
InnoDB On-Disk Structures(一)-- Tables (转载)
转载、节选于https://dev.mysql.com/doc/refman/8.0/en/innodb-tables.html
1.InnoDB Architecture
The following diagram shows in-memory and on-disk structures that comprise the InnoDB storage engine architecture.
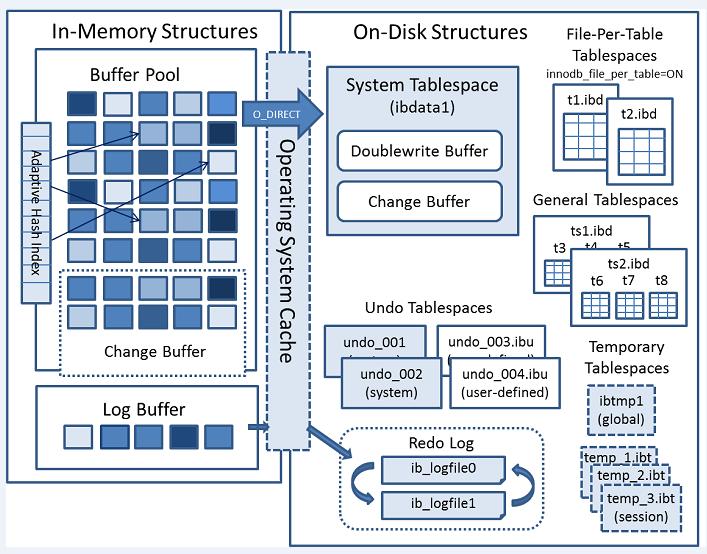
This section covers topics related to InnoDB tables.
2 Creating InnoDB Tables
You do not need to specify the ENGINE=InnoDB clause if InnoDB is defined as the default storage engine, which it is by default.
An InnoDB table and its indexes can be created in the system tablespace, in a file-per-table tablespace, or in a general tablespace. When innodb_file_per_table is enabled, which is the default, an InnoDB table is implicitly created in an individual file-per-table tablespace. Conversely, when innodb_file_per_table is disabled, an InnoDB table is implicitly created in the InnoDB system tablespace. To create a table in a general tablespace, use CREATE TABLE ... TABLESPACE syntax.
When you create a table in a file-per-table tablespace, MySQL creates an .ibd tablespace file in a database directory under the MySQL data directory, by default. A table created in the InnoDB system tablespace is created in an existing ibdata file, which resides in the MySQL data directory. A table created in a general tablespace is created in an existing general tablespace .ibd file. General tablespace files can be created inside or outside of the MySQL data directory.
Internally, InnoDB adds an entry for each table to the data dictionary. The entry includes the database name. For example, if table t1 is created in the test database, the data dictionary entry for the database name is 'test/t1'. This means you can create a table of the same name (t1) in a different database, and the table names do not collide inside InnoDB.
InnoDB Tables and Row Formats
The default row format for InnoDB tables is defined by the innodb_default_row_format configuration option, which has a default value of DYNAMIC. Dynamic andCompressed row format allow you to take advantage of InnoDB features such as table compression and efficient off-page storage of long column values. To use these row formats, innodb_file_per_table must be enabled (the default).
InnoDB Tables and Primary Keys
Always define a primary key for an InnoDB table, specifying the column or columns that:
-
Are referenced by the most important queries.
-
Are never left blank.
-
Never have duplicate values.
-
Rarely if ever change value once inserted.
For example, in a table containing information about people, you would not create a primary key on (firstname, lastname) because more than one person can have the same name, some people have blank last names, and sometimes people change their names. With so many constraints, often there is not an obvious set of columns to use as a primary key, so you create a new column with a numeric ID to serve as all or part of the primary key. You can declare an auto-increment column so that ascending values are filled in automatically as rows are inserted。
# The value of ID can act like a pointer between related items in different tables. CREATE TABLE t5 (id INT AUTO_INCREMENT, b CHAR (20), PRIMARY KEY (id)); # The primary key can consist of more than one column. Any autoinc column must come first. CREATE TABLE t6 (id INT AUTO_INCREMENT, a INT, b CHAR (20), PRIMARY KEY (id,a));
Although the table works correctly without defining a primary key, the primary key is involved with many aspects of performance and is a crucial design aspect for any large or frequently used table. It is recommended that you always specify a primary key in the CREATE TABLE statement. If you create the table, load data, and then run ALTER TABLE to add a primary key later, that operation is much slower than defining the primary key when creating the table.
Viewing InnoDB Table Properties
To view the properties of an InnoDB table, issue a SHOW TABLE STATUS statement:

mysql> SHOW TABLE STATUS FROM test LIKE 't%' \G; *************************** 1. row *************************** Name: t1 Engine: InnoDB Version: 10 Row_format: Compact Rows: 0 Avg_row_length: 0 Data_length: 16384 Max_data_length: 0 Index_length: 0 Data_free: 0 Auto_increment: NULL Create_time: 2015-03-16 15:13:31 Update_time: NULL Check_time: NULL Collation: utf8mb4_0900_ai_ci Checksum: NULL Create_options: Comment:
InnoDB table properties may also be queried using the InnoDB Information Schema system tables:
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME='test/t1' \G *************************** 1. row *************************** TABLE_ID: 45 NAME: test/t1 FLAG: 1 N_COLS: 5 SPACE: 35 ROW_FORMAT: Compact ZIP_PAGE_SIZE: 0 SPACE_TYPE: Single
3.Moving or Copying InnoDB Tables
This section describes techniques for moving or copying some or all InnoDB tables to a different server or instance. For example, you might move an entire MySQL instance to a larger, faster server; you might clone an entire MySQL instance to a new replication slave server; you might copy individual tables to another instance to develop and test an application, or to a data warehouse server to produce reports.
On Windows, InnoDB always stores database and table names internally in lowercase. To move databases in a binary format from Unix to Windows or from Windows to Unix, create all databases and tables using lowercase names. A convenient way to accomplish this is to add the following line to the [mysqld] section of your my.cnf or my.ini file before creating any databases or tables:
[mysqld] lower_case_table_names=1
注意:It is prohibited to start the server with a lower_case_table_names setting that is different from the setting used when the server was initialized.
Techniques for moving or copying InnoDB tables include:
Transportable Tablespaces
The transportable tablespaces feature uses FLUSH TABLES ... FOR EXPORT to ready InnoDB tables for copying from one server instance to another. To use this feature, InnoDB tables must be created with innodb_file_per_table set to ON so that each InnoDB table has its own tablespace.
MySQL Enterprise Backup
The MySQL Enterprise Backup product lets you back up a running MySQL database with minimal disruption to operations while producing a consistent snapshot of the database. When MySQL Enterprise Backup is copying tables, reads and writes can continue. In addition, MySQL Enterprise Backup can create compressed backup files, and back up subsets of tables. In conjunction with the MySQL binary log, you can perform point-in-time recovery. MySQL Enterprise Backup is included as part of the MySQL Enterprise subscription.
Copying Data Files (Cold Backup Method)
InnoDB data and log files are binary-compatible on all platforms having the same floating-point number format. If the floating-point formats differ but you have not usedFLOAT or DOUBLE data types in your tables, then the procedure is the same: simply copy the relevant files.
When you move or copy file-per-table .ibd files, the database directory name must be the same on the source and destination systems. The table definition stored in theInnoDB shared tablespace includes the database name. The transaction IDs and log sequence numbers stored in the tablespace files also differ between databases.
Export and Import (mysqldump)
You can use mysqldump to dump your tables on one machine and then import the dump files on the other machine. Using this method, it does not matter whether the formats differ or if your tables contain floating-point data.
One way to increase the performance of this method is to switch off autocommit mode when importing data, assuming that the tablespace has enough space for the big rollback segment that the import transactions generate. Do the commit only after importing a whole table or a segment of a table.
4.Converting Tables from MyISAM to InnoDB
If you have MyISAM tables that you want to convert to InnoDB for better reliability and scalability, review the following guidelines and tips before converting.
Adjusting Memory Usage for MyISAM and InnoDB
As you transition away from MyISAM tables, lower the value of the key_buffer_size configuration option to free memory no longer needed for caching results. Increase the value of the innodb_buffer_pool_size configuration option, which performs a similar role of allocating cache memory for InnoDB tables. The InnoDB buffer poolcaches both table data and index data, speeding up lookups for queries and keeping query results in memory for reuse.
Handling Too-Long Or Too-Short Transactions
Because MyISAM tables do not support transactions, you might not have paid much attention to the autocommit configuration option and the COMMIT and ROLLBACKstatements. These keywords are important to allow multiple sessions to read and write InnoDB tables concurrently, providing substantial scalability benefits in write-heavy workloads.
While a transaction is open, the system keeps a snapshot of the data as seen at the beginning of the transaction, which can cause substantial overhead if the system inserts, updates, and deletes millions of rows while a stray transaction keeps running. Thus, take care to avoid transactions that run for too long:
-
If you are using a mysql session for interactive experiments, always
COMMIT(to finalize the changes) orROLLBACK(to undo the changes) when finished. Close down interactive sessions rather than leave them open for long periods, to avoid keeping transactions open for long periods by accident. -
Make sure that any error handlers in your application also
ROLLBACKincomplete changes orCOMMITcompleted changes. -
ROLLBACKis a relatively expensive operation, becauseINSERT,UPDATE, andDELETEoperations are written toInnoDBtables prior to theCOMMIT, with the expectation that most changes are committed successfully and rollbacks are rare. When experimenting with large volumes of data, avoid making changes to large numbers of rows and then rolling back those changes. -
When loading large volumes of data with a sequence of
INSERTstatements, periodicallyCOMMITthe results to avoid having transactions that last for hours. In typical load operations for data warehousing, if something goes wrong, you truncate the table (usingTRUNCATE TABLE) and start over from the beginning rather than doing aROLLBACK.
The preceding tips save memory and disk space that can be wasted during too-long transactions. When transactions are shorter than they should be, the problem is excessive I/O. With each COMMIT, MySQL makes sure each change is safely recorded to disk, which involves some I/O.
-
For most operations on
InnoDBtables, you should use the settingautocommit=0. From an efficiency perspective, this avoids unnecessary I/O when you issue large numbers of consecutiveINSERT,UPDATE, orDELETEstatements. From a safety perspective, this allows you to issue aROLLBACKstatement to recover lost or garbled data if you make a mistake on the mysql command line, or in an exception handler in your application. -
The time when
autocommit=1is suitable forInnoDBtables is when running a sequence of queries for generating reports or analyzing statistics. In this situation, there is no I/O penalty related toCOMMITorROLLBACK, andInnoDBcan automatically optimize the read-only workload. -
If you make a series of related changes, finalize all the changes at once with a single
COMMITat the end. For example, if you insert related pieces of information into several tables, do a singleCOMMITafter making all the changes. Or if you run many consecutiveINSERTstatements, do a singleCOMMITafter all the data is loaded; if you are doing millions ofINSERTstatements, perhaps split up the huge transaction by issuing aCOMMITevery ten thousand or hundred thousand records, so the transaction does not grow too large. -
Remember that even a
SELECTstatement opens a transaction, so after running some report or debugging queries in an interactive mysql session, either issue aCOMMITor close the mysql session.
Handling Deadlocks
You might see warning messages referring to “deadlocks” in the MySQL error log, or the output of SHOW ENGINE INNODB STATUS. Despite the scary-sounding name, adeadlock is not a serious issue for InnoDB tables, and often does not require any corrective action. When two transactions start modifying multiple tables, accessing the tables in a different order, they can reach a state where each transaction is waiting for the other and neither can proceed. When deadlock detection is enabled (the default), MySQL immediately detects this condition and cancels (rolls back) the “smaller” transaction, allowing the other to proceed. If deadlock detection is disabled using theinnodb_deadlock_detect configuration option, InnoDB relies on the innodb_lock_wait_timeout setting to roll back transactions in case of a deadlock.
Either way, your applications need error-handling logic to restart a transaction that is forcibly cancelled due to a deadlock. When you re-issue the same SQL statements as before, the original timing issue no longer applies. Either the other transaction has already finished and yours can proceed, or the other transaction is still in progress and your transaction waits until it finishes.
If deadlock warnings occur constantly, you might review the application code to reorder the SQL operations in a consistent way, or to shorten the transactions. You can test with the innodb_print_all_deadlocks option enabled to see all deadlock warnings in the MySQL error log, rather than only the last warning in the SHOW ENGINE INNODB STATUS output.
Planning the Storage Layout
To get the best performance from InnoDB tables, you can adjust a number of parameters related to storage layout.
When you convert MyISAM tables that are large, frequently accessed, and hold vital data, investigate and consider the innodb_file_per_table and innodb_page_sizeconfiguration options, and the ROW_FORMAT and KEY_BLOCK_SIZE clauses of the CREATE TABLE statement.
During your initial experiments, the most important setting is innodb_file_per_table. When this setting is enabled, which is the default, new InnoDB tables are implicitly created in file-per-table tablespaces. In contrast with the InnoDB system tablespace, file-per-table tablespaces allow disk space to be reclaimed by the operating system when a table is truncated or dropped. File-per-table tablespaces also support DYNAMIC and COMPRESSED row formats and associated features such as table compression, efficient off-page storage for long variable-length columns, and large index prefixes.
You can also store InnoDB tables in a shared general tablespace, which support multiple tables and all row formats.
Converting an Existing Table
To convert a non-InnoDB table to use InnoDB use ALTER TABLE:
ALTER TABLE table_name ENGINE=InnoDB;
Cloning the Structure of a Table
You might make an InnoDB table that is a clone of a MyISAM table, rather than using ALTER TABLE to perform conversion, to test the old and new table side-by-side before switching.
Create an empty InnoDB table with identical column and index definitions. Use SHOW CREATE TABLE to see the full table_name\GCREATE TABLE statement to use. Change the ENGINE clause to ENGINE=INNODB.
Transferring Existing Data
To transfer a large volume of data into an empty InnoDB table created as shown in the previous section, insert the rows with INSERT INTO .innodb_table SELECT * FROMmyisam_table ORDER BY primary_key_columns
You can also create the indexes for the InnoDB table after inserting the data. Historically, creating new secondary indexes was a slow operation for InnoDB, but now you can create the indexes after the data is loaded with relatively little overhead from the index creation step.
If you have UNIQUE constraints on secondary keys, you can speed up a table import by turning off the uniqueness checks temporarily during the import operation:
SET unique_checks=0; ... import operation ... SET unique_checks=1;
For big tables, this saves disk I/O because InnoDB can use its change buffer to write secondary index records as a batch. Be certain that the data contains no duplicate keys.unique_checks permits but does not require storage engines to ignore duplicate keys.
For better control over the insertion process, you can insert big tables in pieces:
INSERT INTO newtable SELECT * FROM oldtable WHERE yourkey > something AND yourkey <= somethingelse;
After all records are inserted, you can rename the tables.
During the conversion of big tables, increase the size of the InnoDB buffer pool to reduce disk I/O, to a maximum of 80% of physical memory. You can also increase the size of InnoDB log files.
Storage Requirements
If you intend to make several temporary copies of your data in InnoDB tables during the conversion process, it is recommended that you create the tables in file-per-table tablespaces so that you can reclaim the disk space when you drop the tables. When the innodb_file_per_table configuration option is enabled (the default), newly created InnoDB tables are implicitly created in file-per-table tablespaces.
Whether you convert the MyISAM table directly or create a cloned InnoDB table, make sure that you have sufficient disk space to hold both the old and new tables during the process. InnoDB tables require more disk space than MyISAM tables. If an ALTER TABLE operation runs out of space, it starts a rollback, and that can take hours if it is disk-bound. For inserts, InnoDB uses the insert buffer to merge secondary index records to indexes in batches. That saves a lot of disk I/O. For rollback, no such mechanism is used, and the rollback can take 30 times longer than the insertion.
In the case of a runaway rollback, if you do not have valuable data in your database, it may be advisable to kill the database process rather than wait for millions of disk I/O operations to complete.
Defining a PRIMARY KEY for Each Table
The PRIMARY KEY clause is a critical factor affecting the performance of MySQL queries and the space usage for tables and indexes. The primary key uniquely identifies a row in a table. Every row in the table must have a primary key value, and no two rows can have the same primary key value.
These are guidelines for the primary key, followed by more detailed explanations.
-
Declare a
PRIMARY KEYfor each table. Typically, it is the most important column that you refer to inWHEREclauses when looking up a single row. -
Declare the
PRIMARY KEYclause in the originalCREATE TABLEstatement, rather than adding it later through anALTER TABLEstatement. -
Choose the column and its data type carefully. Prefer numeric columns over character or string ones.
-
Consider using an auto-increment column if there is not another stable, unique, non-null, numeric column to use.
-
An auto-increment column is also a good choice if there is any doubt whether the value of the primary key column could ever change. Changing the value of a primary key column is an expensive operation, possibly involving rearranging data within the table and within each secondary index.
Consider adding a primary key to any table that does not already have one. Use the smallest practical numeric type based on the maximum projected size of the table. This can make each row slightly more compact, which can yield substantial space savings for large tables. The space savings are multiplied if the table has any secondary indexes, because the primary key value is repeated in each secondary index entry. In addition to reducing data size on disk, a small primary key also lets more data fit into the buffer pool, speeding up all kinds of operations and improving concurrency.
If the table already has a primary key on some longer column, such as a VARCHAR, consider adding a new unsigned AUTO_INCREMENT column and switching the primary key to that, even if that column is not referenced in queries. This design change can produce substantial space savings in the secondary indexes. You can designate the former primary key columns as UNIQUE NOT NULL to enforce the same constraints as the PRIMARY KEY clause, that is, to prevent duplicate or null values across all those columns.
If you spread related information across multiple tables, typically each table uses the same column for its primary key. For example, a personnel database might have several tables, each with a primary key of employee number. A sales database might have some tables with a primary key of customer number, and other tables with a primary key of order number. Because lookups using the primary key are very fast, you can construct efficient join queries for such tables.
If you leave the PRIMARY KEY clause out entirely, MySQL creates an invisible one for you. It is a 6-byte value that might be longer than you need, thus wasting space. Because it is hidden, you cannot refer to it in queries.
Application Performance Considerations
The reliability and scalability features of InnoDB require more disk storage than equivalent MyISAM tables. You might change the column and index definitions slightly, for better space utilization, reduced I/O and memory consumption when processing result sets, and better query optimization plans making efficient use of index lookups.
If you do set up a numeric ID column for the primary key, use that value to cross-reference with related values in any other tables, particularly for join queries. For example, rather than accepting a country name as input and doing queries searching for the same name, do one lookup to determine the country ID, then do other queries (or a single join query) to look up relevant information across several tables. Rather than storing a customer or catalog item number as a string of digits, potentially using up several bytes, convert it to a numeric ID for storing and querying. A 4-byte unsigned INT column can index over 4 billion items (with the US meaning of billion: 1000 million).
Understanding Files Associated with InnoDB Tables
InnoDB files require more care and planning than MyISAM files do.You must not delete the ibdata files that represent the InnoDB system tablespace.
5.AUTO_INCREMENT Handling in InnoDB
InnoDB provides a configurable locking mechanism that can significantly improve scalability and performance of SQL statements that add rows to tables with AUTO_INCREMENT columns. To use the AUTO_INCREMENT mechanism with an InnoDB table, an AUTO_INCREMENT column must be defined as part of an index such that it is possible to perform the equivalent of an indexed SELECT MAX( lookup on the table to obtain the maximum column value. Typically, this is achieved by making the column the first column of some table index.ai_col)
InnoDB provides a configurable locking mechanism that can significantly improve scalability and performance of SQL statements that add rows to tables withAUTO_INCREMENT columns. To use the AUTO_INCREMENT mechanism with an InnoDB table, an AUTO_INCREMENT column must be defined as part of an index such that it is possible to perform the equivalent of an indexed SELECT MAX( lookup on the table to obtain the maximum column value. Typically, this is achieved by making the column the first column of some table index.ai_col)
This section describes the behavior of AUTO_INCREMENT lock modes, usage implications for different AUTO_INCREMENT lock mode settings, and how InnoDB initializes theAUTO_INCREMENT counter.
InnoDB AUTO_INCREMENT Lock Modes
This section describes the behavior of AUTO_INCREMENT lock modes used to generate auto-increment values, and how each lock mode affects replication. Auto-increment lock modes are configured at startup using the innodb_autoinc_lock_mode configuration parameter.
The following terms are used in describing innodb_autoinc_lock_mode settings:
-
“
INSERT-like” statementsAll statements that generate new rows in a table, including
INSERT,INSERT ... SELECT,REPLACE,REPLACE ... SELECT, andLOAD DATA. Includes “simple-inserts”,“bulk-inserts”, and “mixed-mode” inserts. -
“Simple inserts”
Statements for which the number of rows to be inserted can be determined in advance (when the statement is initially processed). This includes single-row and multiple-row
INSERTandREPLACEstatements that do not have a nested subquery, but notINSERT ... ON DUPLICATE KEY UPDATE. -
“Bulk inserts”
Statements for which the number of rows to be inserted (and the number of required auto-increment values) is not known in advance. This includes
INSERT ... SELECT,REPLACE ... SELECT, andLOAD DATAstatements, but not plainINSERT.InnoDBassigns new values for theAUTO_INCREMENTcolumn one at a time as each row is processed. -
“Mixed-mode inserts”
These are “simple insert” statements that specify the auto-increment value for some (but not all) of the new rows. An example follows, where
c1is anAUTO_INCREMENTcolumn of tablet1:
INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');
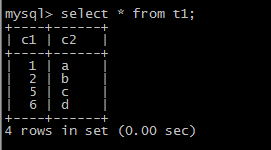
Another type of “mixed-mode insert” is INSERT ... ON DUPLICATE KEY UPDATE, which in the worst case is in effect an INSERT followed by a UPDATE, where the allocated value for the AUTO_INCREMENT column may or may not be used during the update phase.
There are three possible settings for the innodb_autoinc_lock_mode configuration parameter. The settings are 0, 1, or 2, for “traditional”, “consecutive”, or “interleaved”lock mode, respectively. As of MySQL 8.0, interleaved lock mode (innodb_autoinc_lock_mode=2) is the default setting. Prior to MySQL 8.0, consecutive lock mode is the default (innodb_autoinc_lock_mode=1).
The default setting of interleaved lock mode in MySQL 8.0 reflects the change from statement-based replication to row based replication as the default replication type. Statement-based replication requires the consecutive auto-increment lock mode to ensure that auto-increment values are assigned in a predictable and repeatable order for a given sequence of SQL statements, whereas row-based replication is not sensitive to the execution order of SQL statements.
InnoDB AUTO_INCREMENT Lock Mode Usage Implications
-
Using auto-increment with replication
If you are using statement-based replication, set
innodb_autoinc_lock_modeto 0 or 1 and use the same value on the master and its slaves. Auto-increment values are not ensured to be the same on the slaves as on the master if you useinnodb_autoinc_lock_mode= 2 (“interleaved”) or configurations where the master and slaves do not use the same lock mode.If you are using row-based or mixed-format replication, all of the auto-increment lock modes are safe, since row-based replication is not sensitive to the order of execution of the SQL statements (and the mixed format uses row-based replication for any statements that are unsafe for statement-based replication).
-
“Lost” auto-increment values and sequence gaps
In all lock modes (0, 1, and 2), if a transaction that generated auto-increment values rolls back, those auto-increment values are “lost”. Once a value is generated for an auto-increment column, it cannot be rolled back, whether or not the “
INSERT-like” statement is completed, and whether or not the containing transaction is rolled back. Such lost values are not reused. Thus, there may be gaps in the values stored in anAUTO_INCREMENTcolumn of a table. -
Specifying NULL or 0 for the
AUTO_INCREMENTcolumnIn all lock modes (0, 1, and 2), if a user specifies NULL or 0 for the
AUTO_INCREMENTcolumn in anINSERT,InnoDBtreats the row as if the value was not specified and generates a new value for it. -
Assigning a negative value to the
AUTO_INCREMENTcolumnIn all lock modes (0, 1, and 2), the behavior of the auto-increment mechanism is not defined if you assign a negative value to the
AUTO_INCREMENTcolumn. -
If the
AUTO_INCREMENTvalue becomes larger than the maximum integer for the specified integer typeIn all lock modes (0, 1, and 2), the behavior of the auto-increment mechanism is not defined if the value becomes larger than the maximum integer that can be stored in the specified integer type.
-
Gaps in auto-increment values for “bulk inserts”
With
innodb_autoinc_lock_modeset to 0 (“traditional”) or 1 (“consecutive”), the auto-increment values generated by any given statement are consecutive, without gaps, because the table-levelAUTO-INClock is held until the end of the statement, and only one such statement can execute at a time.With
innodb_autoinc_lock_modeset to 2 (“interleaved”), there may be gaps in the auto-increment values generated by “bulk inserts,” but only if there are concurrently executing “INSERT-like” statements.For lock modes 1 or 2, gaps may occur between successive statements because for bulk inserts the exact number of auto-increment values required by each statement may not be known and overestimation is possible.
-
Auto-increment values assigned by “mixed-mode inserts”
Consider a “mixed-mode insert,” where a “simple insert” specifies the auto-increment value for some (but not all) resulting rows. Such a statement behaves differently in lock modes 0, 1, and 2. For example, assume
c1is anAUTO_INCREMENTcolumn of tablet1, and that the most recent automatically generated sequence number is 100.
mysql> CREATE TABLE t1 ( -> c1 INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, -> c2 CHAR(1) -> ) ENGINE = INNODB;
Now, consider the following “mixed-mode insert” statement:
mysql> INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (5,'c'), (NULL,'d');
With innodb_autoinc_lock_mode set to 0 (“traditional”), the four new rows are:
mysql> SELECT c1, c2 FROM t1 ORDER BY c2; +-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | 101 | b | | 5 | c | | 102 | d | +-----+------+
The next available auto-increment value is 103 because the auto-increment values are allocated one at a time, not all at once at the beginning of statement execution. This result is true whether or not there are concurrently executing “INSERT-like” statements (of any type).
With innodb_autoinc_lock_mode set to 1 (“consecutive”), the four new rows are also:
mysql> SELECT c1, c2 FROM t1 ORDER BY c2; +-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | 101 | b | | 5 | c | | 102 | d | +-----+------+
However, in this case, the next available auto-increment value is 105, not 103 because four auto-increment values are allocated at the time the statement is processed, but only two are used. This result is true whether or not there are concurrently executing “INSERT-like” statements (of any type).
With innodb_autoinc_lock_mode set to mode 2 (“interleaved”), the four new rows are:
mysql> SELECT c1, c2 FROM t1 ORDER BY c2; +-----+------+ | c1 | c2 | +-----+------+ | 1 | a | | x | b | | 5 | c | | y | d | +-----+------+
The values of x and y are unique and larger than any previously generated rows. However, the specific values of x and y depend on the number of auto-increment values generated by concurrently executing statements.
Finally, consider the following statement, issued when the most-recently generated sequence number is 100:
mysql> INSERT INTO t1 (c1,c2) VALUES (1,'a'), (NULL,'b'), (101,'c'), (NULL,'d');
With any innodb_autoinc_lock_mode setting, this statement generates a duplicate-key error 23000 (Can't write; duplicate key in table) because 101 is allocated for the row (NULL, 'b') and insertion of the row (101, 'c') fails.
-
Modifying
AUTO_INCREMENTcolumn values in the middle of a sequence ofINSERTstatements
In MySQL 5.7 and earlier, modifying an AUTO_INCREMENT column value in the middle of a sequence of INSERT statements could lead to “Duplicate entry” errors. For example, if you performed an UPDATE operation that changed an AUTO_INCREMENT column value to a value larger than the current maximum auto-increment value, subsequent INSERT operations that did not specify an unused auto-increment value could encounter “Duplicate entry” errors. In MySQL 8.0 and later, if you modify anAUTO_INCREMENT column value to a value larger than the current maximum auto-increment value, the new value is persisted, and subsequent INSERT operations allocate auto-increment values starting from the new, larger value. This behavior is demonstrated in the following example.
mysql> CREATE TABLE t1 ( -> c1 INT NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (c1) -> ) ENGINE = InnoDB; mysql> INSERT INTO t1 VALUES(0), (0), (3); mysql> SELECT c1 FROM t1; +----+ | c1 | +----+ | 1 | | 2 | | 3 | +----+ mysql> UPDATE t1 SET c1 = 4 WHERE c1 = 1; mysql> SELECT c1 FROM t1; +----+ | c1 | +----+ | 2 | | 3 | | 4 | +----+ mysql> INSERT INTO t1 VALUES(0); mysql> SELECT c1 FROM t1; +----+ | c1 | +----+ | 2 | | 3 | | 4 | | 5 | +----+
InnoDB AUTO_INCREMENT Counter Initialization
This section describes how InnoDB initializes AUTO_INCREMENT counters.
If you specify an AUTO_INCREMENT column for an InnoDB table, the in-memory table object contains a special counter called the auto-increment counter that is used when assigning new values for the column.
In MySQL 5.7 and earlier, the auto-increment counter is stored only in main memory, not on disk. To initialize an auto-increment counter after a server restart, InnoDBwould execute the equivalent of the following statement on the first insert into a table containing an AUTO_INCREMENT column.
SELECT MAX(ai_col) FROM table_name FOR UPDATE;
In MySQL 8.0, this behavior is changed. The current maximum auto-increment counter value is written to the redo log each time it changes and is saved to an engine-private system table on each checkpoint. These changes make the current maximum auto-increment counter value persistent across server restarts.
On a server restart following a normal shutdown, InnoDB initializes the in-memory auto-increment counter using the current maximum auto-increment value stored in the data dictionary system table.
On a server restart during crash recovery, InnoDB initializes the in-memory auto-increment counter using the current maximum auto-increment value stored in the data dictionary system table and scans the redo log for auto-increment counter values written since the last checkpoint. If a redo-logged value is greater than the in-memory counter value, the redo-logged value is applied. However, in the case of a server crash, reuse of a previously allocated auto-increment value cannot be guaranteed. Each time the current maximum auto-increment value is changed due to an INSERT or UPDATE operation, the new value is written to the redo log, but if the crash occurs before the redo log is flushed to disk, the previously allocated value could be reused when the auto-increment counter is initialized after the server is restarted.
The only circumstance in which InnoDB uses the equivalent of a SELECT MAX(ai_col) FROM statement in MySQL 8.0 and later to initialize an auto-increment counter is when importing a tablespace without a table_name FOR UPDATE.cfg metadata file. Otherwise, the current maximum auto-increment counter value is read from the .cfgmetadata file.
In MySQL 5.7 and earlier, a server restart cancels the effect of the AUTO_INCREMENT = N table option, which may be used in a CREATE TABLE or ALTER TABLE statement to set an initial counter value or alter the existing counter value, respectively. In MySQL 8.0, a server restart does not cancel the effect of the AUTO_INCREMENT = N table option. If you initialize the auto-increment counter to a specific value, or if you alter the auto-increment counter value to a larger value, the new value is persisted across server restarts.
注意:ALTER TABLE ... AUTO_INCREMENT = N can only change the auto-increment counter value to a value larger than the current maximum.
In MySQL 5.7 and earlier, a server restart immediately following a ROLLBACK operation could result in the reuse of auto-increment values that were previously allocated to the rolled-back transaction, effectively rolling back the current maximum auto-increment value. In MySQL 8.0, the current maximum auto-increment value is persisted, preventing the reuse of previously allocated values.
If a SHOW TABLE STATUS statement examines a table before the auto-increment counter is initialized, InnoDB opens the table and initializes the counter value using the current maximum auto-increment value that is stored in the data dictionary system table. The value is stored in memory for use by later inserts or updates. Initialization of the counter value uses a normal exclusive-locking read on the table which lasts to the end of the transaction. InnoDB follows the same procedure when initializing the auto-increment counter for a newly created table that has a user-specified auto-increment value that is greater than 0.
After the auto-increment counter is initialized, if you do not explicitly specify an auto-increment value when inserting a row, InnoDB implicitly increments the counter and assigns the new value to the column. If you insert a row that explicitly specifies an auto-increment column value, and the value is greater than the current maximum counter value, the counter is set to the specified value.
InnoDB uses the in-memory auto-increment counter as long as the server runs. When the server is stopped and restarted, InnoDB reinitializes the auto-increment counter, as described earlier.
The auto_increment_offset configuration option determines the starting point for the AUTO_INCREMENT column value. The default setting is 1.
The auto_increment_increment configuration option controls the interval between successive column values. The default setting is 1.
6.InnoDB and FOREIGN KEY Constraints
How the InnoDB storage engine handles foreign key constraints is described under the following topics in this section。
Foreign Key Definitions
Foreign key definitions for InnoDB tables are subject to the following conditions:
-
InnoDBpermits a foreign key to reference any index column or group of columns. However, in the referenced table, there must be an index where the referenced columns are the first columns in the same order. Hidden columns thatInnoDBadds to an index are also considered . -
InnoDBdoes not currently support foreign keys for tables with user-defined partitioning. This means that no user-partitionedInnoDBtable may contain foreign key references or columns referenced by foreign keys. -
InnoDBallows a foreign key constraint to reference a nonunique key. This is anInnoDBextension to standard SQL.
Referential Actions
Referential actions for foreign keys of InnoDB tables are subject to the following conditions:
-
While
SET DEFAULTis allowed by the MySQL Server, it is rejected as invalid byInnoDB.CREATE TABLEandALTER TABLEstatements using this clause are not allowed for InnoDB tables. -
If there are several rows in the parent table that have the same referenced key value,
InnoDBacts in foreign key checks as if the other parent rows with the same key value do not exist. For example, if you have defined aRESTRICTtype constraint, and there is a child row with several parent rows,InnoDBdoes not permit the deletion of any of those parent rows. -
InnoDBperforms cascading operations through a depth-first algorithm, based on records in the indexes corresponding to the foreign key constraints. -
If
ON UPDATE CASCADEorON UPDATE SET NULLrecurses to update the same table it has previously updated during the cascade, it acts likeRESTRICT. This means that you cannot use self-referentialON UPDATE CASCADEorON UPDATE SET NULLoperations. This is to prevent infinite loops resulting from cascaded updates. A self-referentialON DELETE SET NULL, on the other hand, is possible, as is a self-referentialON DELETE CASCADE. Cascading operations may not be nested more than 15 levels deep. -
Like MySQL in general, in an SQL statement that inserts, deletes, or updates many rows,
InnoDBchecksUNIQUEandFOREIGN KEYconstraints row-by-row. When performing foreign key checks,InnoDBsets shared row-level locks on child or parent records it has to look at.InnoDBchecks foreign key constraints immediately; the check is not deferred to transaction commit. According to the SQL standard, the default behavior should be deferred checking. That is, constraints are only checked after the entire SQL statement has been processed. UntilInnoDBimplements deferred constraint checking, some things are impossible, such as deleting a record that refers to itself using a foreign key.
Foreign Key Restrictions for Generated Columns and Virtual Indexes
-
A foreign key constraint on a stored generated column cannot use
CASCADE,SET NULL, orSET DEFAULTasON UPDATEreferential actions, nor can it useSET NULLorSET DEFAULTasON DELETEreferential actions. -
A foreign key constraint on the base column of a stored generated column cannot use
CASCADE,SET NULL, orSET DEFAULTasON UPDATEorON DELETEreferential actions. -
A foreign key constraint cannot reference a virtual generated column.
-
Prior to MySQL 8.0, a foreign key constraint cannot reference a secondary index defined on a virtual generated column.
7.Limits on InnoDB Tables
Limits on InnoDB tables are described under the following topics in this section.
Maximums and Minimums
-
A table can contain a maximum of 1017 columns. Virtual generated columns are included in this limit.
-
A table can contain a maximum of 64 secondary indexes.
-
The index key prefix length limit is 3072 bytes for
InnoDBtables that useDYNAMICorCOMPRESSEDrow format.The index key prefix length limit is 767 bytes for
InnoDBtables that useREDUNDANTorCOMPACTrow format. For example, you might hit this limit with a column prefixindex of more than 191 characters on aTEXTorVARCHARcolumn, assuming autf8mb4character set and the maximum of 4 bytes for each character.Attempting to use an index key prefix length that exceeds the limit returns an error.
The limits that apply to index key prefixes also apply to full-column index keys.
-
If you reduce the
InnoDBpage size to 8KB or 4KB by specifying theinnodb_page_sizeoption when creating the MySQL instance, the maximum length of the index key is lowered proportionally, based on the limit of 3072 bytes for a 16KB page size. That is, the maximum index key length is 1536 bytes when the page size is 8KB, and 768 bytes when the page size is 4KB. -
A maximum of 16 columns is permitted for multicolumn indexes. Exceeding the limit returns an error.
ERROR 1070 (42000): Too many key parts specified; max 16 parts allowed
-
The maximum row length, except for variable-length columns (
VARBINARY,VARCHAR,BLOBandTEXT), is slightly less than half of a page for 4KB, 8KB, 16KB, and 32KB page sizes. For example, the maximum row length for the defaultinnodb_page_sizeof 16KB is about 8000 bytes. However, for anInnoDBpage size of 64KB, the maximum row length is approximately 16000 bytes.LONGBLOBandLONGTEXTcolumns must be less than 4GB, and the total row length, includingBLOBandTEXTcolumns, must be less than 4GB.If a row is less than half a page long, all of it is stored locally within the page. If it exceeds half a page, variable-length columns are chosen for external off-page storage until the row fits within half a page, as described in Section 15.11.2, “File Space Management”.
-
Although
InnoDBsupports row sizes larger than 65,535 bytes internally, MySQL itself imposes a row-size limit of 65,535 for the combined size of all columns:
mysql> CREATE TABLE t (a VARCHAR(8000), b VARCHAR(10000), -> c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000), -> f VARCHAR(10000), g VARCHAR(10000)) ENGINE=InnoDB; ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs
-
On some older operating systems, files must be less than 2GB. This is not a limitation of
InnoDBitself, but if you require a large tablespace, configure it using several smaller data files rather than one large data file. -
The combined size of the
InnoDBlog files can be up to 512GB. -
The minimum tablespace size is slightly larger than 10MB. The maximum tablespace size depends on the
InnoDBpage size.
| InnoDB Page Size | Maximum Tablespace Size |
|---|---|
| 4KB | 16TB |
| 8KB | 32TB |
| 16KB | 64TB |
| 32KB | 128TB |
| 64KB | 256TB |
-
The maximum tablespace size is also the maximum size for a table.
-
The path of a tablespace file, including the file name, cannot exceed the
MAX_PATHlimit on Windows. Prior to Windows 10, theMAX_PATHlimit is 260 characters. As of Windows 10, version 1607,MAX_PATHlimitations are removed from common Win32 file and directory functions, but you must enable the new behavior. -
The default page size in
InnoDBis 16KB. You can increase or decrease the page size by configuring theinnodb_page_sizeoption when creating the MySQL instance.32KB and 64KB page sizes are supported, but
ROW_FORMAT=COMPRESSEDis unsupported for page sizes greater than 16KB. For both 32KB and 64KB page sizes, the maximum record size is 16KB. Forinnodb_page_size=32KB, extent size is 2MB. Forinnodb_page_size=64KB, extent size is 4MB.A MySQL instance using a particular
InnoDBpage size cannot use data files or log files from an instance that uses a different page size.
Restrictions on InnoDB Tables
-
ANALYZE TABLEdetermines index cardinality (as displayed in theCardinalitycolumn ofSHOW INDEXoutput) by performing random dives on each of the index trees and updating index cardinality estimates accordingly. Because these are only estimates, repeated runs ofANALYZE TABLEcould produce different numbers. This makesANALYZE TABLEfast onInnoDBtables but not 100% accurate because it does not take all rows into account.You can make the statistics collected by
ANALYZE TABLEmore precise and more stable by turning on theinnodb_stats_persistentconfiguration option, as explained in Section 15.8.10.1, “Configuring Persistent Optimizer Statistics Parameters”. When that setting is enabled, it is important to runANALYZE TABLEafter major changes to indexed column data, because the statistics are not recalculated periodically (such as after a server restart).If the persistent statistics setting is enabled, you can change the number of random dives by modifying the
innodb_stats_persistent_sample_pagessystem variable. If the persistent statistics setting is disabled, modify theinnodb_stats_transient_sample_pagessystem variable instead.MySQL uses index cardinality estimates in join optimization. If a join is not optimized in the right way, try using
ANALYZE TABLE. In the few cases thatANALYZE TABLEdoes not produce values good enough for your particular tables, you can useFORCE INDEXwith your queries to force the use of a particular index, or set themax_seeks_for_keysystem variable to ensure that MySQL prefers index lookups over table scans. See Section B.4.5, “Optimizer-Related Issues”. -
If statements or transactions are running on a table, and
ANALYZE TABLEis run on the same table followed by a secondANALYZE TABLEoperation, the secondANALYZE TABLEoperation is blocked until the statements or transactions are completed. This behavior occurs becauseANALYZE TABLEmarks the currently loaded table definition as obsolete whenANALYZE TABLEis finished running. New statements or transactions (including a secondANALYZE TABLEstatement) must load the new table definition into the table cache, which cannot occur until currently running statements or transactions are completed and the old table definition is purged. Loading multiple concurrent table definitions is not supported. -
SHOW TABLE STATUSdoes not give accurate statistics onInnoDBtables except for the physical size reserved by the table. The row count is only a rough estimate used in SQL optimization. -
InnoDBdoes not keep an internal count of rows in a table because concurrent transactions might “see” different numbers of rows at the same time. Consequently,SELECT COUNT(*)statements only count rows visible to the current transaction. -
On Windows,
InnoDBalways stores database and table names internally in lowercase. To move databases in a binary format from Unix to Windows or from Windows to Unix, create all databases and tables using lowercase names. -
An
AUTO_INCREMENTcolumnai_colmust be defined as part of an index such that it is possible to perform the equivalent of an indexedSELECT MAX(lookup on the table to obtain the maximum column value. Typically, this is achieved by making the column the first column of some table index.ai_col)
-
When an
AUTO_INCREMENTinteger column runs out of values, a subsequentINSERToperation returns a duplicate-key error. This is general MySQL behavior. -
DELETE FROMdoes not regenerate the table but instead deletes all rows, one by one.tbl_name -
Cascaded foreign key actions do not activate triggers.
-
You cannot create a table with a column name that matches the name of an internal
InnoDBcolumn (includingDB_ROW_ID,DB_TRX_ID,DB_ROLL_PTR, andDB_MIX_ID). This restriction applies to use of the names in any letter case.
mysql> CREATE TABLE t1 (c1 INT, db_row_id INT) ENGINE=INNODB; ERROR 1166 (42000): Incorrect column name 'db_row_id'
Locking and Transactions
-
LOCK TABLESacquires two locks on each table ifinnodb_table_locks=1(the default). In addition to a table lock on the MySQL layer, it also acquires anInnoDBtable lock. Versions of MySQL before 4.1.2 did not acquireInnoDBtable locks; the old behavior can be selected by settinginnodb_table_locks=0. If noInnoDBtable lock is acquired,LOCK TABLEScompletes even if some records of the tables are being locked by other transactions.In MySQL 8.0,
innodb_table_locks=0has no effect for tables locked explicitly withLOCK TABLES ... WRITE. It does have an effect for tables locked for read or write byLOCK TABLES ... WRITEimplicitly (for example, through triggers) or byLOCK TABLES ... READ. -
All
InnoDBlocks held by a transaction are released when the transaction is committed or aborted. Thus, it does not make much sense to invokeLOCK TABLESonInnoDBtables inautocommit=1mode because the acquiredInnoDBtable locks would be released immediately. -
You cannot lock additional tables in the middle of a transaction because
LOCK TABLESperforms an implicitCOMMITandUNLOCK TABLES.
转载、节选于https://dev.mysql.com/doc/refman/8.0/en/innodb-tables.html


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库