
树形结构数据库表设计与django结合
树形结构数据库表设计
- 树形结构我们经常会用它表征某些数据关联,比如商品分类,企业管理系统菜单或上下级关系等,但在mysql都是以二维表形式生成的数据。设计合适Schema及其对应CRUD算法是实现关系型数据库中存储树。这里我们用django演示
1.简单版:
- 首先我们要生成如下属性结构图:
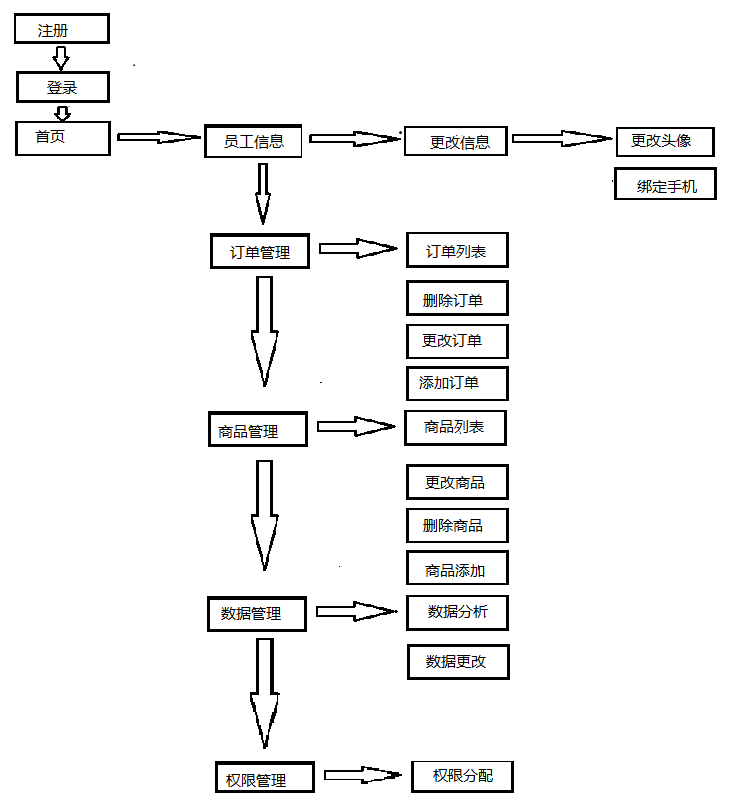
-
这里拿django演示,好像又说了一遍。
-
常规操作,创建model,添加数据:
class Menu(models.Model): name = models.CharField(max_length=32,verbose_name="名字") # parent为自关联,关联父id parent = models.ForeignKey('self', verbose_name='关联父', blank=True, null=True) class Meta: db_table = "Menu"
-
简单写序列化器:
class MenuSerializer(serializers.ModelSerializer): pid = serializers.CharField(source="parent_id") class Meta: model = models.Menu # 这里为了演示,只序列化功能实现基本字段,可自定义序列化字段 fields = ['id',"name","pid"] depth = 1 -
视图函数:
class Node(object): """ 构造节点 """ def __init__(self,parent,name): self.parent = parent self.name = name def build_tree(nodes,parent): """ 将树形列表构建dict结构 :param nodes: 查询的节点列表 :param parent: 当前节点父节点 :return: """ # 用来记录该节点下所有节点列表 node_list = list() # 用于构建dict结构 tree = dict() build_tree_recursive(tree,parent,nodes,node_list) return tree,node_list def build_tree_recursive(tree,parent,nodes,node_list): """ 递归方式构建 :param tree: 构建dict结构 :param parent: 当前父节点 :param nodes: 查询节点列表 :param node_list: 记录该节点下所有节点列表 :return: """ # 遍历循环所有子节点 children = [n for n in nodes if n.parent == parent] node_list.extend([c.name for c in children]) for child in children: # 子节点内创建新的子树 tree[child.name] = {} # 递归去构建子树 build_tree_recursive(tree[child.name], child, nodes, node_list) def make_mode_list(menu_list): """ json形式生成一个个node对象,且关联父节点 :param menu_list: 序列化后的菜单表 :return: """ # 返回node root_dict = {} while menu_list: term = menu_list.pop() pid = term.get("pid") if not pid: root_dict[term.get("id")] = Node(None, term.get("name")) continue parent = root_dict.get(int(pid)) if not parent: menu_list.insert(0, term) continue root_dict[term.get("id")] = Node(parent, term.get("name")) return root_dict.values() class Menu(APIView): def get(self,request,*args,**kwargs): # 这里获取所有数据 menu_obj = models.Menu.objects.all() # 序列化 ser_menu = MenuSerializer(instance=menu_obj,many=True) ser_menu_list = ser_menu.data # 序列化后数据,生成node node_list = make_mode_list(ser_menu_list) tree_dict,tree_list = build_tree(node_list,None) return Response({"code":200,"msg":"OK","tree_dict":tree_dict,"tree_list":tree_list})- 这里将属性结构列表转换成json数据并返回:
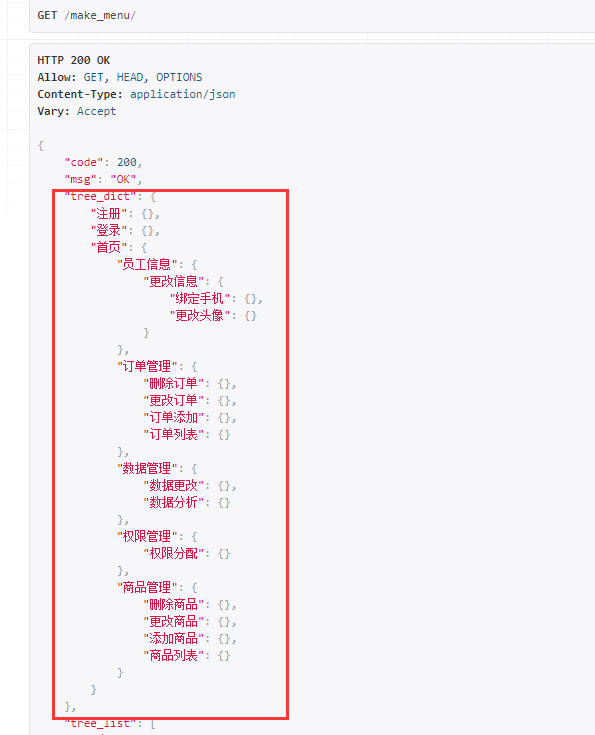
-
这种方法实现,简单直观,方便。但存在着很大缺点,由于直接记录节点之间继承关系,所以Tree的任何CRUD操作很低效,因为这里频繁的"递归"操作,加之不断访问数据库,会增加很大时间开销。但是对于Tree的规模比较小时,我们可以通过缓存机制来做优化,将Tree的信息载入内存进行处理,避免直接对数据库IO操作性能开销。
2.基于左右值Schema设计
-
为了避免对于树形结构查询时"递归"惭怍,基于Tree的谦虚遍历设计是一个无递归查询。来报错该树数据。
-
创建model:
class TreeMenu(models.Model): name = models.CharField(max_length=32,verbose_name="名字") left = models.IntegerField(verbose_name="左") right = models.IntegerField(verbose_name="右") class Meta: db_table = "TreeMenu" -
如下展示数据:
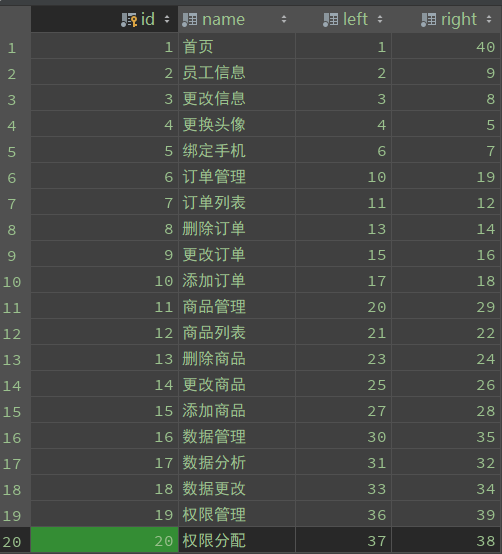
-
刚来时看这样表结构,大部分人不清楚left和right是什么鬼,如何得到的?这样表设计并没有保存父子节点继承关系,但是你去数如下的图,你会发现,你数的顺序就是这棵树进行前序遍历顺序。
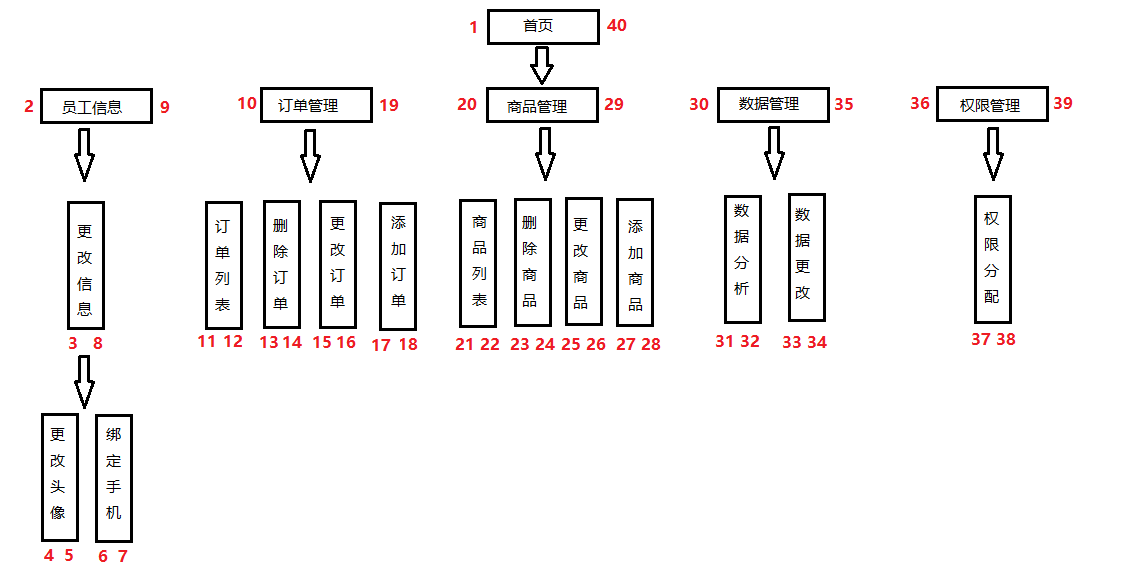
-
举个例子:这样可以得到left大于2,并且right小于9的节点都是员工信息子节点。这样通过left,right就可以找到某个节点所拥有的子节点了,但这仅仅是不够的。那么怎样增删改查呢?
-
比如我们需要
员工信息管理节点及其子节点们:import os import django from django.db.models import Q os.environ.setdefault("DJANGO_SETTINGS_MODULE", "asyn_test.settings") django.setup() # 启动django项目 # 引入models.py模型模块 from api.models import TreeMenu #查询 left大于等于2,right小于等于9 tree = TreeMenu.objects.filter(Q(left__gte=2)&Q(right__lte=9)).values() print(tree) """ <QuerySet [{'id': 2, 'name': '员工信息', 'left': 2, 'right': 9}, {'id': 3, 'name': '更改信息', 'left': 3, 'right': 8}, {'id': 4, 'name': '更换头像', 'left': 4, 'right': 5}, {'id': 5, 'name': '绑定手机', 'left': 6, 'right': 7}]> """ -
那么如何查询某个节点的子节点个数呢,通过左,右值可以得到,子节点总数=(右值-左值-1)/2, 以
员工信息为例子,它的子节点总数为(9-2-1)/2=3,并且我们为了更直观展示树的结构,我们有时需要知道树种所处的层次,我们可以这么查询,这里还是以员工信息为例:layer = TreeMenu.objects.filter(Q(left__lte=2)&Q(right__gte=9)).count() print(layer) """ 2 """ # 可以知道,它是第二层的 -
通过上面方式我们可以得到每一个节点所在层数,这样我们通过ORM构造一个数据结构,如下:
tree_obj = TreeMenu.objects.all() treemenu_list = [] for term in tree_obj: layer = TreeMenu.objects.filter(Q(left__lte=term.left)&Q(right__gte=term.right)).count() treemenu_list.append( {"id":term.id,"name":term.name,"left":term.left,"right":term.right,"layer":layer} ) print(treemenu_list) # layer 为当前节点所在层数,你会发现获得所有节点所在的层数 """ [{ 'id': 1, 'name': '首页', 'left': 1, 'right': 40, 'layer': 1 }, { 'id': 2, 'name': '员工信息', 'left': 2, 'right': 9, 'layer': 2 }, ...] """ -
我们如何获得某个节点的父节点结构,也很简单,这里拿
员工信息举例:employ = TreeMenu.objects.filter(Q(left__lte=2)&Q(right__gte=9)).values() print(employ) """ <QuerySet [{'id': 1, 'name': '首页', 'left': 1, 'right': 40}, {'id': 2, 'name': '员工信息', 'left': 2, 'right': 9}]> """ -
如果说我们想在某个节点下添加一个新的子节点,比如我在
更改信息下插入一个子节点绑定邮箱.如果田间玩,此时树形结构应该如下: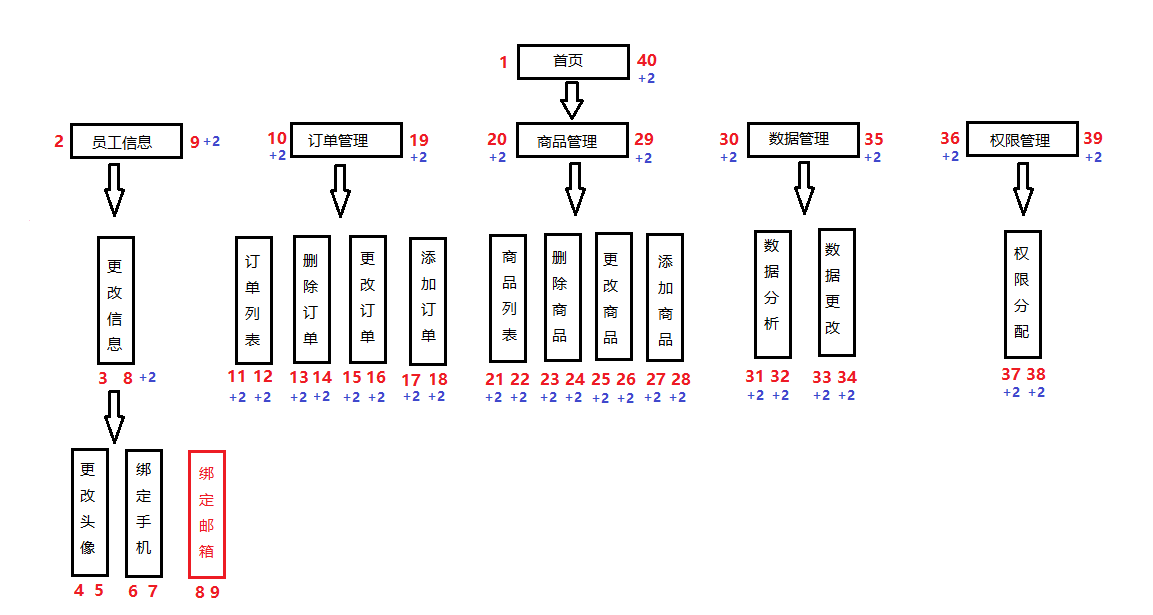
-
代码:
edit_info_obj = TreeMenu.objects.filter(pk=3).first() # 获取"更改信息"当前对象right值 node_point = edit_info_obj.right # 更新 所有节点left大于等于node_point的值 TreeMenu.objects.filter(left__gte=node_point).update(left=F('left') + 2) # 更新 所有节点right大于等于node_point的值 TreeMenu.objects.filter(right__gte=node_point).update(right=F('right') + 2) # 插入数据 为当前 node_point,node_point+1 TreeMenu.objects.create(name="绑定邮箱",left=node_point,right=node_point+1) -
删除某个节点,如果想删除某个节点,会同时删除该节点的所有子节点,而被删除的节点个数应该为:(被删除节点右侧值-被删除节点的左侧值+1)/2,而剩下节点左,右值在大于被删除节点左、右值的情况下进行调整。
-
这样以删除
更改信息为例,那么首先找到该节点左侧值和右侧值,并且大于等于左侧值小于等于右侧值的节点都是要删除节点,也就是left=3,right=10,left<=3 and right<=10,节点都要删除,其他节点left的值大于删除节点left值应该减去(被删除节点右侧值-被删除节点的左侧值+1),其他节点right值大于删除节点right值也应该减去(被删除节点右侧值-被删除节点的左侧值+1)。如下图: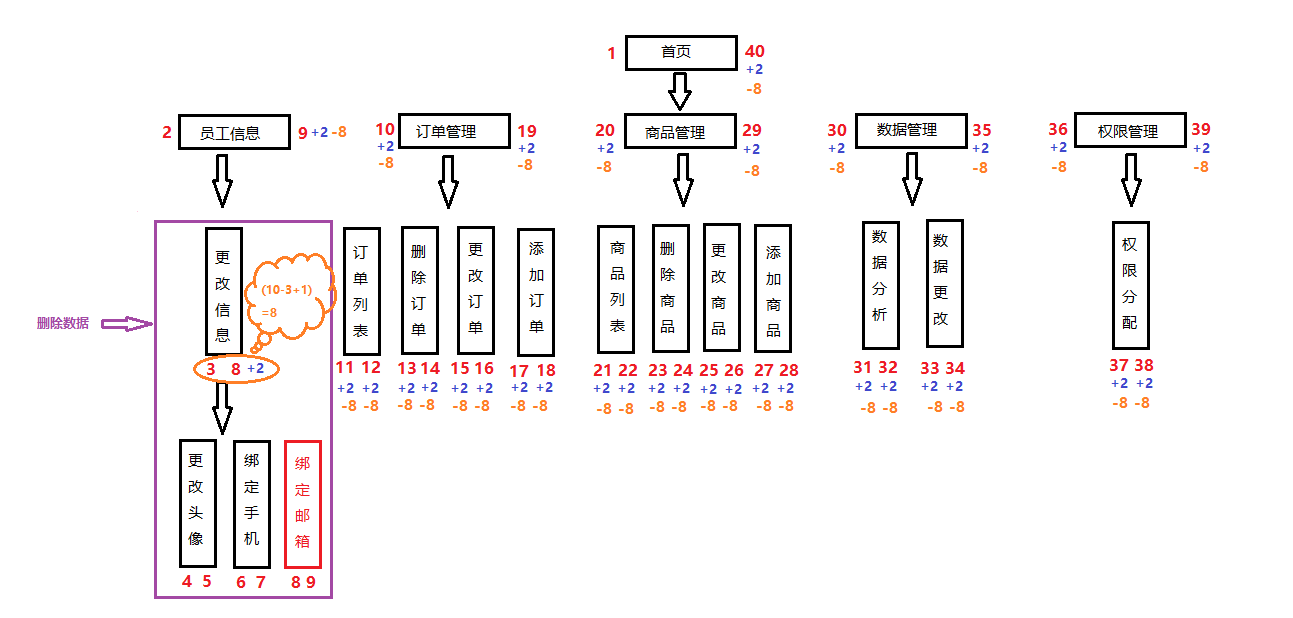
-
代码:
edit_info_obj = TreeMenu.objects.filter(pk=3).first() left_ponit = edit_info_obj.left#3 right_ponit = edit_info_obj.right#10 # 删除该节点下大于等于左侧值,小于等于右侧值的对象 TreeMenu.objects.filter(Q(left__gte=left_ponit)&Q(right__lte=right_ponit)).delete() # 当其他节点左侧值大于删除节点左侧值,更新其他节点左侧值。 TreeMenu.objects.filter(left__gt=left_ponit).update(left=F('left')-(right_ponit-left_ponit+1)) # 当其他节点右侧值大于删除节点右侧值,更新其他节点右侧值。 TreeMenu.objects.filter(right__gt=right_ponit).update(right=F('right')-(right_ponit-left_ponit+1)) -
那么django中如何将数据封装json格式取出呢?上代码
class SchemaMenuSerializer(serializers.ModelSerializer): layer = serializers.SerializerMethodField() class Meta: model = models.TreeMenu fields = "__all__" depth = 1 # 用于计算当前节点在第几层。 def get_layer(self,obj): left = obj.left right = obj.right count_layer = models.TreeMenu.objects.filter(Q(left__lte=left) & Q(right__gte=right)).count() return count_layer def parse_data(layer_dict,tree_dict): left = layer_dict.get("left") right = layer_dict.get("right") layer = layer_dict.get("layer") id = layer_dict.get("id") tree_dict["left"] = left tree_dict["right"] = right tree_dict["layer"] = layer tree_dict["id"] = id # 获取子节点数据 tree = models.TreeMenu.objects.filter(Q(left__gt=left) & Q(right__lt=right)) ser_tree = SchemaMenuSerializer(instance=tree, many=True).data sub_ser_tree = [dict(i) for i in ser_tree if i.get("layer") == layer + 1] # 递归创建子节点 for sub in sub_ser_tree: tree_dict[sub.get("name")] = {} parse_data(sub, tree_dict[sub.get("name")]) def make_node_list(ser_schemamenu): # 构建首页字典 tree_dict = { ser_schemamenu.get("name"):{}, "id":ser_schemamenu.get("id"), "layer":ser_schemamenu.get("layer"), "left":ser_schemamenu.get("left"), "right":ser_schemamenu.get("right"), } # 交给parse_data,它会递归取出第二层,第三层。。。。数据 parse_data(ser_schemamenu,tree_dict[ser_schemamenu.get("name")]) return tree_dict class SchemaMenu(APIView): def get(self,request,*args,**kwargs): # 这里第一层最高节点 也就是首页 schema_menu_obj = models.TreeMenu.objects.filter(pk=1).first() # 首页字段序列化 获取layer层数 ser_schema_menu = SchemaMenuSerializer(instance=schema_menu_obj).data # 创建节点 tree_dict = make_node_list(ser_schema_menu) return Response({"code":200,"msg":"OK","data":tree_dict}) -
效果:
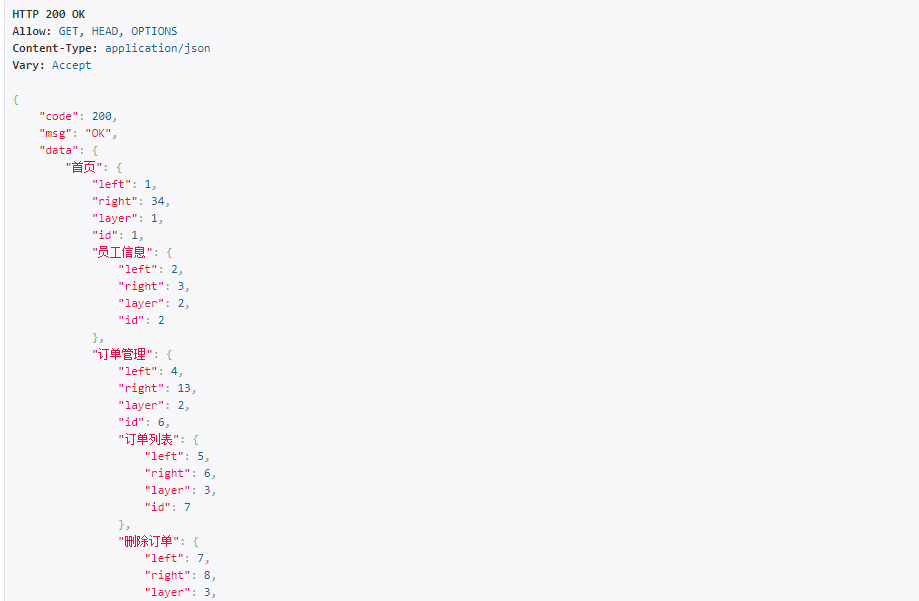
3.最后总结:
-
Schema设计方法优点消除了递归操作的恰提实现无限分组,而且查询条件基于整形数字,效率高。
-
但是缺点就是节点的添加,删除和修改代价比较大,会设计到表中很多数据改动。
-
当然你还可以添加比如同层节点评议,节点下移,节点上移等操作。不过实现这些算法相对比较繁琐,会有很多update语句,如果执行顺序不对,会对整个树形结构产生巨大破坏,建议用临时表,或者将表备份。
-
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号