
XGBoost论文阅读
论文创新点:
- 提出了一种能处理稀疏数据的提升生树算法
- 描述了一种加权分位数方法的大概流程,能够用于处理近似树学习中的实例权重。
- 并行和分布式设计让这个算法有非常快的训练速度。
- XGBoost能够在外存上进行计算,使其能处理更大的数据量。
提升树模型小结


提升树模型有多颗树组成,每颗树都把一个样本映射到一个叶子节点中,每个叶子节点都有一个权重 wi ,也就是落入这个叶子的样本在这颗树上的预估值,每个样本最终的预估值是所有树上预估值的和。
这只是最原始的提升树模型,但是这样的模型非常容易过拟合,实际上,还需要加入正则化项
正则化项包含两个部分:
- 惩罚树的叶子节点树目,即控制模型的复杂度。
- 惩罚叶子节点的权重,防止个别叶子节点权重太大,破坏模型的稳定性

梯度提升树

前面介绍的提升树模型在欧几里得空间中是无法用传统的方法来优化的,梯度提升树采用了贪心的算法:
在第 t 轮迭代的时候,固定前面 t-1 轮得到的弱分类器,优化第 t 个若分类器,使其和前面 t-1 轮弱分类器和的 loss 最小
简单的来说在每一轮迭代的时候都选择使损失函数最小的模型。
那么如何去计算第 t 轮的弱分类器呢?
在这里先回顾一些泰勒公式:
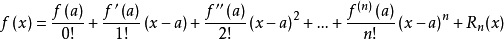
我们可以对上面的损失函数做二阶泰勒展开:

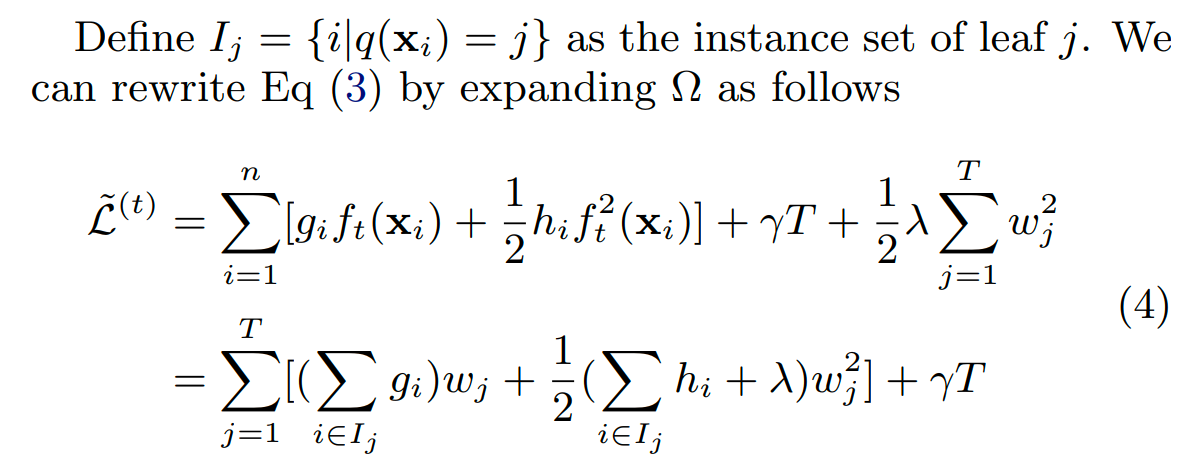
如果树的结构确定,我们可以计算出每个叶子节点最优的权重:
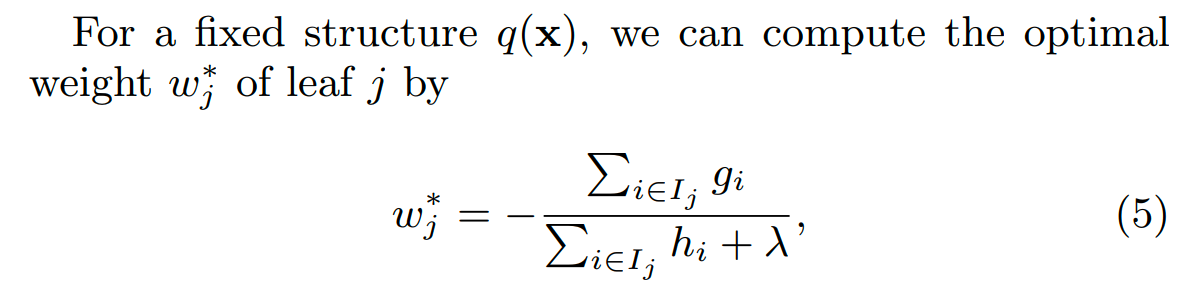
把它代入上面的式子,可以得到如下损失函数:

这个 loss 可以被当作一个 score 去作为选择树结构的标准,其实就相当于决策树分裂是选择特征的信息增益、基尼系数等
树分裂后 loss 减少的程度如下:

权重缩放和列采样
为了防止过拟合,xgboost在loss函数加入正则化项之外,还采用了权重缩放和列采样
权重缩放
权重缩放的思想和梯度下降法中学习率的概念类似,就是新构建一个树和对它叶子节点的权重 w 乘一个缩放系数,防止xgboost拟合的过快,越过最优点或再最优点震荡
列采样
列采样的思想和随机森林一样,其实就是在boost算法上有引入了bagging来防止过拟合
分裂点选择
1. 精确算法

精确算法通过遍历所有的特征的所有的可能分裂点来选出最优分裂点,该方法精确度高,但是耗费时间,而且如果数据不能全部载如内存中,这个方法就不适用了。
2. 近似算法

近似算法没有遍历所有可能的切分点,近似算法先计算出候选切分点(一般是特征的分位点),然后只遍历这些候选切分点选出最优切分点。
计算候选切分点的方法也有两种:
1. 计算全局候选切分点
即在树分裂前就把候选切分点计算好,只需要计算一次
2. 计算局部候选切分点
在树每次分裂后都要重新计算候选切分点,因为每次分裂后落入该子树的样本分布变了
全局候选切分更适合数据比较充足的情况,局部候选切分点适用于数据量比较少,且树比较深的情况
加权分位点计算方法
前面介绍了一种近似算法,近似算法要先计算出候选切分点,通常把特征的分位点作为候选切分点,那么这些分位点如何计算呢?xgboost论文中介绍了一种加权分位点的计算方法
XGBoost特征重要性的实现原理
特征重要性可以用来做模型可解释性,这在风控等领域是非常重要的方面。xgboost实现中Booster类get_score方法输出特征重要性,其中importance_type参数支持三种特征重要性的计算方法:
1.importance_type=weight(默认值),特征重要性使用特征在所有树中作为划分属性的次数。
2.importance_type=gain,特征重要性使用特征在作为划分属性时loss平均的降低量。
3.importance_type=cover,特征重要性使用特征在作为划分属性时对样本的覆盖度。
