

xgboost
XGBoost可以看作是GBDT的一种高效实现,但是里面也加入了很多独有的思路和方法。为了便于理解我们对比着GBDT来理解XGBoost。
损失函数角度
GBDT的损失函数:
\[{L_t} = \sum\limits_{i = 1}^m {L\left( {{y_i},{f_{t - 1}}\left( {{x_i}} \right) + h{}_t\left( {{x_i}} \right)} \right)} \]
XGBoost损失函数:
\[{L_t} = \sum\limits_{i = 1}^m {L\left( {{y_i},{f_{t - 1}}\left( {{x_i}} \right) + h{}_t\left( {{x_i}} \right)} \right)} + \gamma J + \frac{\lambda }{2}\sum\limits_{j = 1}^J {w_j^2} \]
我们可以看到XGBoost在损失函数上加了正则化项,这里的m是样本数目,J是叶子节点数目,wj是第j个叶子的预测值。
优化损失函数的方法上
GBDT:
GBDT是沿着损失函数的负梯度方向来最小化损失函数。
XGBoost:


对上面的损失函数求导我们就可以得到每个叶子区域的最优解:
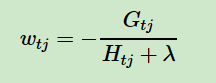
把上面的式子带入原目标函数得:
![]()
这里就引出了XGBoost选择分裂特征的准则:

XGBoost中防止过拟合的方法
(1) 损失函数上加了正则化项,限制了节点的数目,即限制模型的复杂度;限制了每个叶子节点的权重,防止个别特征影响过大。
(3) Column Subsampling:在对同一层内每个结点分裂之前,先随机选择一部分特征,然后只需要遍历这部分的特征,来确定最优的分割点。
XGBoost在计算效率上的优化:
(1)选择分裂特征时支持并行计算。
(2)对所有的特征的值进行排序分组,方便前面说的并行选择。对分组的特征,选择合适的分组大小,使用CPU缓存进行读取加速。将各个分组保存到多个硬盘以提高IO速度。
XGBoost特征选择方法
1. 贪婪算法(暴力遍历)
2. 近似算法:根据特征分布的加权分位数(k,自己选择)计算特征切分点
XGBoost和GBDT有什么区别?
1. 目标函数不同,Xgboost的目标函数显式的带了正则化项,该正则化项中包含了叶子节点的数目和叶子节点的得分。Xgboost对目标函数进行了二阶泰勒展开来近似原来的目标函数,通过求解这个近似方程可以得到每个叶子节点的输出(这两者在优化上的差别有点像梯度下降法和牛顿法的区别)。
2. GBDT的弱分类器只能是CART回归树,而Xgboost弱分类器还可以是线性分类器。
3. Xgboost支持并行计算更加高效。
4. Xgboost允许使用列采样来防止过拟合。
参考博客
https://www.cnblogs.com/pinard/p/10979808.html
https://blog.csdn.net/a819825294/article/details/51206410
