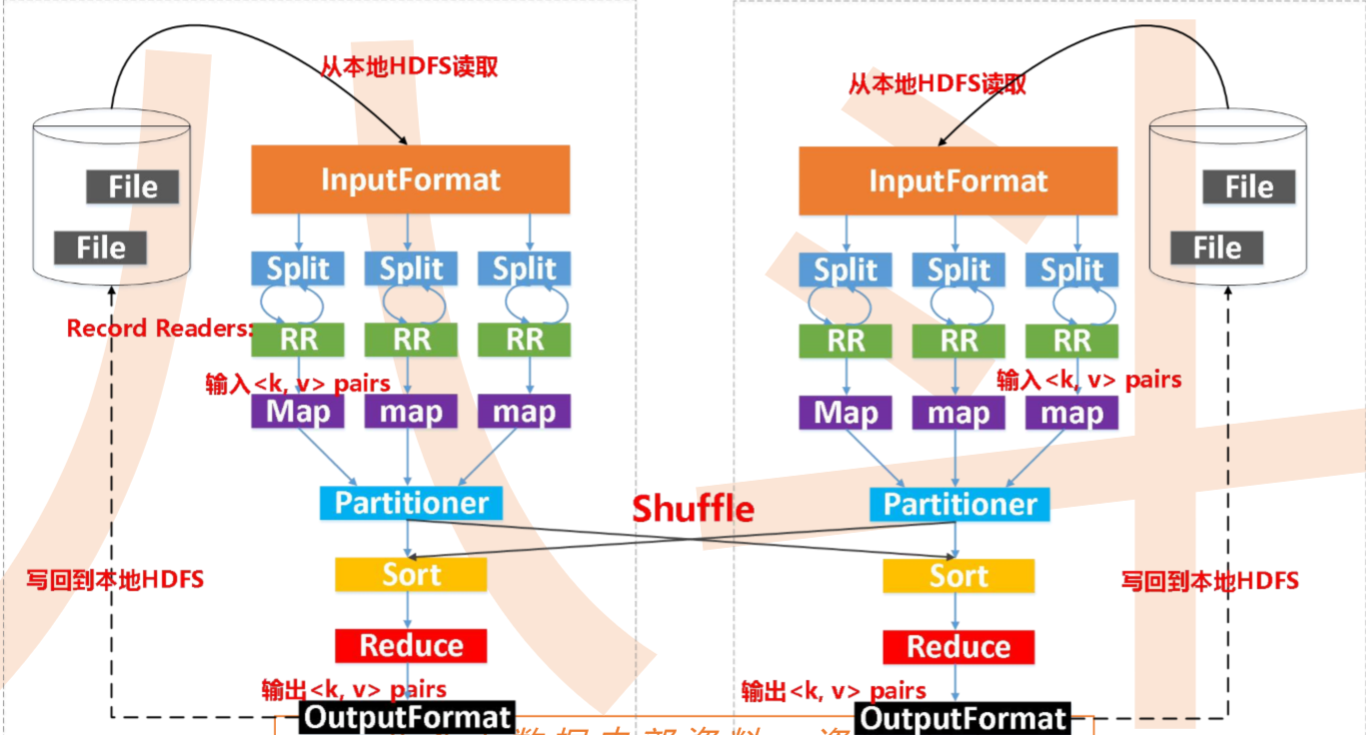
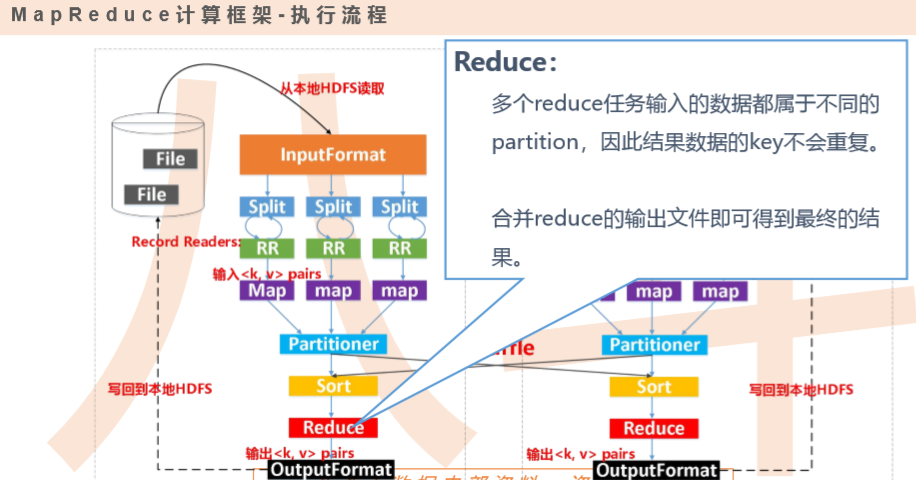
hadoop中map和reduce都是进程(spark中是线程),map和reduce可以部署在同一个机器上也可以部署在不同机器上。
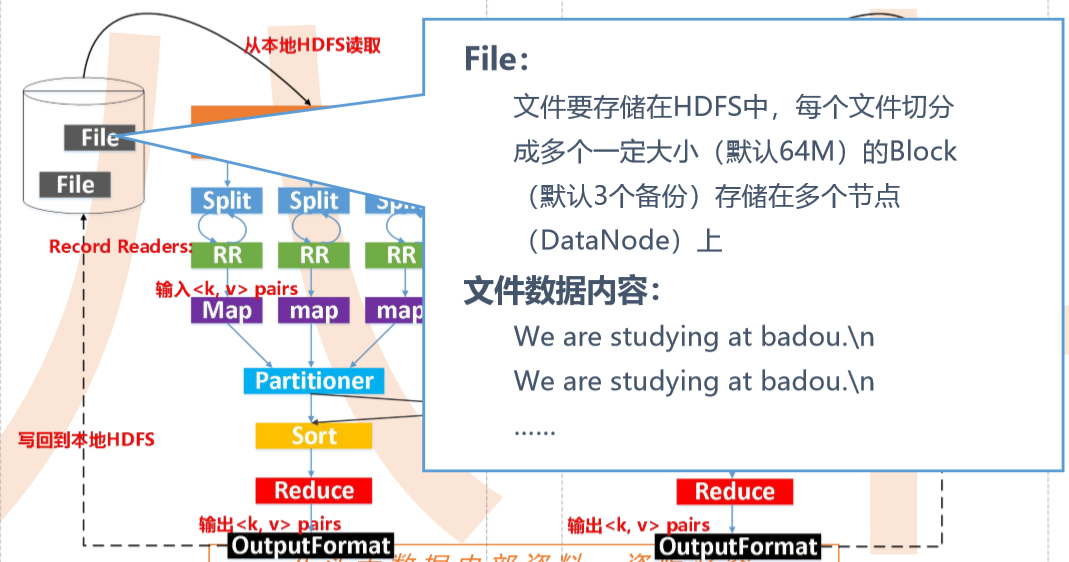
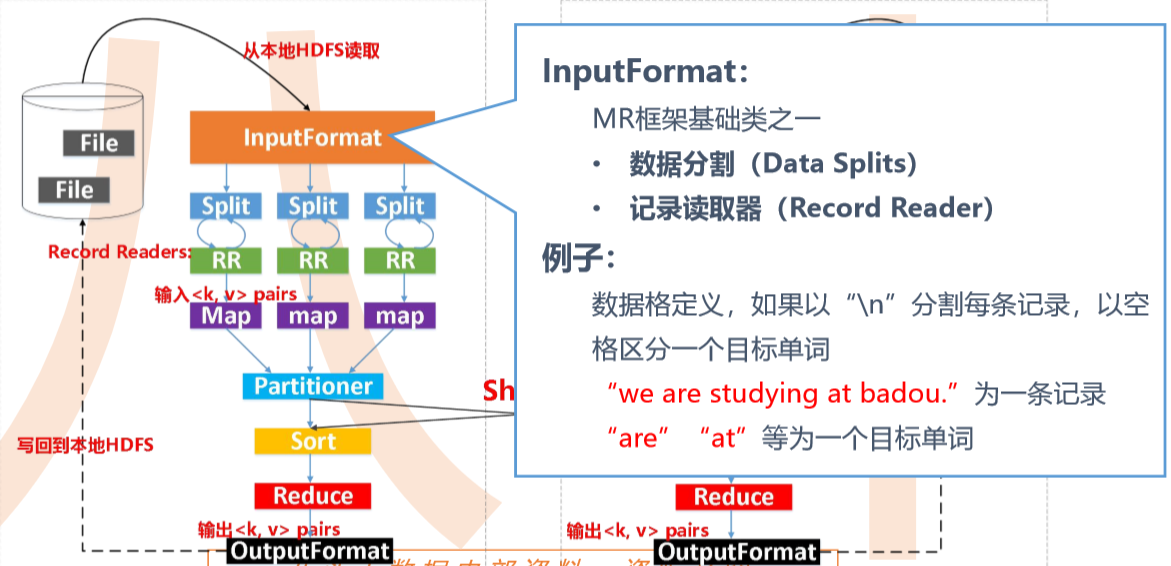
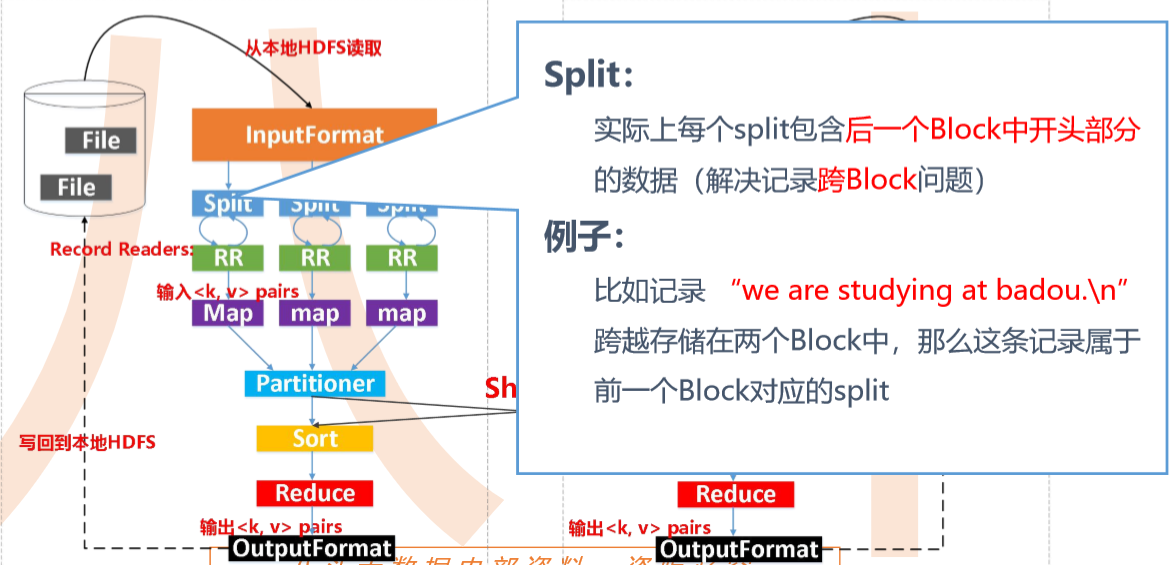
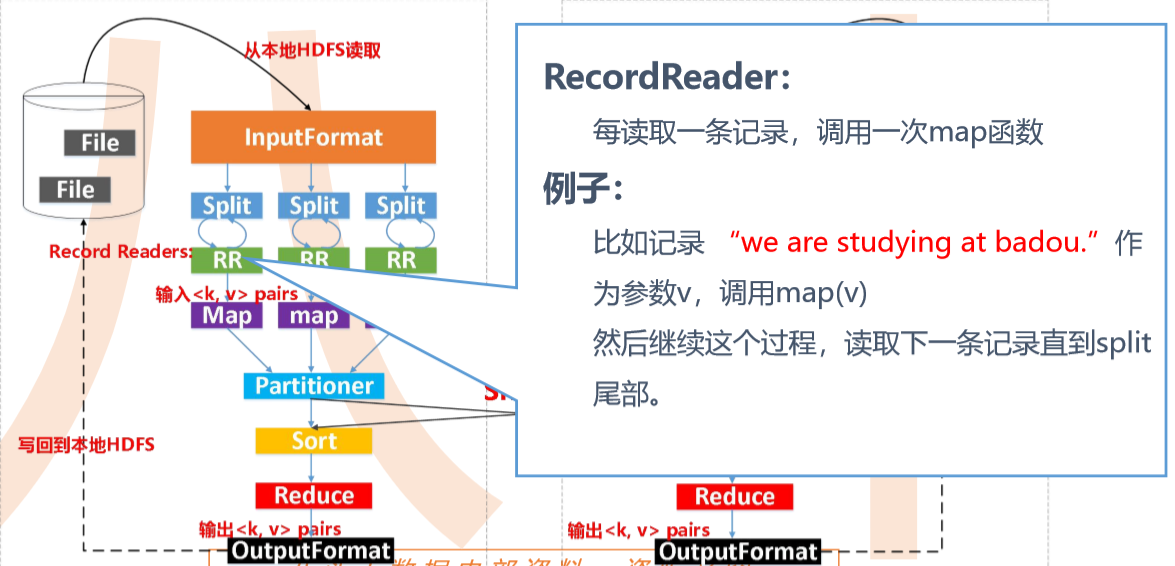
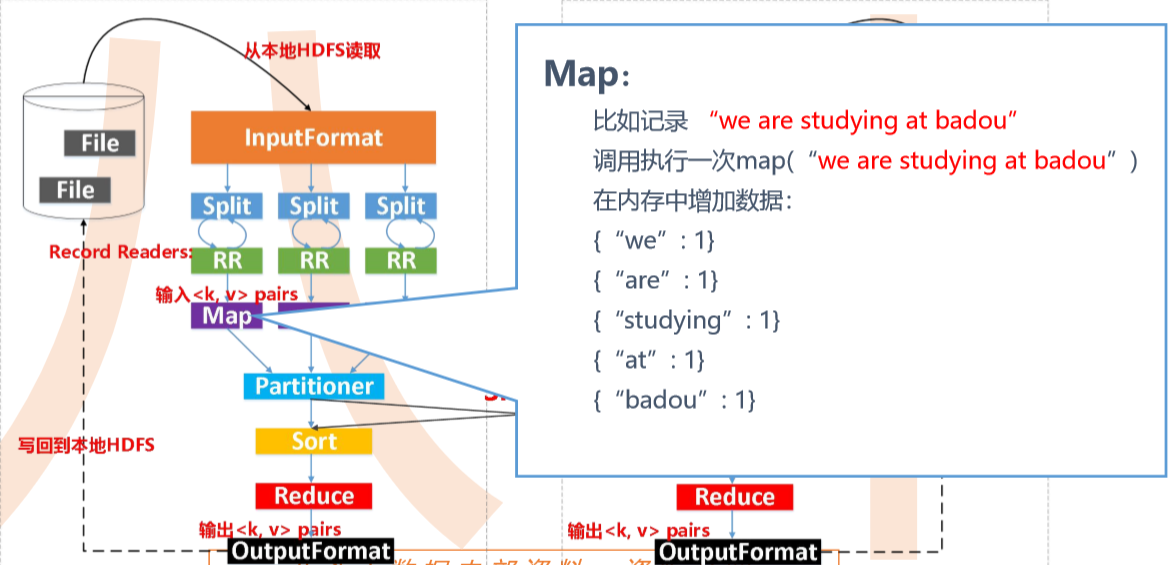
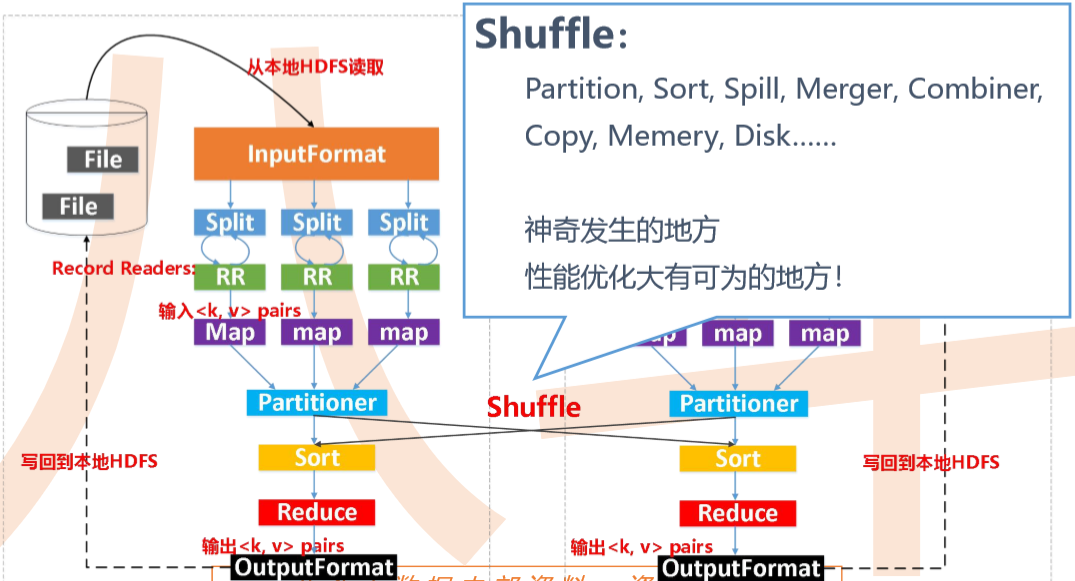
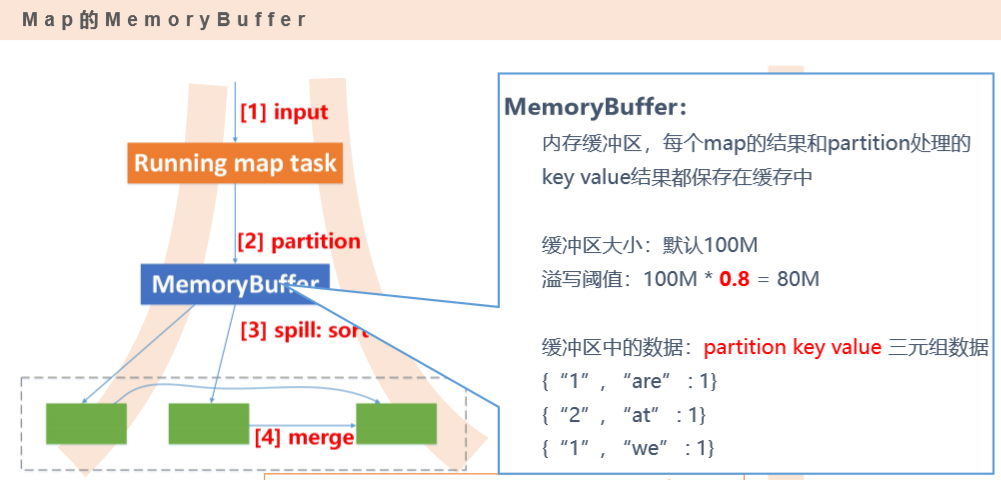
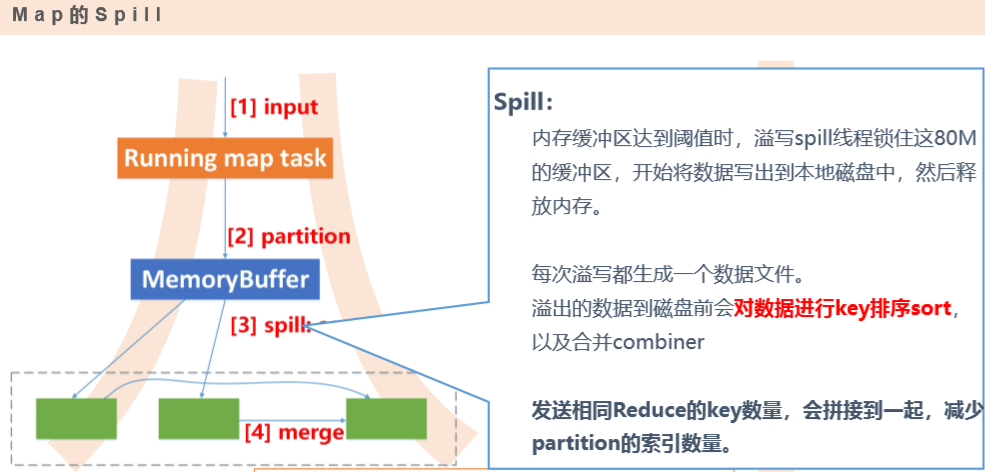
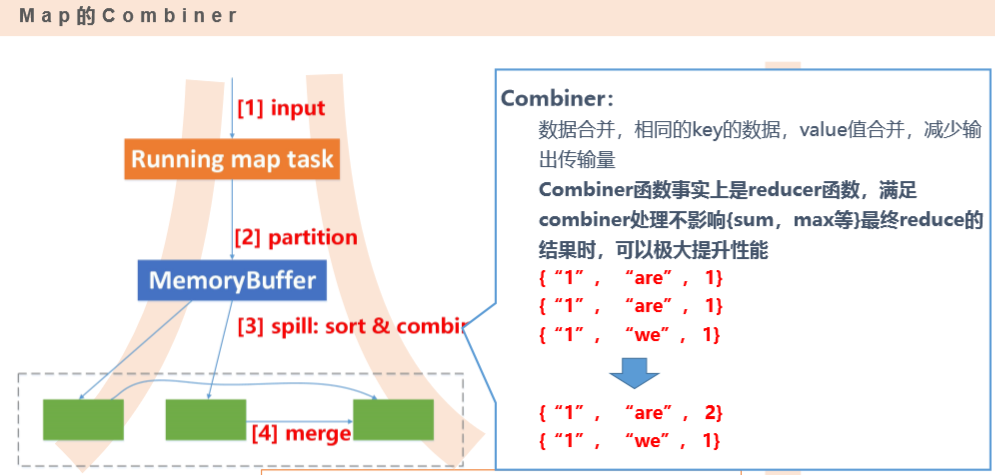
输入数据是hdfs的block,通过一个map函数把它转化为一个个键值对,并同时将这些键值对写入内存缓存区(100M),内存缓存区的数据每满80M就会将这80M数据写入磁盘,在写入磁盘的过程中会进行分区、排序。
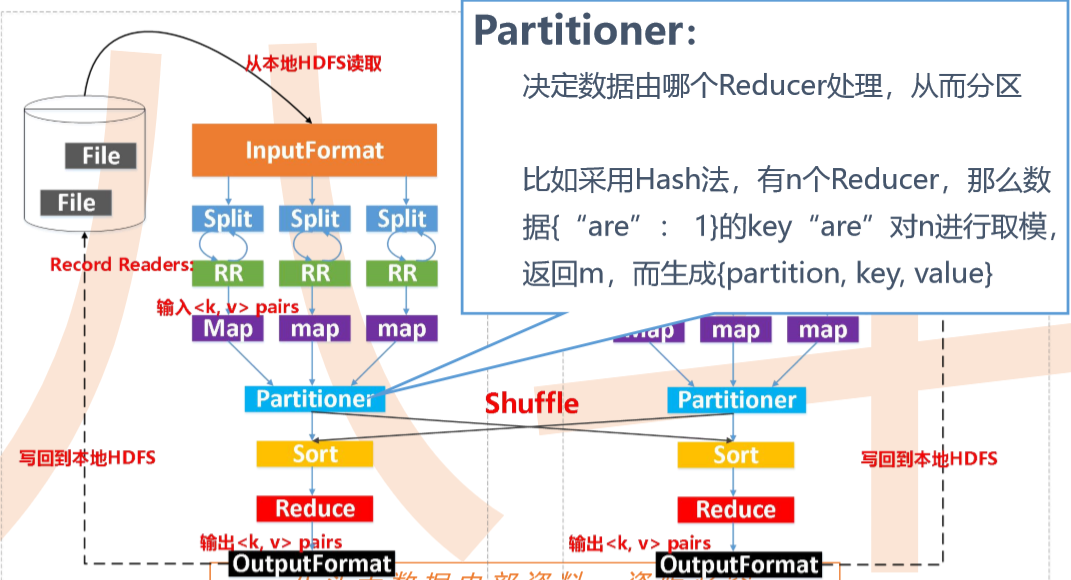
把数据按键hash分区得到多个partition,保证同个键的数据落入同一个分区,partition数目一般和reduce数目一致(也可以是reduce数目的倍数)。