



Hbase
Hbase介绍
• HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现 的编程语言为 Java。
• 是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,因此可以容错地存 储海量稀疏的数据。
• 特性:
– 高可靠
– 高并发读写
– 面向列
– 可伸缩
– 易构建
行存储 vs 列存储
• 行存储:
– 优点:写入一次性完成,保持数据完整性
– 缺点:数据读取过程中产生冗余数据,若有少量数据可以忽略
• 列存储
– 优点:读取过程,不会产生冗余数据,特别适合对数据完整性要求不高的大数据领域
– 缺点:写入效率差,保证数据完整性方面差
Hbase 优势
• 海量数据存储
• 快速随机访问
• 大量写操作的应用。
Hbase 应用场景
• 互联网搜索引擎数据存储
• 海量数据写入
• 消息中心
• 内容服务系统(schema-free)
• 大表复杂&多维度索引
• 大批量数据读取
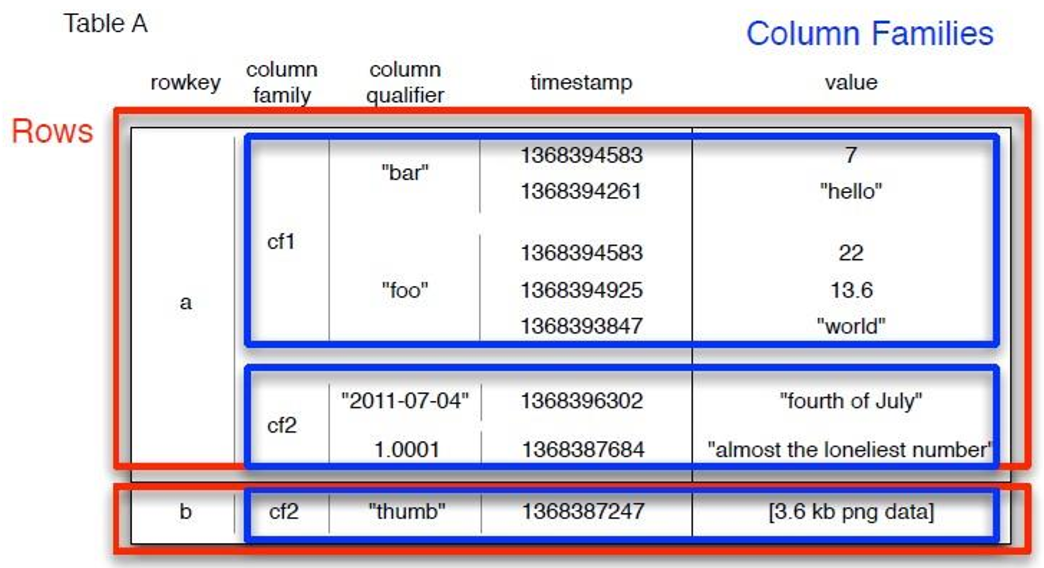
Hbase 数据模型

• RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。
• Column Family:列族,拥有一个名称(string),包含一个或者多个相关列
• Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加
• Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
• Value(Cell):Byte array

三维有序:
Hbase 物理模型
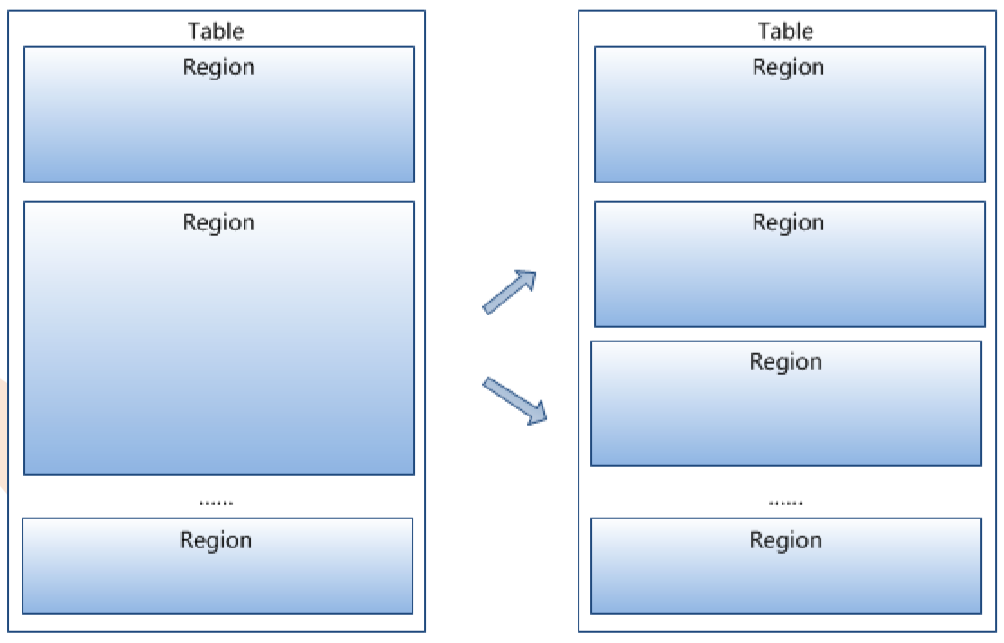
• Hbase一张表由一个或多个 Hregion组成
• 记录之间按照Row Key的字典 序排列
• Region按大小分割的,每个表 一开始只有一个region,随着 数据不断插入表,region不断 增大,当增大到一个阀值的时 候,Hregion就会等分会两个 新的Hregion。当table中的行 不断增多,就会有越来越多的 Hregion。
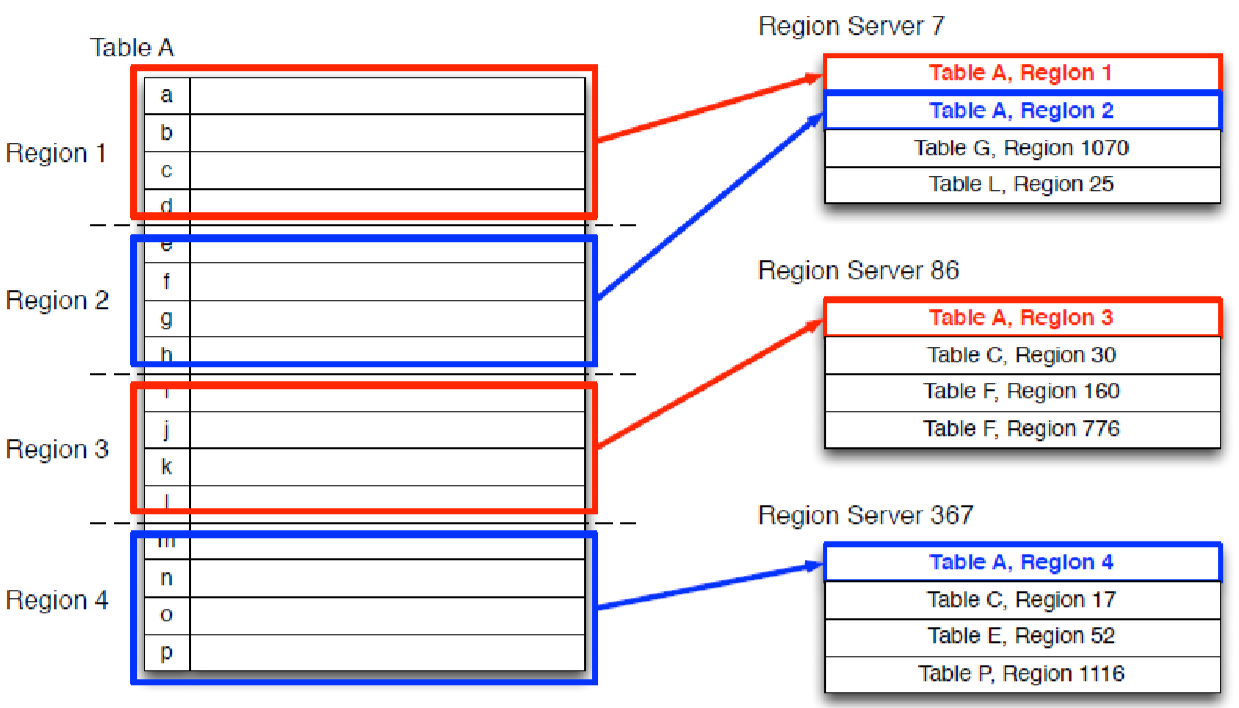
• 表 -> HTable
• 按RowKey范围分的Region-> HRegion ->Region Servers
• HRegion按列族(Column Family) ->多个HStore
• HStore -> memstore + HFiles(均为有序的KV)
• HFiles -> HDFS
• HRegion是Hbase中分布式存 储和负载均衡的最小单元。
• 最小单元就表示不同的 Hregion可以分布在不同的 HRegion server上。
• 但一个Hregion是不会拆分到 多个server上的。
• HRegion虽然是分布式存储的 最小单元,但并不是存储的最 小单元。


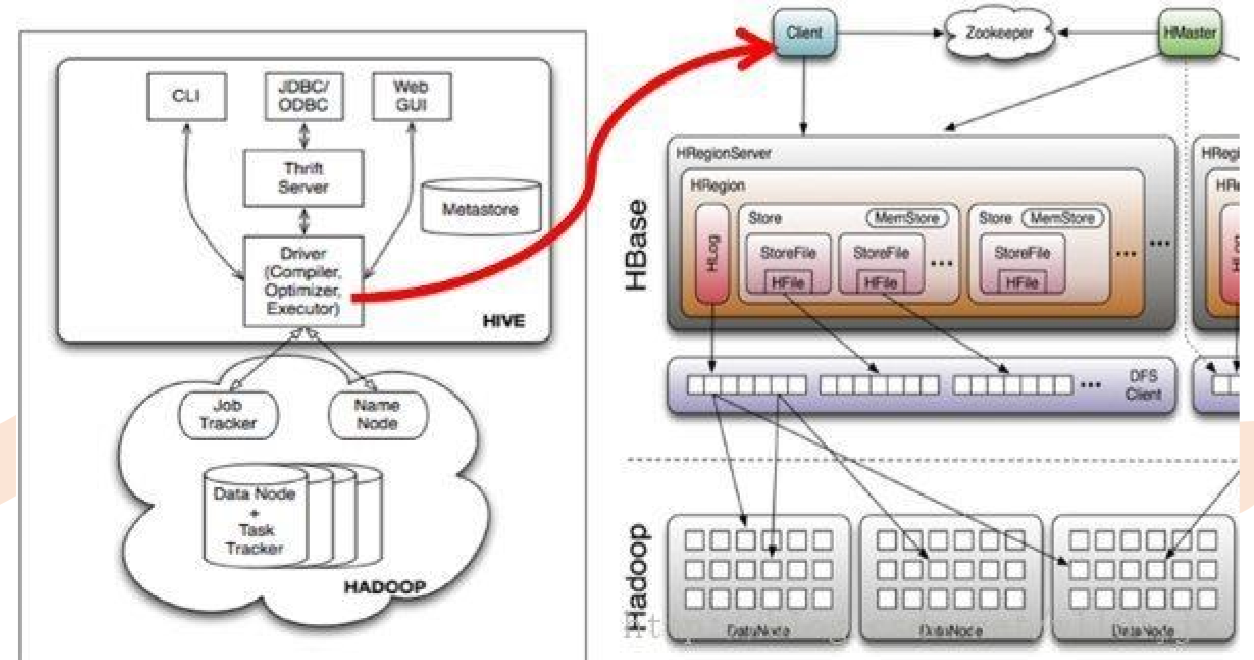
Hbase 系统架构
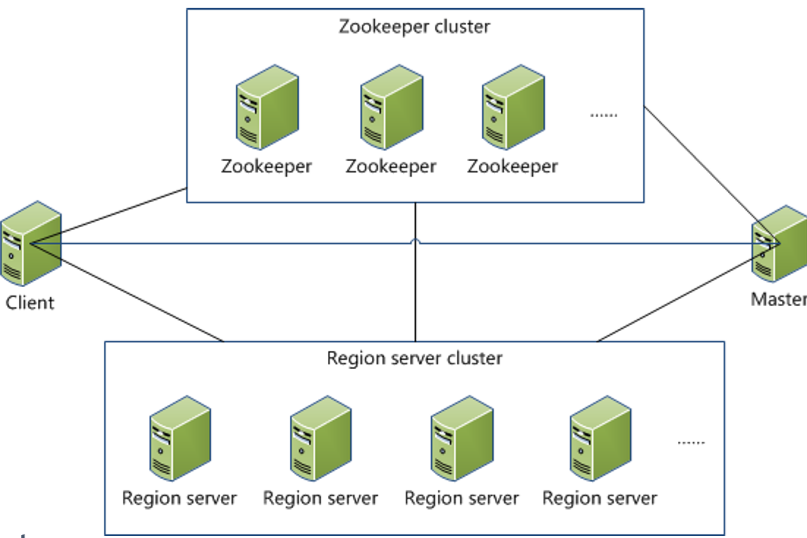
• Client
– 访问Hbase的接口,并维护Cache加速Region Server的访问
• Master
– 负载均衡,分配Region到RegionServer
• Region Server
– 维护Region,负责Region的IO请求
• Zookeeper
– 保证集群中只有一个Master
– 存储所有Region的入口(ROOT)地址
– 实时监控Region Server的上下线信息,并通知Master

Hive整合Hbase
• HBase是被设计用来做k-v查询的,但有时候,也会遇到基于HBase表的复杂统 计,写MR很不方便。Hive考虑到了这点,提供了操作HBase表的接口。
• Hive读取HBase表,通过MR,最终使用HiveHBaseTableInputFormat来读取数 据,在getSplit()方法中对 HBase表进行切分,切分原则是根据该表对应的 HRegion,将每一个Region作为一个InputSplit,即,该表有多少个Region,就 有多少个Map Task;
• 每个Region的大小由参数hbase.hregion.max.filesize控制,默认10G,这样会 使得每个map task处理的数据文件太大,map task性能自然很差;
• 为HBase表预分配Region,使得每个Region的大小在合理的范围;
• 创建Hbase表:
– create 'classes','user'
• 加入数据:
– put 'classes','001','user:name','jack'
– put 'classes','001','user:age','20'
– put 'classes','002','user:name','liza'
– put 'classes','002','user:age','18'
• 创建Hive表并验证:
– create external table classes(id int, name string, age int)
– STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
– WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,user:name,user:age")
– TBLPROPERTIES("hbase.table.name" = "classes");
• 再添加数据到Hbase:
– put 'classes','003','user:age','1820183291839132'
参考资料
八斗大数据

