

kubernetes 核心技术-pod
POD的定义
在Kubernetes集群中,Pod是所有业务类型的基础,也是K8S管理和部署的最小单位,其他的资源对象都是用来支撑或者扩展 Pod 对象功能的,比如控制器是用来管控Pod对象的,Service或者Ingress资源对象是用来暴露Pod对象的,PersistentVolume资源对象是用来为Pod提供存储等等。
k8s 不会直接处理容器,而是pod。pod是容器的载体,所有的容器都是在pod中被管理,一个或多个容器放在pod里作为一个单元方便管理。毕竟docker和kubernetes也不是一家公司的,如果做一个编排部署的工具,你也不可能直接去管理别人公司开发的东西,所以就把docker容器放在了pod里,在kubernetes的集群环境下,我直接管理我的pod,然后对于docker容器的操作,我把它封装在pod里,并不直接操作。
Pod、容器与Node(工作主机)之间的关系如下图所示:
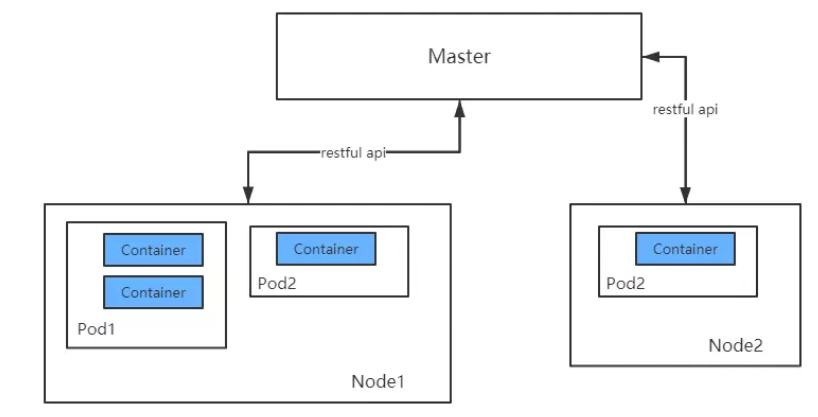
所以,pod是一个或多个容器的组合。这些容器共享存储、网络和命名空间,以及如何运行的规范。在Pod中,所有容器都被统一安排和调度,并运行在共享的上下文中。对于具体应用而言,Pod是它们的逻辑主机,Pod包含业务相关的多个应用容器。
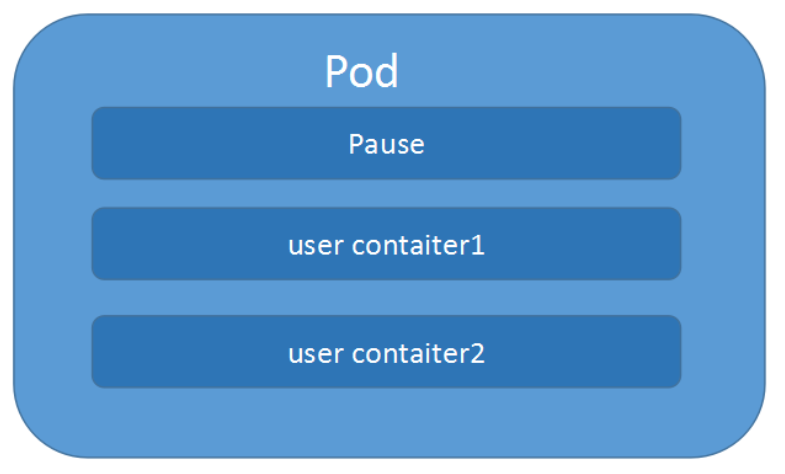
如图,每一个 Pod 都有一个特殊的被称为”根容器“的 Pause容器,加上一个或多个用户自定义的容器构造而成。pause的状态代表了这一组容器的状态。
--net=container:pause --ipc=contianer:pause --pid=container:pause的启动参数,因此pause容器成为Pod内共享命名空间的基础。所有容器共享pause容器的IP地址,也被称为Pod IP。pod里多个业务容器共享pod的Ip和数据卷,即pod的两个特点。
共享网络:
每一个Pod都会被指派一个唯一的Ip地址,在Pod中的每一个容器共享网络命名空间,包括Ip地址和网络端口。在同一个Pod中的容器可以用locahost(127.0.0.1)进行互相通信,不同容器只要注意不要有端口冲突即可。不同的Pod有不同的IP,不同Pod内的多个容器之前通信,通常情况下使用 Pod的IP进行通信。
共享存储:
一个 Pod 里的多个容器可以共享存储卷,这个存储卷会被定义为 Pod 的一部分,并且可以挂载到该 Pod 里的所有容器的文件系统上。
POD的工作方式
1.pod模板
K8s一般不直接创建Pod,而是通过控制器和模版配置来管理和调度。下面是一个完整的yaml格式定义的文件:
apiVersion: v1 //版本 kind: pod //类型,pod metadata: //元数据 name: String //元数据,pod的名字 namespace: String //元数据,pod的命名空间 labels: //元数据,标签列表 - name: String //元数据,标签的名字 annotations: //元数据,自定义注解列表 - name: String //元数据,自定义注解名字 spec: //pod中容器的详细定义 containers: //pod中的容器列表,可以有多个容器 - name: String image: String //容器中的镜像 imagesPullPolicy: [Always|Never|IfNotPresent]//获取镜像的策略 command: [String] //容器的启动命令列表(不配置的话使用镜像内部的命令) args: [String] //启动参数列表 workingDir: String //容器的工作目录 volumeMounts: //挂载到到容器内部的存储卷设置 - name: String mountPath: String readOnly: boolean ports: //容器需要暴露的端口号列表 - name: String containerPort: int //容器要暴露的端口 hostPort: int //容器所在主机监听的端口(容器暴露端口映射到宿主机的端口) protocol: String env: //容器运行前要设置的环境列表 - name: String value: String resources: //资源限制 limits: cpu: Srting memory: String requeste: cpu: String memory: String livenessProbe: //pod内容器健康检查的设置 exec: command: [String] httpGet: //通过httpget检查健康 path: String port: number host: String scheme: Srtring httpHeaders: - name: Stirng value: String tcpSocket: //通过tcpSocket检查健康 port: number initialDelaySeconds: 0//首次检查时间 timeoutSeconds: 0 //检查超时时间 periodSeconds: 0 //检查间隔时间 successThreshold: 0 failureThreshold: 0 securityContext: //安全配置 privileged: falae restartPolicy: [Always|Never|OnFailure]//重启策略 nodeSelector: object //节点选择 imagePullSecrets: - name: String hostNetwork: false //是否使用主机网络模式,默认否 volumes: //在该pod上定义共享存储卷 - name: String meptyDir: {} hostPath: path: string secret: //类型为secret的存储卷 secretName: String item: - key: String path: String configMap: //类型为configMap的存储卷 name: String items: - key: String path: String
2.pod重启
在Pod中的容器可能会由于异常等原因导致其终止退出,Kubernetes提供了重启策略以重启容器。重启策略对同一个Pod的所有容器起作用,容器的重启由Node上的kubelet执行。Pod支持三种重启策略,在配置文件中通过restartPolicy字段设置重启策略:
- Always:只要退出就会重启。
- OnFailure:只有在失败退出(exit code不等于0)时,才会重启。
- Never:只要退出,就不再重启
注意,这里的重启是指在Pod的宿主Node上进行本地重启,而不是调度到其它Node上。
3.资源限制
Kubernetes通过cgroups限制容器的CPU和内存等计算资源,包括requests(请求,调度器保证调度到资源充足的Node上)和limits(上限):

4.健康检查
在Pod部署到Kubernetes集群中以后,为了确保Pod处于健康正常的运行状态,Kubernetes提供了两种探针,用于检测容器的状态:
- Liveness Probe :检查容器是否处于运行状态(running)。如果检测失败,kubelet将会杀掉容器,并根据重启策略进行下一步的操作。
- ReadinessProbe :检查容器是否已经处于可接受服务请求的状态(ready)。如果检测失败,端点控制器将会从服务端点(与Pod匹配的)中移除容器的IP地址。
kubelet在容器上周期性的执行探针以检测容器的健康状态,kubelet通过调用被容器实现的处理器来实现检测,在Kubernetes中有三类处理器:
- Exec:在容器中执行一个指定的命令。如果命令的退出状态为0,则判断认为是成功的;
- TCPSocket :在容器IP地址的特定端口上执行一个TCP检查,如果端口处于打开状态,则视为成功;
- HTTPGet:发送一个http Get请求(ip+port+请求路径)如果返回状态吗在200-400之间则表示成功;
健康检测的结果为下面三种情况:
- Success :表示容器通过检测
- Failure :表示容器没有通过检测
- Unknown :表示检测容器失败
POD的创建流程
Kubernetes通过watch的机制进行每个组件的协作,每个组件之间的设计实现了解耦。
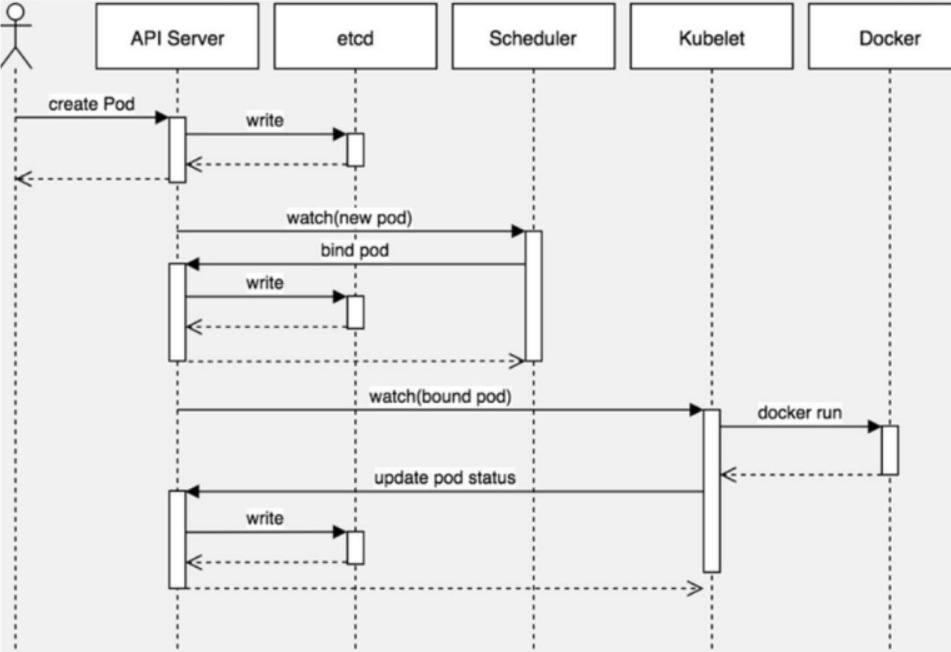
- 用户使用create yaml创建pod,请求给apiserver,apiserver将yaml中的属性信息(metadata)写入etcd。
- apiserver触发watch机制准备创建pod,信息转发给scheduler,调度器使用调度算法选择node,调度器将node信息返回给apiserver,apiserver将绑定的node信息写入etcd。
- apiserver又通过watch机制,调用kubelet,指定pod信息,触发docker run命令创建容器。
- 容器创建完成之后反馈给kubelet,kubelet又将pod的状态信息反馈给apiserver,apiserver又将pod的状态信息写入etcd。
- 其中kubectl get pods命令调用的是etcd中的信息。
注意:图中有三次write至etcd:
- 元信息
- pod分配到哪个node
- 记录pod状态
在整个过程中,Pod通常处于以下的五种阶段之一:
- Pending:Pod定义正确,提交到Master,但其所包含的容器镜像还未完全创建。通常,Master对Pod进行调度需要一些时间,Node进行容器镜像的下载也需要一些时间,启动容器也需要一定时间。(写数据到etcd,调度,pull镜像,启动容器)。
- Running:Pod已经被分配到某个Node上,并且所有的容器都被创建完毕,至少有一个容器正在运行中,或者有容器正在启动或重启中。
- Succeeded:Pod中所有的容器都成功运行结束,并且不会被重启。这是Pod的一种最终状态。
- Failed:Pod中所有的容器都运行结束了,其中至少有一个容器是非正常结束的(exit code不是0)。这也是Pod的一种最终状态。
- Unknown:无法获得Pod的状态,通常是由于master无法和Pod所在的Node进行通信。
POD调度方式
Deployment或RC全自动调度:pod最终运行在哪个节点上, 完全由 Master 的 Scheduler 经过一系列算法计算得 出 ,用户无法干预调度过程和结果。
除此之外,还有以下三种方式去影响pod的调度
- node节点调度器
- 亲和性调度
- 污点容忍度
1.node节点调度
是最直接的调度方式,简单粗暴,所以常用在简单的集群架构中,负载的资源分类和编制不适合这种方式,
解释:先给work节点打上标签,然后在pod的yml文件中去设置nodeSelector绑定节点,这样就能指定pod启动在设置的node节点上。
(1)首先通过 kubectl 给 node1 打上标签
格式: kubectl label nodes <node-name> <label-key>=<label-value> [root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready master 23d v1.18.0 node1 Ready <none> 21d v1.18.0 node2 Ready <none> 21d v1.18.0 [root@master ~]# kubectl label nodes node1 disk=ssd node/node1 labeled [root@master ~]# kubectl get nodes node1 --show-labels NAME STATUS ROLES AGE VERSION LABELS node1 Ready <none> 21d v1.18.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disk=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linux [root@master ~]#
(2)通过 nodeSelector 调度 pod 到指定 node
- Pod的定义中通过nodeSelector指定label标签,pod将会只调度到具有该标签的node之上
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 1 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.11 ports: - containerPort: 80 nodeSelector: disk: ssd
这个例子中pod只会调度到具有 disk=ssd 标签的node1上:
[root@master ~]# kubectl apply -f pod-test.yaml deployment.apps/nginx-deployment created [root@master ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-6b4474784c-ld2ng 0/1 ContainerCreating 0 29s <none> node1 <none> <none> [root@master ~]# kubectl describe pod nginx-deployment Name: nginx-deployment-6b4474784c-ld2ng Namespace: default Priority: 0 Node: node1/172.31.93.201 Start Time: Fri, 09 Apr 2021 11:44:47 +0800 Labels: app=nginx pod-template-hash=6b4474784c Annotations: <none> Status: Running IP: 10.244.1.4 IPs: IP: 10.244.1.4 Controlled By: ReplicaSet/nginx-deployment-6b4474784c Containers: nginx: Container ID: docker://0669cc442c30510246f12495a796b2968e0b84693b7ae8c378f0d6b0556ed947 Image: nginx:1.11 Image ID: docker-pullable://nginx@sha256:e6693c20186f837fc393390135d8a598a96a833917917789d63766cab6c59582 Port: 80/TCP Host Port: 0/TCP State: Running Started: Fri, 09 Apr 2021 11:45:24 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /var/run/secrets/kubernetes.io/serviceaccount from default-token-tdnv4 (ro) Conditions: Type Status Initialized True Ready True ContainersReady True PodScheduled True Volumes: default-token-tdnv4: Type: Secret (a volume populated by a Secret) SecretName: default-token-tdnv4 Optional: false QoS Class: BestEffort Node-Selectors: disk=ssd Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled <unknown> default-scheduler Successfully assigned default/nginx-deployment-6b4474784c-ld2ng to node1 Normal Pulling 8h kubelet, node1 Pulling image "nginx:1.11" Normal Pulled 8h kubelet, node1 Successfully pulled image "nginx:1.11" Normal Created 8h kubelet, node1 Created container nginx Normal Started 8h kubelet, node1 Started container nginx
如果给多个node都定义了相同的标签, 则调度器会根据调度算法从这组node中挑选一个可用的node进行pod调度。
如果指定了pod的nodeSelector条件, 且集群中不存在包含响应标签的Node, 则即使在集群中还有其它可供使用的Node,这个pod也无法被成功调度。
2.亲和性调度
较复杂,应用在复杂的多节点归类,资源分类管理的中大型集群中,有硬亲和,软亲和,亲和性和反亲和等概念。
硬亲和:匹配节点上的标签(必须满足,若集群中不存在包含响应标签的Node,无法调度成功)
软亲和:匹配节点上的标签(尝试满足,优先选择包含响应标签的Node,实在没有也能调度运行)
- 节点亲和性(Node affinity)
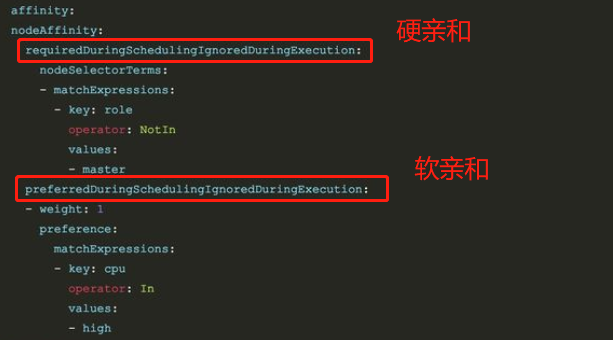
上述配置表示,该pod必须不能调度至有标签 role=master 的node节点(必须满足),最好能调度至有标签 cpu=high 的node节点(尝试满足)
支持常用的操作符有:in Notin Exists Gt Lt DoesNotExists
- pod亲和性(pod affinity)与反亲和性(pod anti affinity)
podAffinity用于调度pod可以和哪些pod部署在同一拓扑结构之下。而podAntiAffinity相反,其用于规定pod不可以和哪些pod部署在同一拓扑结构下。主要用来解决pod和pod之间的关系。
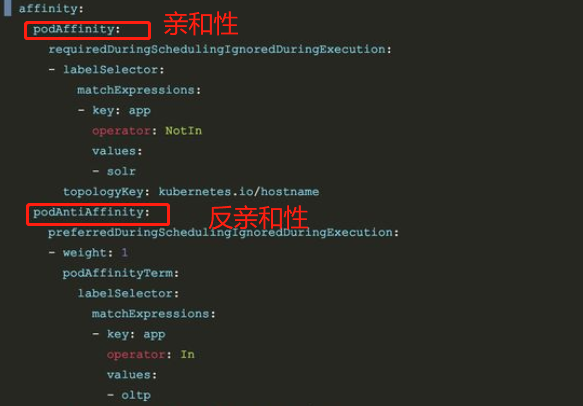
上述配置表示,该pod不可以和solr服务的pod部署在同一拓扑结构之下(必须满足),最好不要和oltp服务的pod部署在同一拓扑结构之下(尝试满足)
3.污点和容忍度
无论是nodeSelector还是nodeAffinity,都是通过pod中的属性,在调度的时候实现。
与之前两个调度方式不同,污点是给节点绑定污点(是节点的属性),作用是保护节点,不再让这个节点被scheduler选为pod启动环境。
集群中的master就是设置了污点,所以启动任何pod都不会在master上工作,保证master的工作效率。
查看节点的污点情况:kubectl describe node [node] | grep Taints
[root@master ~]# kubectl describe node master |grep Taint Taints: node-role.kubernetes.io/master:NoSchedule
可见,master有一个NoSchedule的污点,污点值有三个:
- NoSchedule:一定不被调度,对已有pod不影响
- PreferNoSchedule: 尽量不被调度
- NoExecute:一定不被调度,并且还会驱逐node上已有pod
设置给node1设置污点:kubectl taint node node1 node-type=prod:NoSchedule
[root@master ~]# kubectl taint node node1 node-type=prod:NoSchedule node/node1 tainted [root@master ~]# kubectl describe node node1 |grep Taint Taints: node-type=prod:NoSchedule
创建pod测试:
#创建一个pod [root@master ~]# kubectl create deployment web --image=nginx deployment.apps/web created #复制五个 [root@master ~]# kubectl scale deployment web --replicas=5 deployment.apps/web scaled [root@master ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES web-5dcb957ccc-7qj2f 0/1 ContainerCreating 0 21s <none> node2 <none> <none> web-5dcb957ccc-9bqz5 1/1 Running 0 89s 10.244.2.4 node2 <none> <none> web-5dcb957ccc-d99vb 1/1 Running 0 21s 10.244.2.5 node2 <none> <none> web-5dcb957ccc-wd7b4 0/1 ContainerCreating 0 21s <none> node2 <none> <none> web-5dcb957ccc-xvf74 0/1 ContainerCreating 0 21s <none> node2 <none> <none>
可见,由于node1设置了污点,所有pod都被调度到了node2上。
最后删除污点:kubectl taint node node1 node-type=prod:NoSchedule- (注意最后面有一个-)
[root@master ~]# kubectl describe node node1|grep Taint Taints: node-type=prod:NoSchedule [root@master ~]# kubectl taint node node1 node-type=prod:NoSchedule- node/node1 untainted [root@master ~]# kubectl describe node node1|grep Taint Taints: <none>
所有,如果一个节点标记为 Taints ,该Taints节点不会被调度pod,除非要被调度的Pod被标识为可以容忍污点:
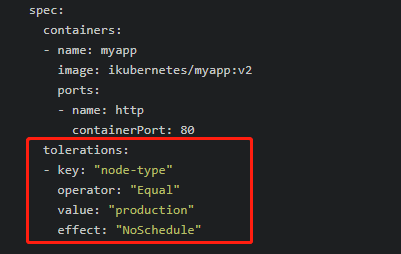
就是说,即使一个节点已经被设置污点(假设是NoSchedule),如果一个pod被标识为容忍(容忍度也是NoSchedule),那么这个pod还是有可能会被调度到taint标记过的节点。
参考文档:
https://blog.csdn.net/weixin_42953006/article/details/106299864
https://www.jianshu.com/p/74f53019a726
https://www.cnblogs.com/mybxy/p/10233682.html
