
搭建 Telegraf + InfluxDB + Grafana 监控遇到几个小问题
1:如果同一台服务器上安装有多个MongoDB实例,telegraf.conf 中关于 MongoDB 如何配置?配置数据在【INPUT PLUGINS的[[inputs.mongodb]]】部分。
单个实例配置
servers = ["mongodb://UID:PWD@XXX.XXX.XXX.124:27218"]
错误的多实例配置(例如两个实例);
servers = ["mongodb://UID:PWD@XXX.XXX.XXX.124:27218"] servers = ["mongodb://UID:PWD@XXX0.XXX.XXX.124:27213"]
重启服务,查看服务状态,提示错误信息如下;
Failed to start The plugin-driven server agent for reporting metrics into InfluxDB.

正确的配置应该为;
servers = ["mongodb://UID:PWD@XXX.XXX.XXX.124:27213","mongodb://UID:PWD@XXX.XXX.XXX.124:27218"]
2.配置Grafana 告警规则后,发现只是告警一次,后面恢复后再报警一次。即异常持续期间没有一直告警。
解决办法,这个设置其实在【Alterting】--》【Notification channels】-->【Send reminders】

例如以下的设置可以理解为,每5分钟触发一下告警信息。

3.告警检查显示没有数据。

这个时候有两种原因
(1)收集监控项的代理程序有问题 ;
(2)或者是代理程序没问题,是汇报数据不及时的问题。
针对第二问题,我们可以调整代理程序执行频率;如果实时性要求不是很高,还可以调整告警规则检查数据的时间范围。
例如,我们可以从检查 过去5分钟到过去1分钟内的数据,调整为过去10分钟到过去5分钟内的数据。对应的设置如下:
调整前;

调整后
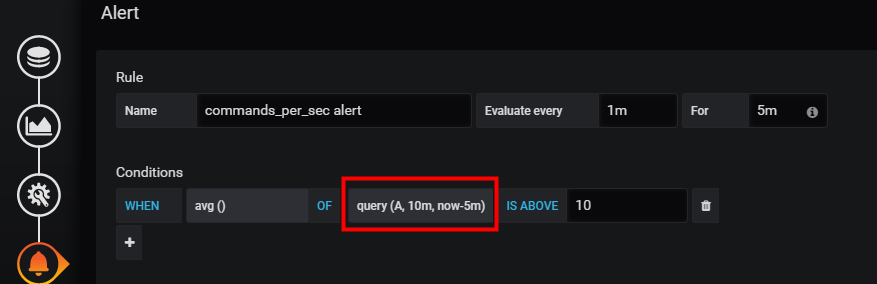
4.随着需要监控的子项的增多,收集时间必然增多,需要调整运行周期。
否则,报错信息如下;
telegraf[2908]: 2019-03-01T02:40:46Z E! Error in plugin [inputs.mysql]: took longer to collect than collection interval (10s)
解决方案:调整 telegraf.conf 文件中 [agent] 部分的interval参数。
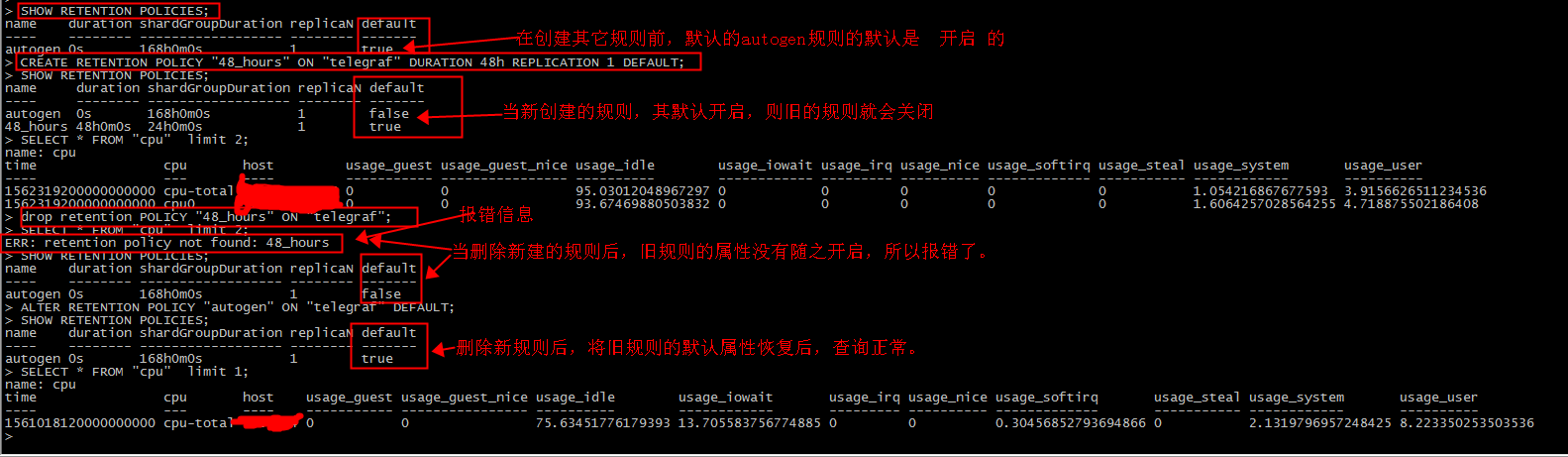
5.InfluxDB 既有的规则不建议删除,删除后查询写入都报错。
例如我们创建了如下一个规则:
CREATE RETENTION POLICY "48_hours" ON "telegraf" DURATION 48h REPLICATION 1 DEFAULT;
查看规则的命令:
SHOW RETENTION POLICIES;
然后执行删除命令
drop retention POLICY "48_hours" ON "telegraf";
查询数据,提示以下错误;
ERR: retention policy not found: 48_hours
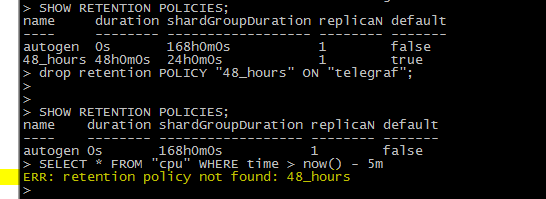
查看各个telegraf收集器,也开始报错了。

基础知识

| 字段 | 解释说明 |
| name | 名称, 此示例名称为autogen |
| duration | 持续时间, 0代表无限制 |
| shardGroupDuration | shardGroup的存储时间, shardGroup是InfluxDB的一个基本存储结构, 应该大于这个时间的数据在查询效率上应该有所降低 |
| replicaN | 全称是REPLICATION, 副本个数 |
| default | 是否是默认策略 |
解决方案;
新建的策略为默认策略,删除后没有了默认策略,要将一个策略设置为默认策略。
本例是将原来的autogen策略恢复为true,下面是完整的测试过程。
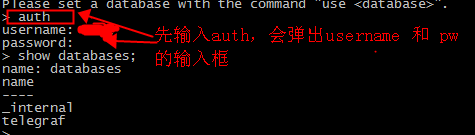
6.InfluxDB设置登入账号后,如何auth验证。
登入后,需要进行Auth验证,否则命令无法正常执行,报错如下:
ERR: unable to parse authentication credentials
需要输入,auth 命令,再分别输入账号命名即可。
7. Grafana 关于报警邮件的配置
(1)我们明明配置了SMTP,但是提示错误:
"Failed to send alert notification email" logger=alerting.notifier.email error="SMTP not configured, check your grafana.ini config file's [smtp] section"
原因是:grafana.ini文件中,很多行的注释符是(;)

(2)与配置Linux系统的邮件服务不同,需要添加端口。(例如,添加25);否则报错:
"Failed to send alert notification email" logger=alerting.notifier.email error="address ygmail.yiguo.com: missing port in address"
(3)如无特别需要,请将skip_verify 设置为true。否则报错:
"Failed to send alert notification email" logger=alerting.notifier.email error="x509: certificate is valid for XXXXXX"
因此,grafana.ini中关于邮件部分的配置格式如下;

#################################### SMTP / Emailing ########################## [smtp] enabled = true host = 邮件服务(地址):port user = 用户名 # If the password contains # or ; you have to wrap it with trippel quotes. Ex """#password;""" password = XXXXXXX ;cert_file = ;key_file = skip_verify = true from_address = 告警邮件的地址 from_name = Grafana [emails] ;welcome_email_on_sign_up = false
8.我们在搭建收集log的系统时,下载logstatsh,验证报错
验证代码:
bin/logstash -e 'input { stdin { } } output { stdout {} }'

which: no java in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin) could not find java; set JAVA_HOME or ensure java is in PATH
解决方案:
yum install java
再次验证:
[root@QQWeiXin—0081 logstash-6.2.4]# bin/logstash -e 'input { stdin { } } output { stdout {} }' Sending Logstash's logs to /data/logstash/logstash-6.2.4/logs which is now configured via log4j2.properties [2018-09-23T17:29:46,228][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/data/logstash/logstash-6.2.4/modules/fb_apache/configuration"} [2018-09-23T17:29:46,243][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/data/logstash/logstash-6.2.4/modules/netflow/configuration"} [2018-09-23T17:29:46,335][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/data/logstash/logstash-6.2.4/data/queue"} [2018-09-23T17:29:46,342][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/data/logstash/logstash-6.2.4/data/dead_letter_queue"} [2018-09-23T17:29:46,661][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified [2018-09-23T17:29:46,702][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"c9e6fd92-0171-4a2b-87e5-36b98c21db16", :path=>"/data/logstash/logstash-6.2.4/data/uuid"} [2018-09-23T17:29:47,274][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.2.4"} [2018-09-23T17:29:47,607][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600} [2018-09-23T17:29:49,568][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>40, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50} [2018-09-23T17:29:49,739][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x718a7b78 sleep>"} The stdin plugin is now waiting for input: [2018-09-23T17:29:49,815][INFO ][logstash.agent ] Pipelines running {:count=>1, :pipelines=>["main"]} { "message" => "", "@version" => "1", "@timestamp" => 2018-09-23T09:30:24.535Z, "host" => "QQWeiXin—0081" } { "message" => "", "@version" => "1", "@timestamp" => 2018-09-23T09:30:24.969Z, "host" => "QQWeiXin—0081" } { "message" => "", "@version" => "1", "@timestamp" => 2018-09-23T09:30:25.189Z, "host" => "QQWeiXin—0081" }
9.InfluxDB WHERE 子句
(1)在WHERE子句中,支持在fields, tags, and timestamps上进行条件表达式的运算。不支持使用 OR 来指定不同的time区间。
(2) 在WHERE子句中,支持对string, boolean, float 和 integer类型的field values进行比较。
在WHERE子句中,如果是string类型的field value,一定要用单引号括起来。如果不适用引号括起来,或者使用的是双引号,将不会返回任何数据,有时甚至都不报错!
10.grafana 启动域账号登入
Step 1 修改 grafana.ini 配置文件,启动调整以下参数

Step 2 重启下 grafana-server.service 服务
systemctl stop grafana-server.service systemctl start grafana-server.service systemctl status grafana-server.service
如果没有 ldap.toml 文件,重启会生成
step 3 修改ldap.toml文件
[[servers]] host = "xxx.xxx.xxx.xxx" start_tls = true ssl_skip_verify = true bind_dn = "CORP\\%s" #bind_dn = "CORP\\testuser" 双斜杠一定要有,%s使用具体的AD账户 bind_password = 'xxxxxxx' search_filter = "(sAMAccountName=%s)" search_base_dns = ["dc=corp,dc=local"] bind_password = '********' [servers.attributes] name = "givenName" surname = "sn" username = "XXXXX" member_of = "memberOf" email = "mail" [[servers.group_mappings]] group_dn = "cn=admins,dc=grafana,dc=org" org_role = "Admin" [[servers.group_mappings]] group_dn = "cn=users,dc=grafana,dc=org" org_role = "Editor"
step 4 重启下 grafana-server.service 服务
11:监控MongoDB 副本集节点,telegraf账号的权限设置
设置不当,报错如下:
Jan 21 17:06:00 XXXX-mongodb02 telegraf[77945]: 2019-01-21T09:06:00Z E! Error in plugin [inputs.mongodb]: not authorized on admin to execute command { serverStatus: 1, recordStats: 0, $readPreference: { mode: "secondaryPreferred" }, $db: "admin" } Jan 21 17:06:00 XXXX-mongodb02 telegraf[77945]: 2019-01-21T09:06:00Z E! Error in plugin [inputs.mongodb]: not authorized on admin to execute command { serverStatus: 1, recordStats: 0, $readPreference: { mode: "secondaryPreferred" }, $db: "admin" }
解决方案:
db.createUser({user:"uid_XXXXX", pwd:"PWD_??????",roles: [ {role: "clusterMonitor",db: "admin"}] })

12.Grafana 图形最大值、最小值、平均值的设置
在编辑-->Legend 处设置,要记得保存。

设置后的显示

13. CPU的IOWait 指标不准确的问题
IOWait 是Sever 性能的一个关键指标,可以用来参考磁盘IO性能、是否有僵尸进程等。
但有的同学配置的时候,会发现grafana 显示的iowait 与真实值(或者Zabbix)比较放大了好几倍。
原因是查看Telegraf 收集到的CPU数据需要指定cpu 的数据类型。
转换成SQL来看,有问题的SQL如下:
select last("usage_iowait") From "cpu" WHERE ("host" =~/^$host$/ ) and $timeFilter GROUP BY time(10s)fill(null)
调整后的SQL
select last("usage_iowait") From "cpu" WHERE ("host" =~/^$host$/ AND "cpu" ='cpu-total') and $timeFilter GROUP BY time(10s)fill(null)
调整后,显示的数据OK了。
即,显示IOWait数据,在条件中一定要指定 "cpu" ='cpu-total' 。
14.通过telegraf监控收集端口+域名(或IP)联通性(ping)数据
### step 1 监控指定端口,例如监控本地端口号7788,修改配置文件。
sed -i 's/localhost:80/localhost:7788/' /etc/telegraf/telegraf.conf
### step 2 启用监控ping; 用\转义: 把\字符放在特殊字符的前面,例如将##[[inputs.ping]] 替换为[[inputs.ping]]
sed -i 's/\#\#\[\[inputs.ping\]\]/\[\[inputs.ping\]\]/' /etc/telegraf/telegraf.conf
### step 3 ping 命令指定特定域名 ,即将文件中的# urls = ["example.org"] 替换为 urls = ["指定域名"]
sed -i 's/\# urls = \[\"example.org\"\]/ urls = \[\"指定域名或IP\"\]/' /etc/telegraf/telegraf.conf
数据存储在influxDB数据库中,端口信息保存在了net_response中,字段为result_code;ping信息保存在了ping表中,字段也是 result_code。
15.MySQL数据库部分指标说明
指标主要来自系统表和 show global status数据。
例如QPS的计算公式
questions = show global status where variable_name='Queries'; uptime = show global status like 'Uptime'; qps=questions/uptime
相应的值也可以从系统表中获取,SQL语句;
select * from performance_schema.global_status where variable_name in ('Queries','Uptime');
TPS的计算公式,获取TPS指标的方式有两种:
(1)基于com_commit、com_rollback计算tps
com_commit = show global status where variable_name='com_commit'; com_rollback = show global status where variable_name='com_rollback'; uptime = show global status where Variable_name='Uptime'; tps=(com_commit + com_rollback)/uptime
(2)基于com_insert、com_delete、com_update的status,变量计算tps
Com_update: MySQL从上一次启动到当前所执行的更新语句总数量Com_delete:MySQL从上一次启动到当前所执行的删除语句总数量Com_insert:MySQL从上一次启动到当前所执行的插入语句总数量
#/usr/bin/env bash OLD_COM_INSERT=`echo "show global status where Variable_name='Com_insert';"|mysql --defaults-file=./.my.cnf -N|awk '{print $2}'` OLD_COM_UPDATE=`echo "show global status where Variable_name='Com_update';"|mysql --defaults-file=./.my.cnf -N|awk '{print $2}'` OLD_COM_DELETE=`echo "show global status where Variable_name='Com_delete';"|mysql --defaults-file=./.my.cnf -N|awk '{print $2}'` sleep $1 NEW_COM_INSERT=`echo "show global status where Variable_name='Com_insert';"|mysql --defaults-file=./.my.cnf -N|awk '{print $2}'` NEW_COM_UPDATE=`echo "show global status where Variable_name='Com_update';"|mysql --defaults-file=./.my.cnf -N|awk '{print $2}'` NEW_COM_DELETE=`echo "show global status where Variable_name='Com_delete';"|mysql --defaults-file=./.my.cnf -N|awk '{print $2}'` echo "(($NEW_COM_INSERT - $OLD_COM_INSERT) + ($NEW_COM_UPDATE - $OLD_COM_UPDATE) + ($NEW_COM_DELETE - $OLD_COM_DELETE)) / $1" | bc
关于指标更详细的内容,请参照 《MySQL监控》 https://zhuanlan.zhihu.com/p/441831281
参考资料:
https://grafana.com/docs/grafana/latest/auth/ldap/


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库