
awk 命令
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。在分析或过滤日志中经常用到。
语法
awk [选项参数] 'script' var=value file(s) 或 awk [选项参数] -f scriptfile var=value file(s)
常用选项参数说明:
-F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or --asign var=value
赋值一个用户定义变量。
-f scripfile or --file scriptfile
从脚本文件中读取awk命令。
基本用法
nginx日志文件access.log 如下:
185.8.49.209 | [29/Jun/2018:14:33:21+0800] | "GET login.cgi HTTP/1.1" | 5.0044 | 172 185.8.49.209 159.89.120.120 | [29/Jun/2018:14:39:49+0800] | "GET login.cgi HTTP/1.1" | 0.2554 | 172 159.89.120.120
用法一:
awk '[pattern] {action}' filenames # 行匹配语句 awk '' 只能用单引号
引号之间的部分是awk编程语言写的程序。每个awk程序都是一个或多个模式-动作语句的序列:
awk的基本操作是一行一行地扫描输入,搜索匹配任意程序中模式的行。
每个模式依次测试每个输入行。对于匹配到行的模式,其对应的动作(也许包含多步)得到执行,然后读取下一行并继续匹配,直到所有的输入读取完毕。
模式-动作语句中的模式或动作都可以省略,但不可同时省略。由于模式和动作两者任一都是可选的,所以需要使用大括号包围动作以区分于模式。
实例:
#每行按空格或TAB分割(默认),输出文本中的1、2、5项 awk '{print $1,$2,$5}' access.log ------------------------------------------------------ 185.8.49.209 | "GET 159.89.120.120 | "GET
用法二:
awk -F #-F相当于内置变量FS, 指定分割字符,未指定的话默认为按空格或TAB分割
实例:
#使用"|"分割,\表示转义,输出文本中的1、2、5项 awk -F\| '{print $1,$3,$5}' access.log ---------------------------------------------------- 185.8.49.209 [29/Jun/2018:14:33:21+0800] 172 185.8.49.209 159.89.120.120 [29/Jun/2018:14:39:49+0800] 172 159.89.120.120
上述实例也可以使用内建变量FS
awk 'BEGIN{FS="|"}{print $1,$2,$5}' access.log -------------------------------------------------------------- 185.8.49.209 [29/Jun/2018:14:33:21+0800] 172 185.8.49.209 159.89.120.120 [29/Jun/2018:14:39:49+0800] 172 159.89.120.120
用法三:
awk -v # 设置变量
实例:
#使用"."分割,变量a等于2,输出每一行的第一项加上a awk -F\. -va=2 '{print $1+a}' access.log --------------------------------------------------------- 187 161
用法四:
awk -f awk脚本 文件名
实例:
# -f选项指示awk从指定文件中获取程序
awk -f filter.awk access.log
格式化输出
print语句可用于快速而简单的输出。若要严格按照所谓的格式化输出,则需要使用 printf语句。语句的形式如下:
printf "format", value1, value2, ..., valuen
printf不会自动产生空格或者新的行,必须是你自己来创建,所以不要忘了\n
实例:
awk '{printf "%-20s %-10s\n",$1,$5}' access.log -------------------------------------------------------------- 185.8.49.209 "GET 159.89.120.120 "GET
%-20s的含义:以字符串形式在20个字符宽度的字段中左对齐输出
运算符
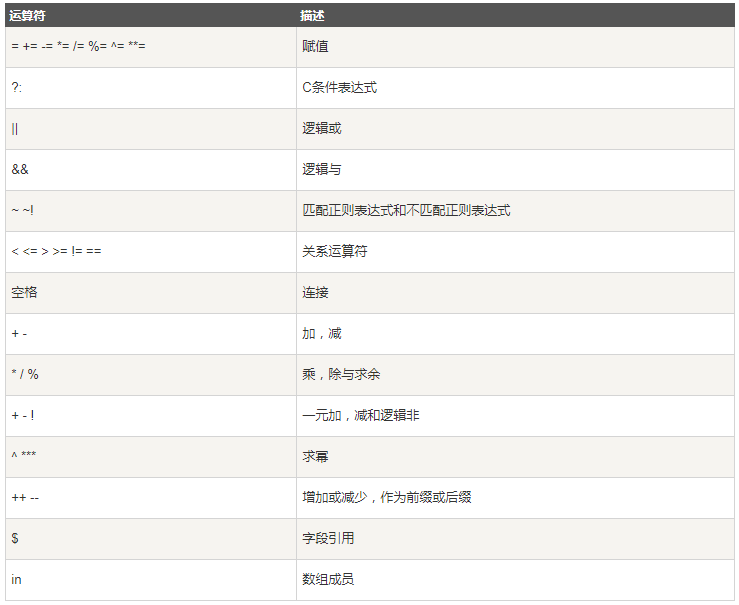
过滤第一列等于185的行
awk -F\. '$1==185 {print $0}' access.log $0表示所有项 --------------------------------------------------- 185.8.49.209 | [29/Jun/2018:14:33:21+0800] | "GET login.cgi HTTP/1.1" | 5.0044 | 172 185.8.49.209
内建变量
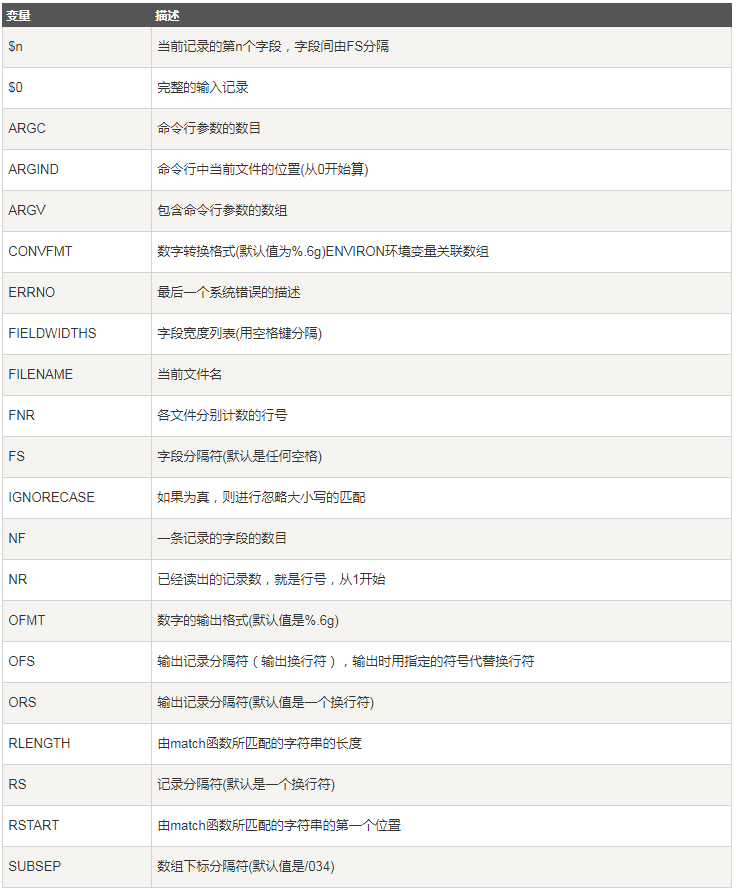
打印出每一行的字段数量, 第一个字段的值, 最后一个字段的值
awk -F\. '$1==185 {print NF,$1,$NF}' access.log $NF为最后一个字段 ---------------------------------------------------------- 10 185 209
打印行号
awk '{print NR,$0}' access.log ---------------------------------------------------------------- 1 185.8.49.209 | [29/Jun/2018:14:33:21+0800] | "GET login.cgi HTTP/1.1" | 5.0044 | 172 185.8.49.209 2 159.89.120.120 | [29/Jun/2018:14:39:49+0800] | "GET login.cgi HTTP/1.1" | 0.2554 | 172 159.89.120.120
忽略大小写
#以"|"为分隔符,忽略大小写,第三项包含http awk -F\| 'BEGIN{IGNORECASE=1} $3 ~ /http/' access.log ------------------------------------------------------------------ 185.8.49.209 | [29/Jun/2018:14:33:21+0800] | "GET login.cgi HTTP/1.1" | 5.0044 | 172 185.8.49.209 159.89.120.120 | [29/Jun/2018:14:39:49+0800] | "GET login.cgi HTTP/1.1" | 0.2554 | 172 159.89.120.120
使用正则,字符串匹配
输出第一项包含18的行
awk '$1 ~ /18/ {print $0}' access.log --------------------------------------------------- 185.8.49.209 | [29/Jun/2018:14:33:21+0800] | "GET login.cgi HTTP/1.1" | 5.0044 | 172 185.8.49.209
~ 表示模式开始。// 中是模式。
模式取反,输出第一项不包含18的行
awk '$1 !~ /18/ {print $0}' access.log --------------------------------------------------- 159.89.120.120 | [29/Jun/2018:14:39:49+0800] | "GET login.cgi HTTP/1.1" | 0.2554 | 172 159.89.120.120
awk脚本
关于awk脚本,我们需要注意两个关键词BEGIN和END。
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
假设有这么一个文件(学生成绩表):
$ cat score.txt Marry 2143 78 84 77 Jack 2321 66 78 45 Tom 2122 48 77 71 Mike 2537 87 97 95 Bob 2415 40 57 62
我们的awk脚本如下:

$ cat cal.awk #!/bin/awk -f #运行前 BEGIN { math = 0 english = 0 computer = 0 printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n" printf "---------------------------------------------\n" } #运行中 { math+=$3 english+=$4 computer+=$5 printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5 } #运行后 END { printf "---------------------------------------------\n" printf " TOTAL:%10d %8d %8d \n", math, english, computer printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR }
最后的执行结果:
$ awk -f cal.awk score.txt NAME NO. MATH ENGLISH COMPUTER TOTAL --------------------------------------------- Marry 2143 78 84 77 239 Jack 2321 66 78 45 189 Tom 2122 48 77 71 196 Mike 2537 87 97 95 279 Bob 2415 40 57 62 159 --------------------------------------------- TOTAL: 319 393 350 AVERAGE: 63.80 78.60 70.00
awk、sed、grep三者适合的地方:
- grep 更适合单纯的查找或匹配文本
- sed 更适合编辑匹配到的文本
- awk 更适合格式化文本,对文本进行较复杂格式处理

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步