
Redis基础知识(学习笔记12--集合的底层实现原理)
1. 两种实现的选择
对于Hash 与 Zset 集合,其底层的实现有两种:压缩表ziplist 和 跳跃表skiplist。着两种实现对于用户来说是透明的,但用户写入不同的数据,系统会自动使用不同的实现。只有同时满足以配置文件redis.conf中相关集合元素数量阈值与元素大小阈值两个条件,使用的就是压缩表,只要有一个条件不满足使用的就是跳跃表skiplist.例如,对于ZSet集合中这两个条件如下:
***集合元素个数小于redis.conf中zset-max-ziplist-entries属性的值,其默认值为128。
***每个集合元素大小都小于redis.conf中zset-max-ziplist-value属性的值,其默认值为64字节。
从配置文件中查看,当然也可以通过命令查看,例如:
查看zset的
> config get zset-*-ziplist-*
查看hash的
> config get hash-*_ziplist-*
2. ziplist
(1) 什么是ziplist
ziplist,通常称为压缩列表,是一个经过特殊编码的用于存储字符串或整数的双向链表。其底层数据结构由三部分组成:head、entries 与 end,这三部分在内存上是连续存放的。
(2)head
head又由三部分构成:
***zlbytes:占4个字节,用于存放ziplist列表整体数据结构所占的字节数,包括zlbytes本身的长度。
***zltail:占4个字节,用于存放ziplist中最后一个entry在整个数据结构中的偏移量(字节)。该数据的存在可以快速定位列表的尾entry位置,以方便操作。
***zllen:占有两个字节,用于存放列表包含entry个数。由于其只有16位,所以ziplist最多可以含有的entry个数为2^16-1 =65535个。
(3) entries
entries是真正的列表,由很多的列表元素entry构成。由于不同的元素类型、数值的不同,从而导致每个entry的长度不同。
每个entry由三部分构成:
*** prvelength:该部分用于记录上一个entry的长度,以实现逆序遍历,默认长度为1字节,只要上一个entry的长度<254字节,prvelength就占1字节,否则其会自动扩展为3字节长度。
【为什么是254呢?因为255 是全是1,是end的标识符,需要预留出来;254 是自动扩展的标识符,也是预留的。】
*** encoding:该部分用于标志后面data的具体类型。如果data为整数类型,encoding固定长度为1字节。如果data为字符串类型,则encoding长度可能会是1字节、2字节或5字节。data字符串不同的长度,对应不同的encoding长度。
*** data:真正存储的数据。数据类型只能是整数类型或字符串类型。不同的数据占用的字节长度不同。
(4)end
end 只包含一部分,称为zlend,占1个字节,值固定为255,即二进制全为1,表示一个ziplist列表的结束。
总结

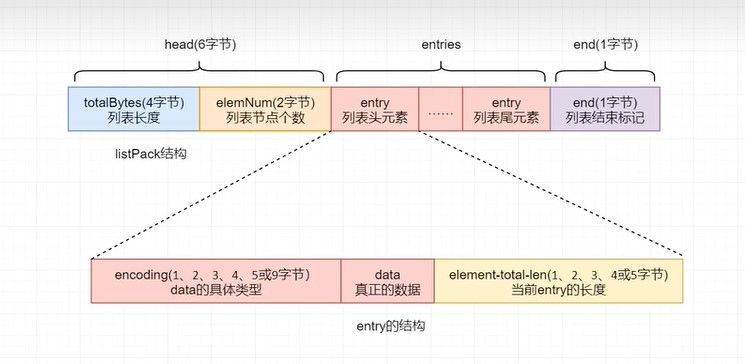
3.listPack
对应ziplist,实现复杂,未来逆序遍历,每个entry中包含一个entry的长度,这样会导致在ziplist中修改或者插入时需要进行级联更新。在高并发的写常见下会极度降低redis的性能。为了实现更紧凑、更快的解析,更简单的实现,重写实现了ziplist,并命名为listPack。
在redis 7.0 中,已经将ziplist全部替换为listPack,但为了兼容性,在配置中也保留了ziplist的相关属性。
>config get zset-max-listpack-*
注意:hash一样。
(1) 什么是listPack
listPack也是一个经过特殊编码的用于存储字符串或整数的双向链表。其底层数据结构也由三部分组成:head、entries 与 end,并且这三部分在内存上也是连续存放的。
listPack 与 ziplist的重大区别在head 与每个entry的结构上,表示列表结束的end与ziplist的zlend是相同的,占一个字节,且8位全为1。
(2)head
head由两部分组成:
***totalBytes:占4个字节,用于存放listPack列表整体数据结构所占的字节数,包括totalBytes本身的长度。
***elemNum:占2个字节,用于存放列表包含的entry个数。其意义与zipList中zllen的相同。
与ziplist的head相比,没有了记录最后一个entry偏移量的zltail。
(3)entries
entries 也是listPack中真正的列表,由很多的列表元素entry构成。由于不同的元素类型、数值的不同,从而导致每个entry的长度不同,但与ziplist的entry结构相比,listPack的entry结构发生了较大变化。
其中最大的变化就是没有了记录前一个entry长度的prvelength,而增加了记录当前entry长度的element-total-len。而这个改变仍然可以实现逆序遍历,但却避免了由于在列表中间修改或插入entry时引发的级联更新。
每个entry仍由三部分构成:
***encoding:该部分用于标志后面的data的具体类型。如果data为整数类型,encoding长度可能会是1、2、3、4、5或9字节。不同的字节长度,其标识位不同。如果data为字符串类型,则encoding长度可能会是1、2或5字节。data字符串不同的长度,对应着不同的encodingc长度。
*** data:正常存储的数据。数据类型只能是整数类型或字符串类型。不同的数据占用的字节长度不通。
***element-total-len:该部分用于记录当前entry的长度,用于实现逆序遍历。由于其特殊的记录方式,使其本身占有的字符数据可能会是1、2、3、4 或5字节。
(4)总结
4.skiplist
(1) 什么是skiplist
skiplist,跳跃列表,简称跳表,是一种随机化的数据结构,基于并联的链表,实现简单,查找效率较高。简单来说跳表也是链表的一种,只不过它在链表的基础上增加了跳跃功能。也正是这个跳跃功能,使得在查找元素时,能够提供较高的效率。
(2)skipList原理
假设有一个带头尾节点的有序列表。

在该链表中,如果要查找某个数据,需要从头到尾逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点,或者找到最后尾节点,后两种都属于没有找到的情况。同样,当我们需要新插入数据 时候,也要经历同样的查找过程,从而确定插入位置。
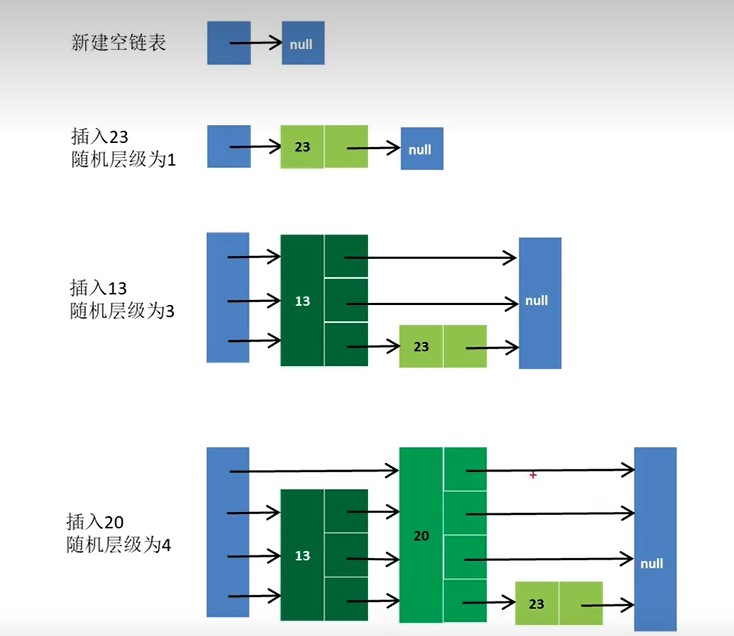
为了提升查找效率,在偶数节点上增加一个指针,让其指向下一个偶数节点。

这样所有偶数节点就连成了一个新的链表(简称高层链表),当然,高层链表包含的节点个数只是原来链表的一半。此时再想查找某个数据时,先沿着高层链表进行查找。当遇到第一个比待查数据大的节点时,立即从该大节点的前一个节点回到原链表中继续进行查找。例如,若想插入一个数据20,则先在(8,19,31,42)的高层链表中查找,找到第一个比20大的节点31,然后再在高层链表中找到31节点的前一个节点19,然后再在原链表中获取到下一个节点值为23。比20大,则20插入到19节点与23节点之间。若插入的是25,比节点23大,则插入到23节点与31节点之间。
该方式明显可以减少比较次数,提高查找效率。如果链表元素较多,为了进一步提升查找效率,可以将原链表构建为三次链表(3的倍数为3级),或更高层级链表。

(3)存在问题
这种对链表分层级的方式从原理看确实提升了查找效率,但再实际操作时,就出现了问题:由于固定序号的元素拥有固定层级,所以列表元素出现增加或者删除的情况下,会导致列表整体元素层级大调整,但这样势必会大大降低系统性能。并且元素节点越靠前,变动的代价越大。
(4)算法优化
解决方案,每一个节点,它的层级是随机的分配的,这样增加或删除节点,对其它不相邻的节点没有影响。
(5)知识点补充
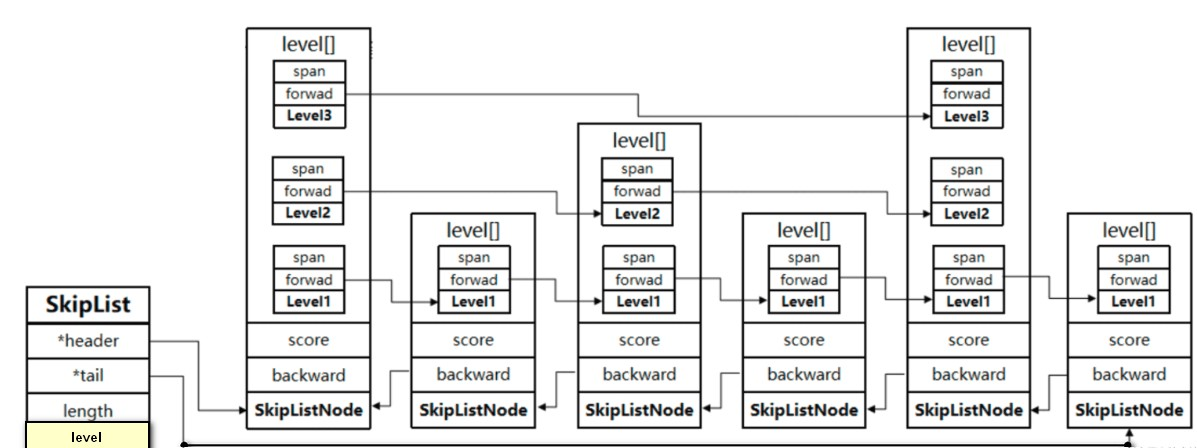
跳表的结构体源码

*** ele,用于存储该节点的元素
*** score,用于存储节点的分数(节点按照 score 值排序,score 值一样则按照 ele 排序)
*** *backward,指向上一个节点
*** level[] 是实现跳表多层次指针的关键所在,level 数组中的每一个元素代表跳表的一层,比如 leve[0] 就表示第一层,leve[1] 就表示第二层。
zskiplist Level 结构体里定义了指向下一个跳表节点的指针** *forward 和用来记录两个节点之间的距离 span
5. quickList
(1) 什么是quickList
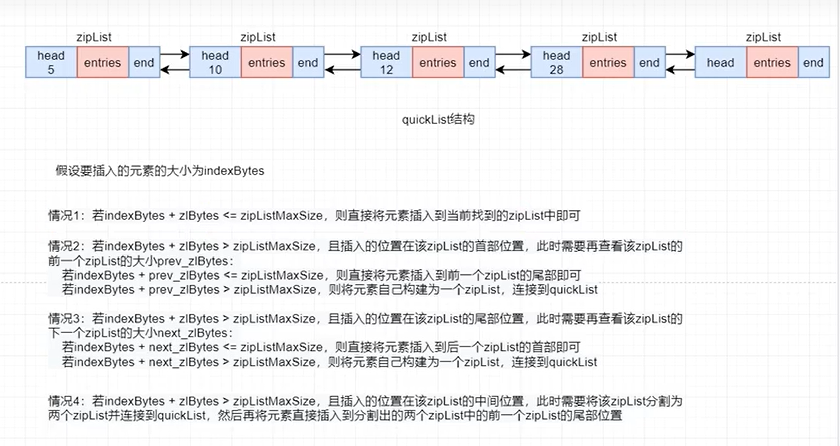
quickList,快速列表,quickList本身是一个双向无循环链表,它的每一个节点都是一个zipList,从redis 3.2 版本开始,对于List的底层实现,使用quickList代替了zipList 和 linkedList。
zipList 和 linkedList 都存在有明显不足,而quickList则对它们都进行了改进:吸收了zipList 和 linkedList的优点,避开了它们的不足。
quickList 本质上是 zipList 和 linkedList的混合体。其将linkedList按段切分,每一段使用zipList来紧凑存储若干真正的数据元素,多个zipList之间使用双向指针串接起来。当然,对于每个zipList中最多可存放多大容量的数据元素,在配置文件中通过list-max-ziplist-size属性指定。

【补充:为什么不用linkedlist? 链表的附加空间相对太高,prev 和 next指针就要占去16个字节,另外,每个节点的内存都是单独分配,会加剧内存的碎片化,影响内存的管理效率,所以,后来的新版本的redis对列表数据结构进行了改造,使用uickList 代替了 zipList 和 linkedList。】【ziplist,是连续的,所以插入、删除的是昂贵的,对内存空间需要频繁的申请和释放。】
(2)检索操作
对于list元素的检索,都是以其索引index为依据的。quickList由一个个的zipList构成,每个zipList的zllen中记录的就是当前zipList中包含的entry的个数,即包含的真正数据元素的个数。根据要检索元素的index,从quickList的头节点开始,逐个对zipList的zllen做sum求和,直到找到第一个求和后sum大于index的zipList,那么要检索的这个元素就在这个zipList中,只要遍历这个zipList中的entries 即可。
(3)插入操作
由于ziplist是有大小限制的,所以在quick中插入一个元素在逻辑上相对比较复杂一些。
(4)删除操作
删除相对简单,检索,删除即可。但是需要考虑的是,如果ziplist只有一个元素,这个要想到删除后,ziplist就不再包含元素了,要进行ziplist的释放。
6.key 与 value中元素的数量
Redis的各种特殊数据结构的设计,不仅极大提升了Redis的性能,并且还使得Redis可以支持的Key的数量、集合Value中可以支持的元素数量都可以非常庞大。
*** Redis 最多可以处理2^32个key(约42亿),并且在实践中经过测试,每个Redis实例至少可以处理2.5亿个key。
*** 每个Hash、List、Set、ZSet集合都可以包含2^32个元素。
学习参阅声明
【Redis视频从入门到高级】
https://www.bilibili.com/video/BV1U24y1y7jF?p=11&vd_source=0e347fbc6c2b049143afaa5a15abfc1c】

