
KNN
算法原理
对于一个预测样本,KNN把与这个样本最近的k个样本中样本数最多的类别作为该预测样本的类别。
k值对算法的影响
k值大模型越简单,较小的k值容易过拟合。
kd树
kd树是一种高维空间上的快速检索结构,这里以平衡kd树为例,即划分子树时以中位数作为划分点。
kd树构建步骤
假设数据只有两个维度(x1,x2)
- 第一次我们选择在x1轴上划分子树,我们计算所有数据在x1轴上的中位数p,即得到了数据(p,x2),我们以(p,x2)为根节点把剩余的数据划分到左右子树(左子树数据x1<p,右子树数据x1>p)。
- 第二次我们选择在x2轴上划分子树,在1中落到左右子树上的数据重复1中的操作。
- 重复2中的操作划分子数直到当前子树上自有一个数据(对于树中深度为j的节点(根节点深度为0),选择第$\left( {j\bmod k} \right) + 1$个轴,$k$为数据的维度)。
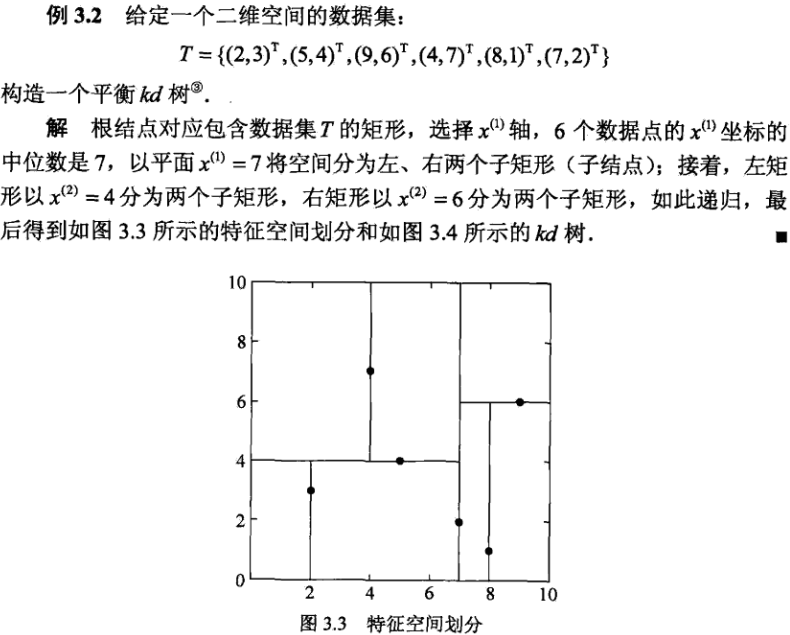
kd树构建例子(来源于李航统计学习方法)
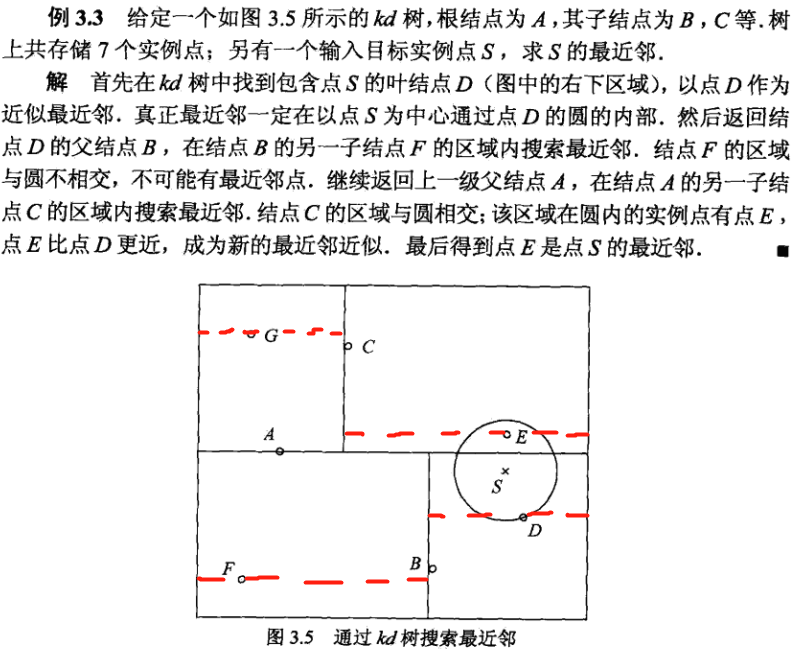
利用kd树进行k近邻检索实例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号