

第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 学习使用github发布程序文件并控制更新,练习使用PSP表格,练习单元测试,同时过程中养成良好编程风格 |
我的github仓库地址:https://github.com/xulingduo/3122004540/releases/tag/test1
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 600 | |
| Development | 开发 | 690 | 620 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 120 |
| · Design Spec | · 生成设计文档 | 60 | 60 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 40 |
| · Coding | · 具体编码 | 240 | 200 |
| · Code Review | · 代码复审 | 30 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 60 | 60 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 15 |
| · 合计 | 770 | 700 |
计算模块接口的设计与实现过程
·类:Main:存放main函数和需调用的方法。
·函数:
1、Split(String filename):输入文件路径,读取内容后通过分词器生成词组。
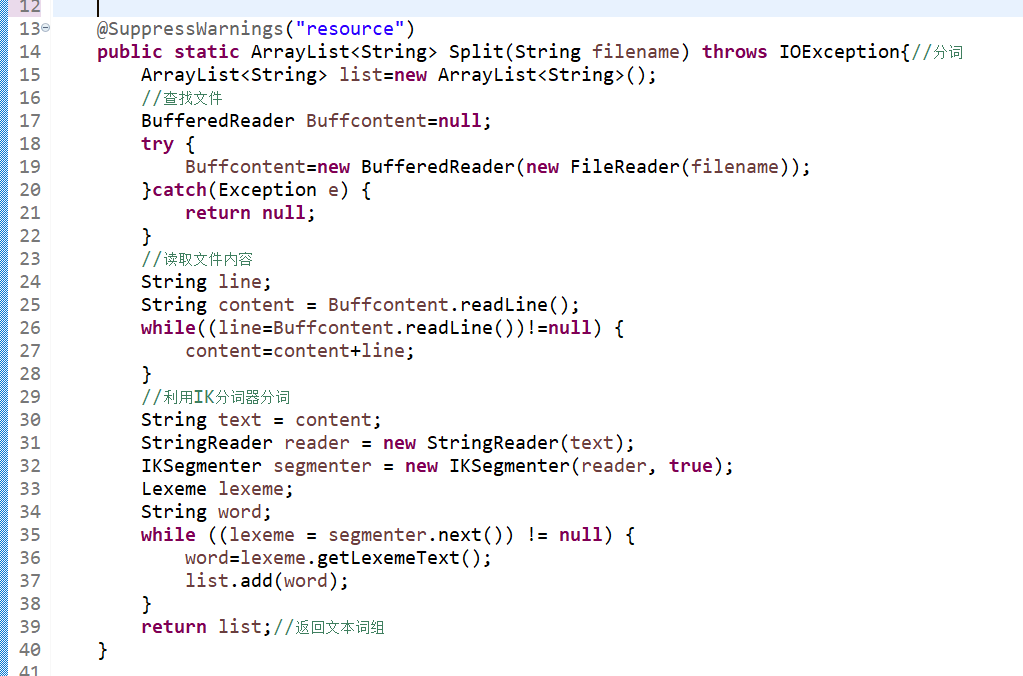
2、ComList(ArrayList
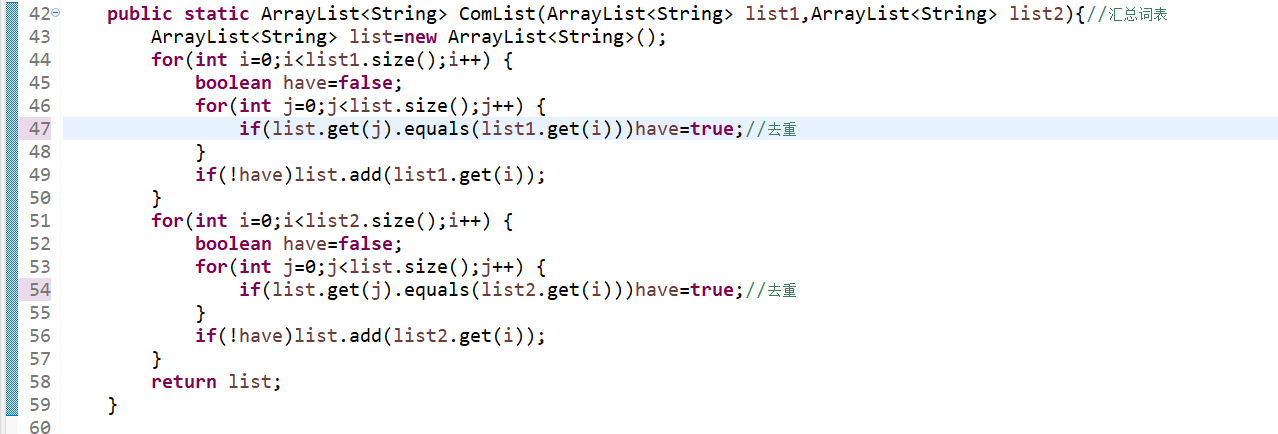
3、Vectorize(ArrayList
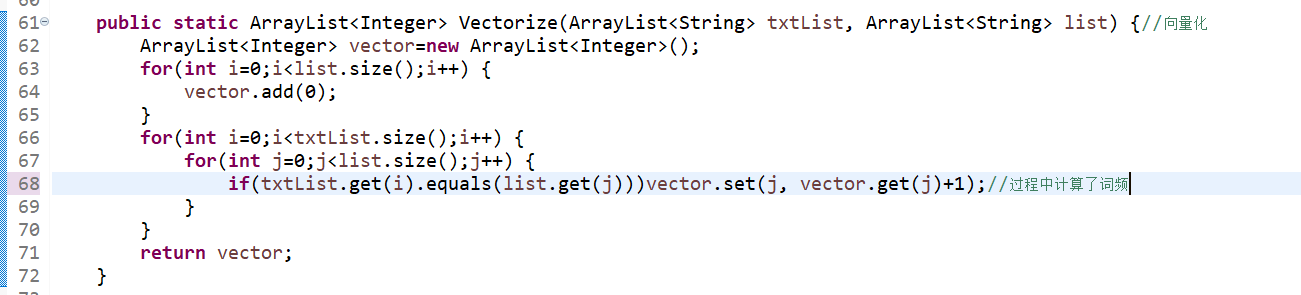
4、Cosine(ArrayList
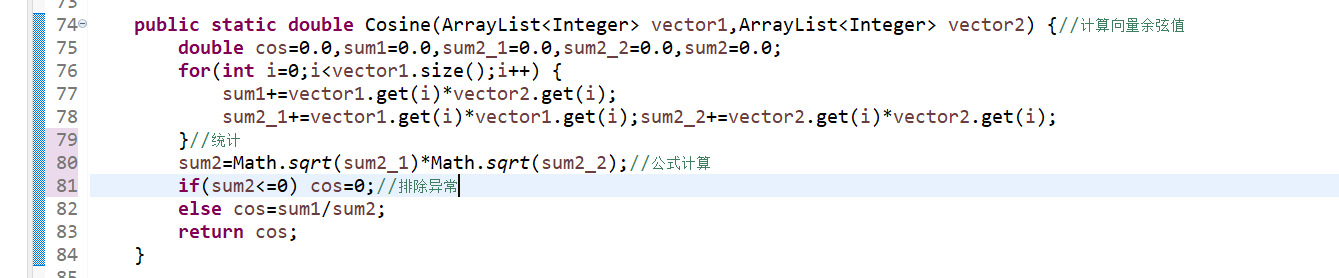
5、check(String filename1,String filename2):调用以上方法,通过输入的两个文本路径计算出文本向量余弦值作为文本相似度。
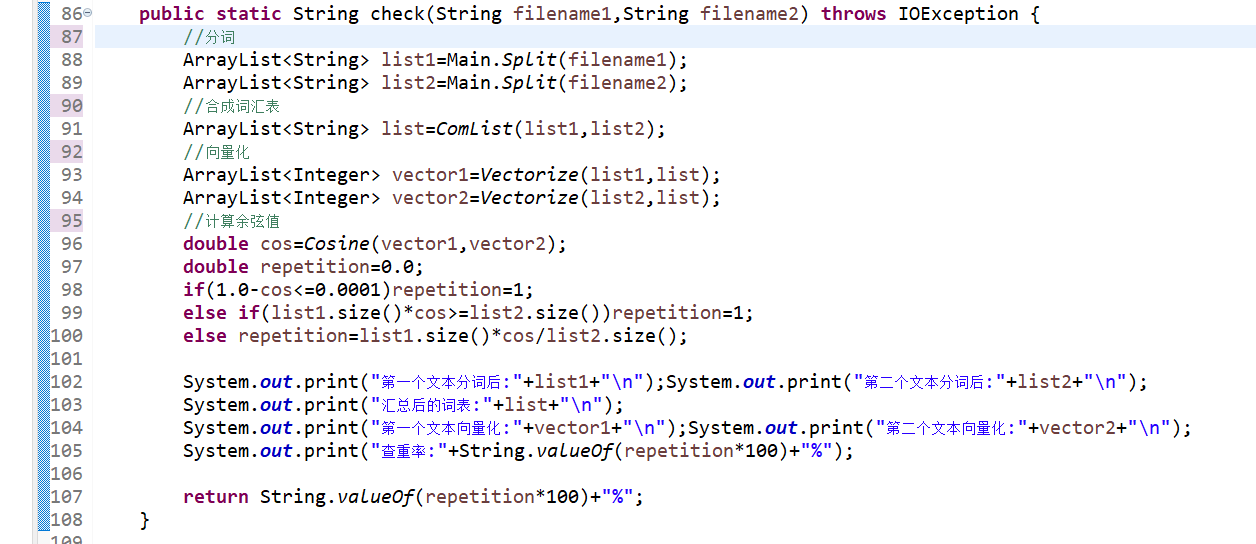
6、Output(String targetfile,String result):输出字符串到指定路径下的文件。

7、main(final String[] args):主函数。

·算法:通过分词器将文本拆成词组,两个文本词组合成词汇表,依照词汇表构建空间模型,通过词频生成两个文本的向量化表示,计算两个文本的向量余弦值作为文本相似度,通过该相似度与原文字数相乘,认为是原文可以抄袭成待查文百分百相似文章的字数,与待查文字数之比即是查重率。
·独到之处:既利用了文本相似度,又考虑了文本字数差带来的影响,提高了查重的准确性。
计算模块接口部分的性能改进
·改进性能时间:大约60min,查资料通过使用更高效的库函数减少计算时间。
·性能分析图
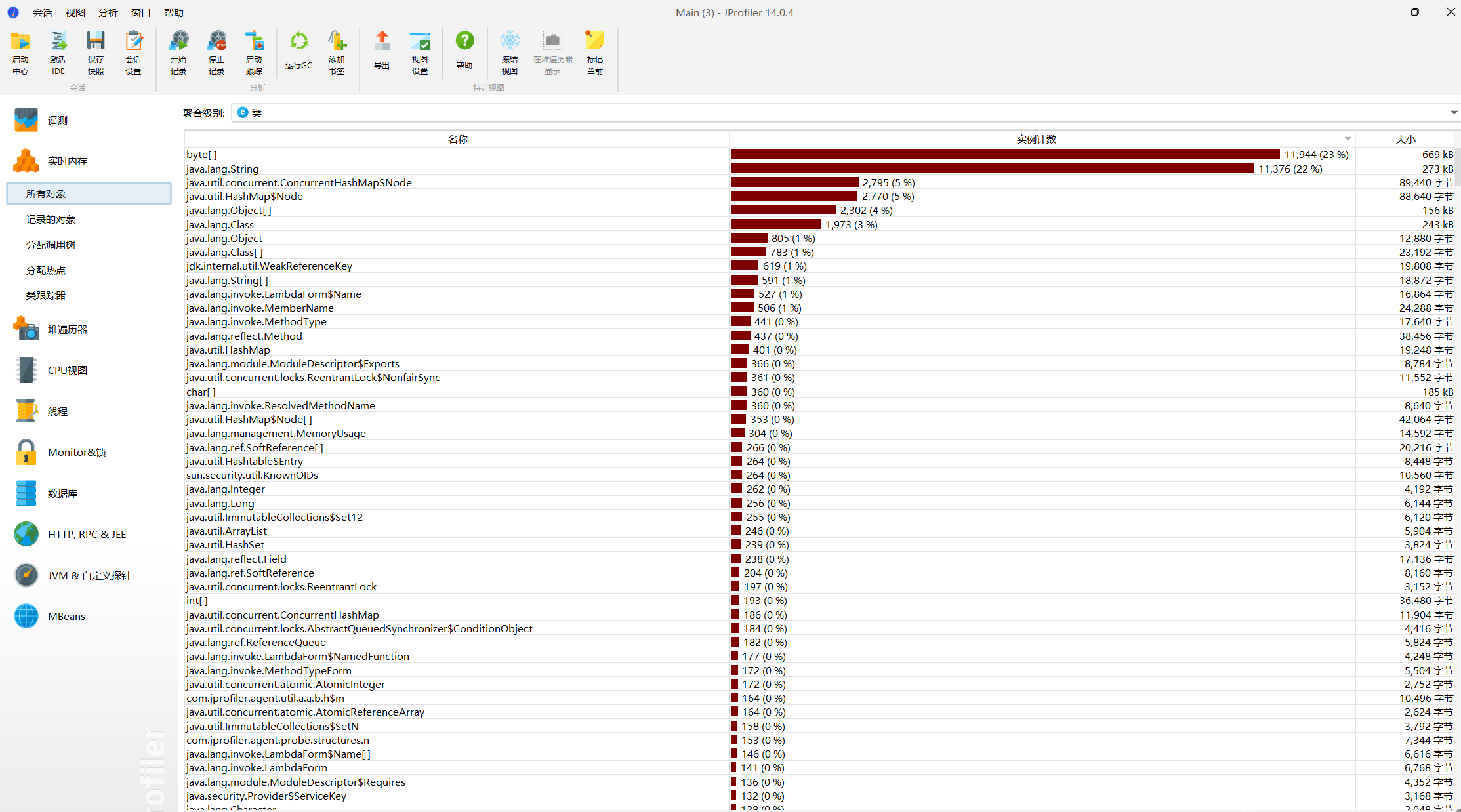
内存占用约300MB,主要用于储存字符串类(Byte[])。
·最耗时的函数:分词函数
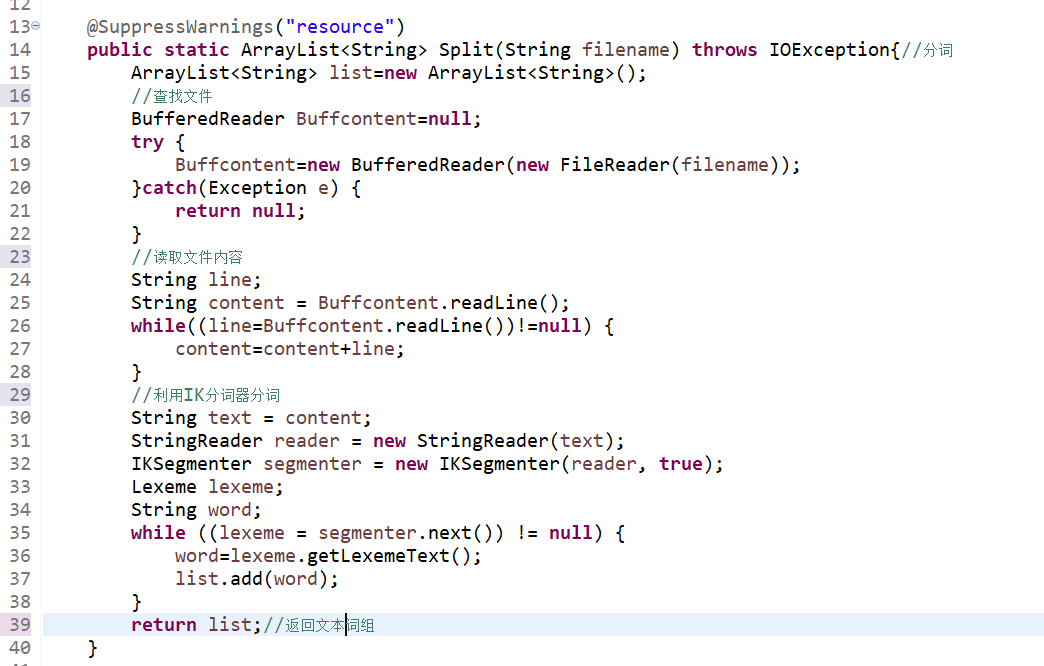
由于文本长度不低,在循环移动数组元素过程中耗时极大。
计算模块部分单元测试展示
·单元测试函数列表:
·部分函数如下:
1、设计两个向量作为参数调用余弦值计算函数,与正确答案比对误差<0.05即认为函数正常。

2、传递空参验证分词函数能否正常使用。

3、设计两个词组作为参数调用合并词汇表函数,验证能否生成正确的词汇表。

*测试覆盖率:85.5%

计算模块部分异常处理说明
对于异常的出现采用try-catch进行处理,直接利用现有异常类,没有定义新异常类。
如:

对于传参的格式错误,在catch中进行提示说明,并返回循环等待重新输入。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步