
word2vec
问题背景
在自然语言处理中,我们应该如何表示一个词呢?我们指导所有的深度学习或机器学习模型最终的输入都必须是向量才能计算,所以我们在处理一个词最终也是要把它表示成一个向量来处理。那么如何把一个词表示成一个向量呢?one hot 编码是一种常用的处理方法,当是这个方法存在两个缺点:一是 one hot 编码后得到的词向量维度太高,用这个来做运算的话时间复杂度和空间复杂度都会非常高。二是词之间是存在相似性的,有些词意思相近,有些词意思差的很远,onehot编码不能体现出词之间的相近性。
解决方法和面临的问题
借助embedding的思想我们很自然的想到,可以先把词用 one hot 编码表示,然后把 one hot 编码作为神经网络输入再接一个emdedding层降维,在这里我们似乎解决了上面的第一个问题。但是在这里我们又面临了新的问题:完整的网络结构怎么设计?神经网络一般都是用监督学习方式训练的,必须要有数据和label,那么label怎么得到?上面的第二个问题又怎么解决?
早期的词向量模型
该模型结构如下图所示,它包括四个层:输人(Input)层、投影(Projection)层、隐藏(Hidden)层和输出(Output)层。其中W、U分别为投影层与隐藏层以及隐藏层和输出层之间的权值矩阵,p、q分别为隐藏层和输出层上的偏置向量。改模型根据当前词前面的n-1个词来预估当前词,其输入为n-1个词向量(这个词向量就是最终目标),在投影层中对这个n-1个词向量进行concat,然后经过一个全连接层(隐藏层),最后在经过一个全连接层并通过一个softmax函数来得到没个词的概率。可以看出这个模型和普通机器学习模型不同,输入的词向量也是需要被训练的。
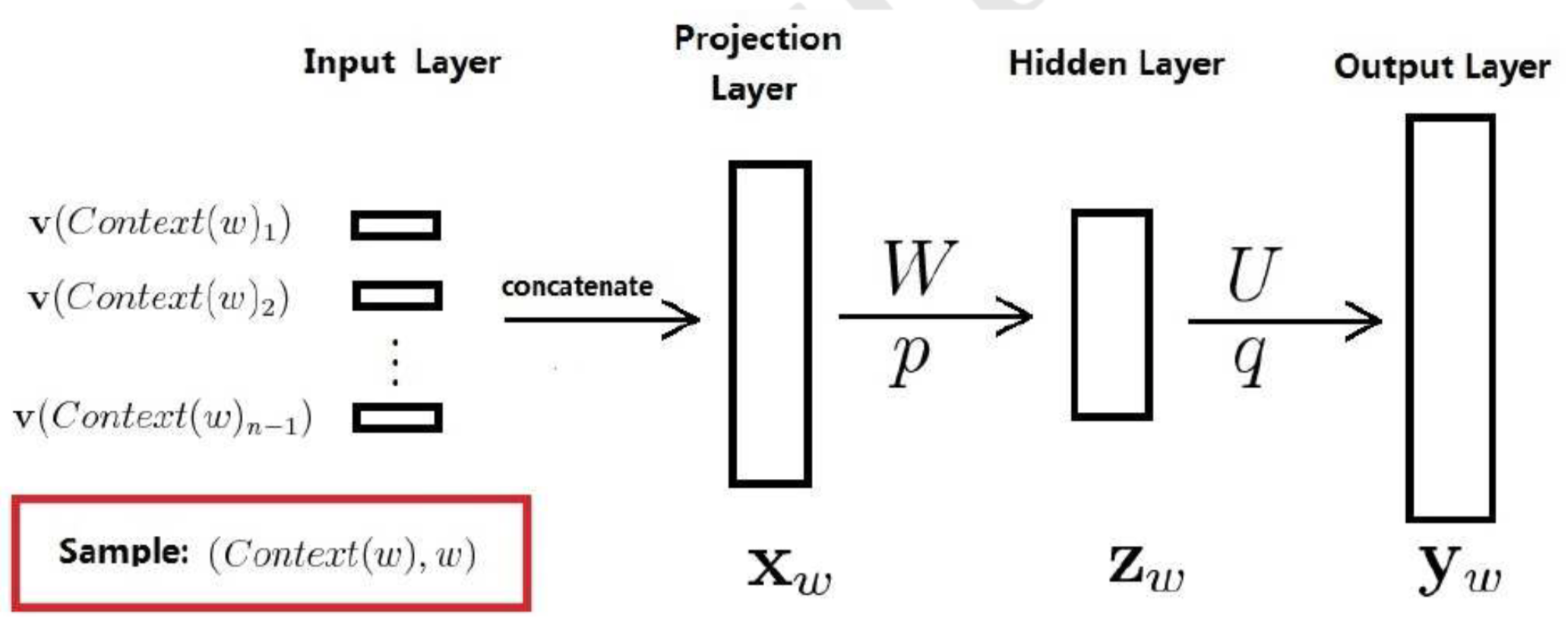
下面我们来分析一下这个模型的参数和计算量:
输入层参数数目为(n-1)*k,其中n大小一般在10以内,k为词向量维度,一般在100以内。输入层到投影层只是一个concat操作,时间复杂度为O(n-1),计算量级在101
W是一个((n-1)*k,m)维度的矩阵,m是隐藏层的维度,一般在100以内。投影层到隐藏层之间的时间复杂度为O(n-1)*k*m),计算量级在105
U是一个(m,v)维度的矩阵,v是输出层的维度(词汇量大小),一般在105以内。投影层到隐藏层之间的时间复杂度为O(m*v),计算量级在107
可以看出时间复杂度和参数数目主要集中在隐藏层和输出层之间,下面来计算word2vec是怎么改进的
Word2Vec模型
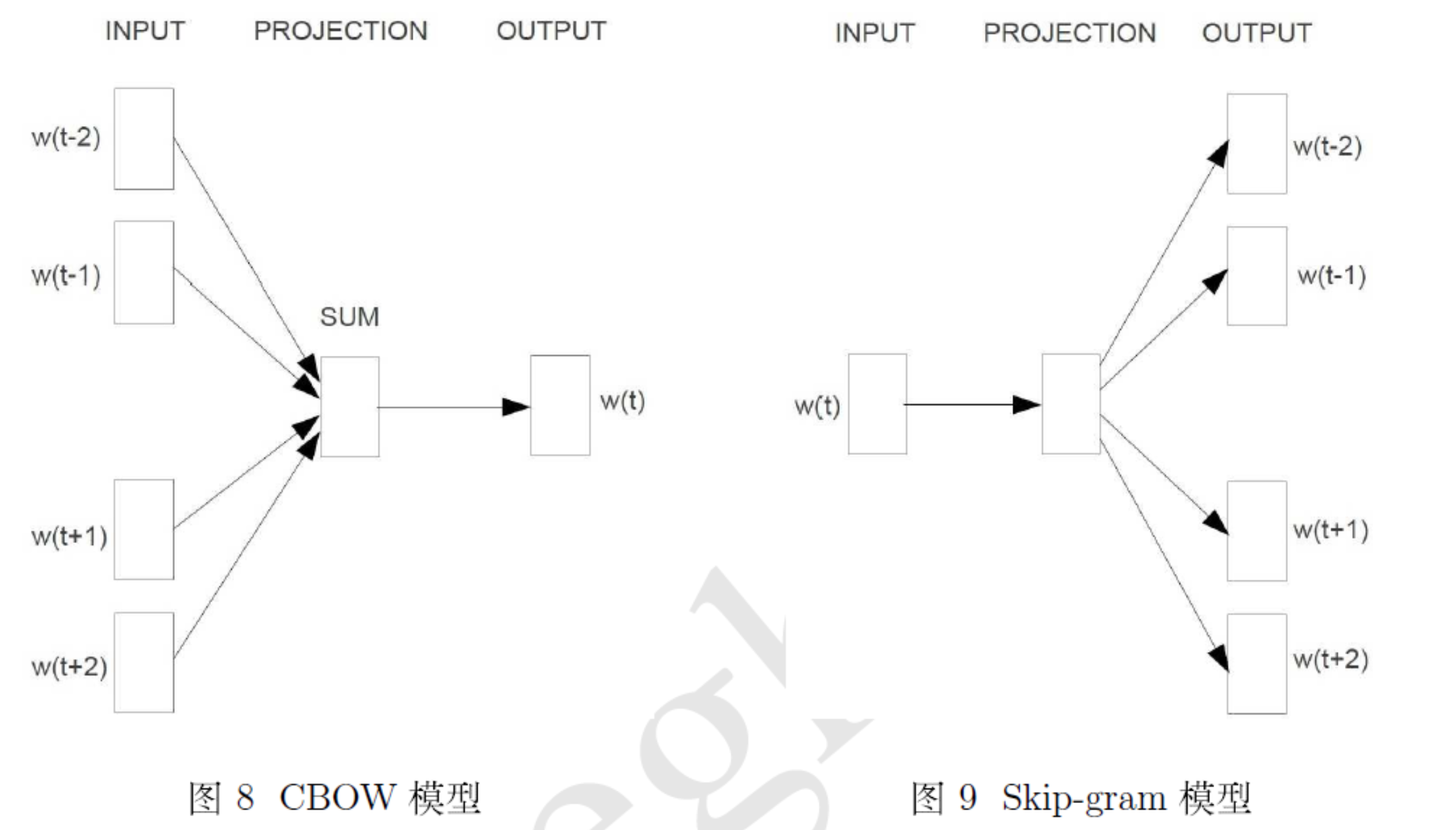
CBOW模型和Skip-gram模型
word2vec中提出了两种模型:CMOW模型用上下文去预测当前词出现的概率,Skip-gram用当前词去预测上下文词出现的概率。
word2vec中的加速训练方法
为了加速训练,word2vec提出了hierarchical softmax和Negative Sampling两种加速训练的方法
1. hierarchical softmax
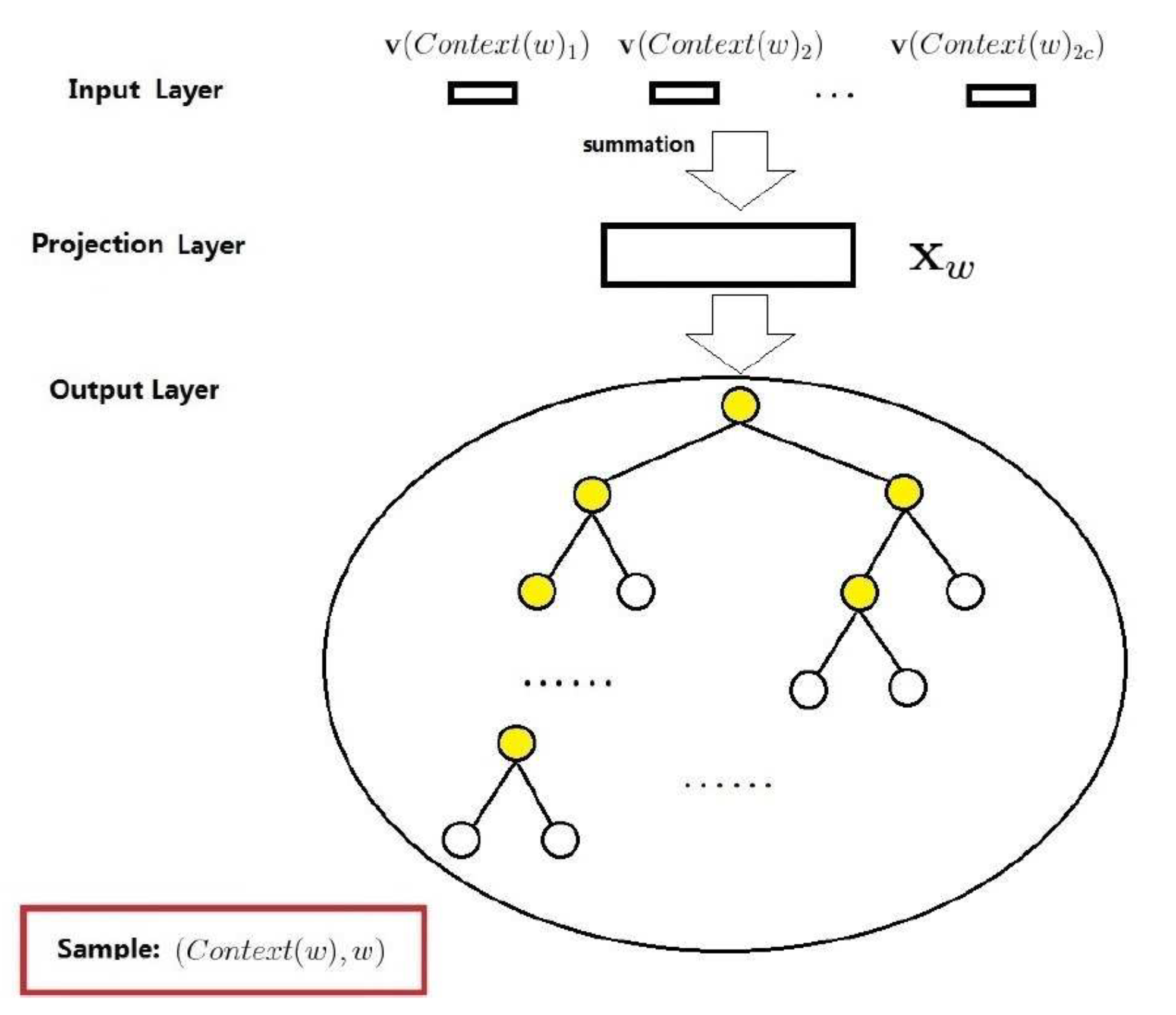
基于 hierarchical softmax 的 CBOW 模型结构如上图所示,和前面的模型相比主要有以下几点不同:
1. 去掉了隐藏层,输入的词向量求和之后直接进输出层
2. 把输出层换成了一个哈夫曼树
在训练前首先会更加这个词出现的频率建立一颗哈夫曼树,对于非根节点,约定左子树节点编码为1,右子树节点编码为0,如下图所示,足球的路径编码为(1,0,0,1)
在每个非叶子结点向左或右走时,都看作一个二分类问题(约定向左为负,向右为正),可以得到足球的概率为:
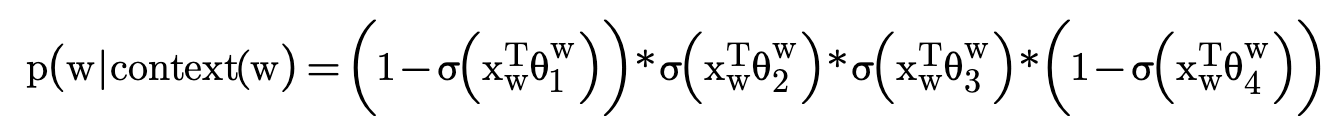
得到没个词的概率后,就可以通过最大似然估计来计算损失了
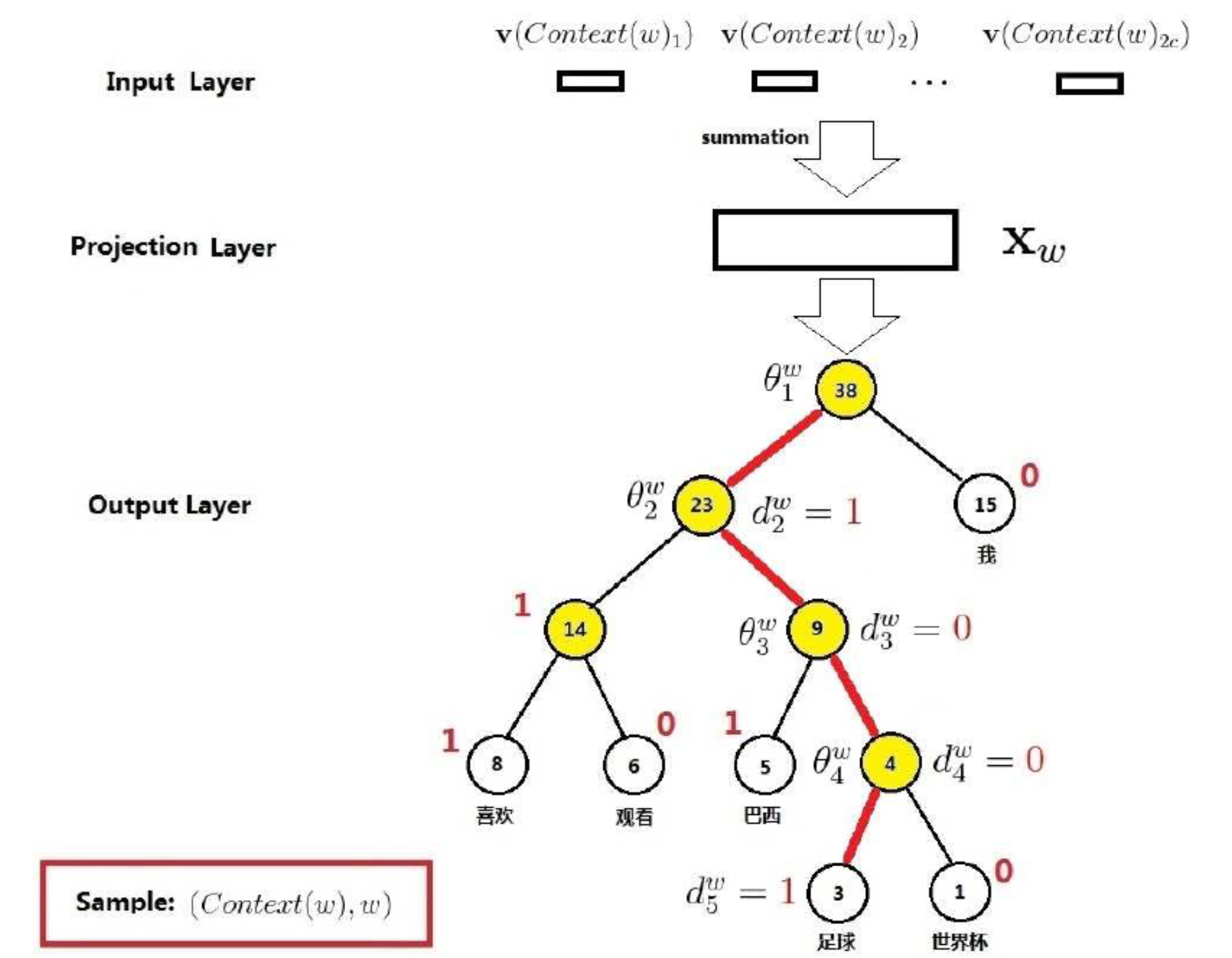
下面来分析一下基于 hierarchical softmax 的 CBOW 模型的参数数目和时间复杂度:
投影层的维度为k,投影层到输出层的参数数目为k*v,和原先模型一样,但是时间复杂变成了O(k*logv)
2. Negative Sampling
面试常问问题
word2vec模型cbow与skip-gram的比较
在cbow方法中,是用周围词预测中心词,从而利用中心词的预测结果情况,使用GradientDesent方法,不断的去调整周围词的向量。cbow的对周围词的调整是统一的:求出的gradient的值会同样的作用到每个周围词的词向量当中去。可以看到,cbow预测行为的次数跟整个文本的词数几乎是相等的(每次预测行为才会进行一次backpropgation, 而往往这也是最耗时的部分),复杂度大概是O(V)。
而skip-gram是用中心词来预测周围的词。在skip-gram中,会利用周围的词的预测结果情况,使用GradientDecent来不断的调整中心词的词向量。可以看出,skip-gram进行预测的次数是要多于cbow的:因为每个词在作为中心词时,都要使用周围词进行预测一次。这样相当于比cbow的方法多进行了K次(假设K为窗口大小),因此时间的复杂度为O(KV),训练时间要比cbow要长。
总结:cbow是用一个词去训练多个词时间复杂度低,skip-gram是用多个词训练一个词,时间复杂度更高,在数据量较少的情况下skip-gram效果更好。
参考资料
https://www.cnblogs.com/peghoty/p/3857839.html
https://zhuanlan.zhihu.com/p/26306795/
https://www.cnblogs.com/pinard/p/7243513.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号