MySQL
MySQL
学数据库的原因
-
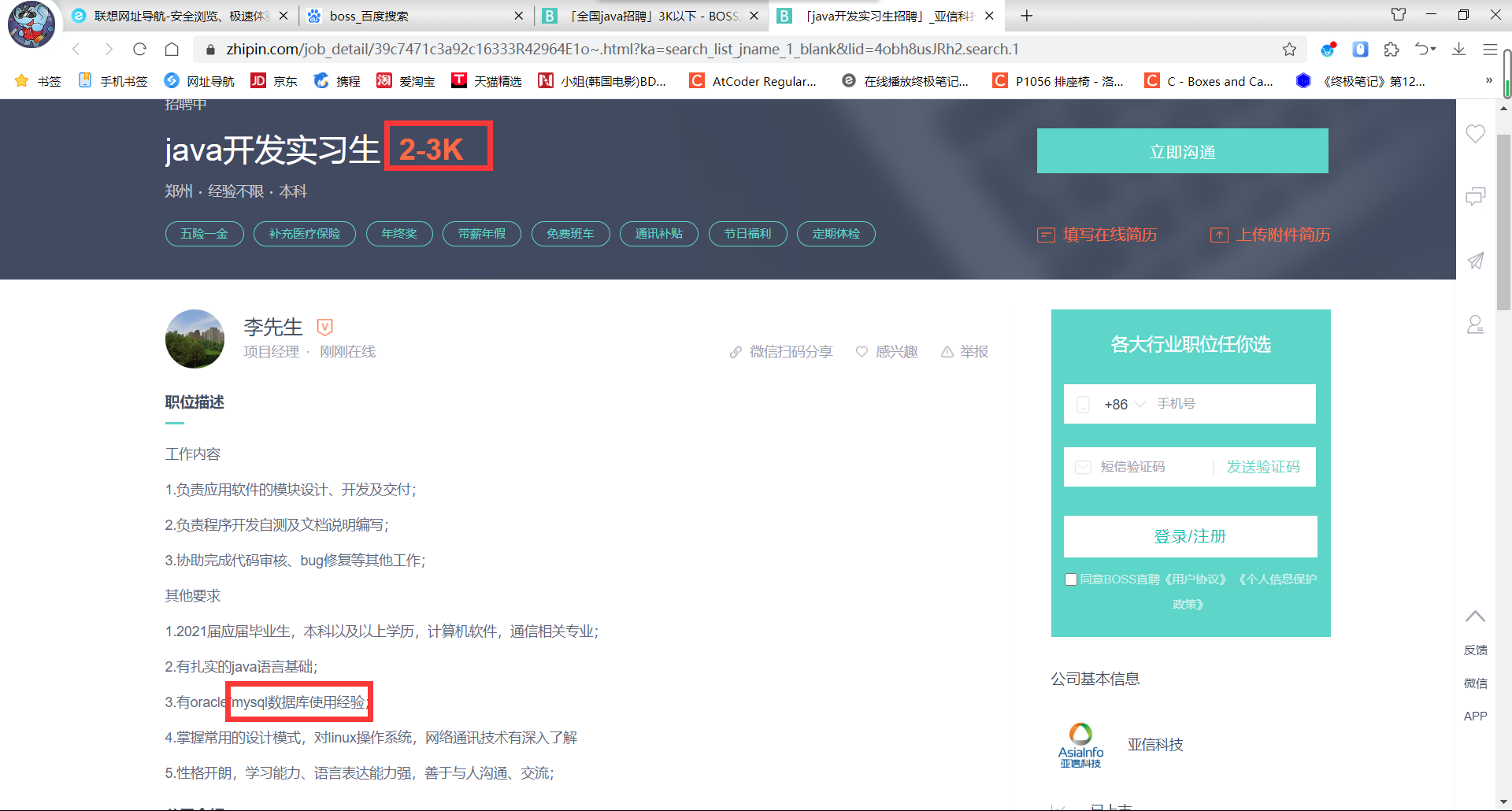
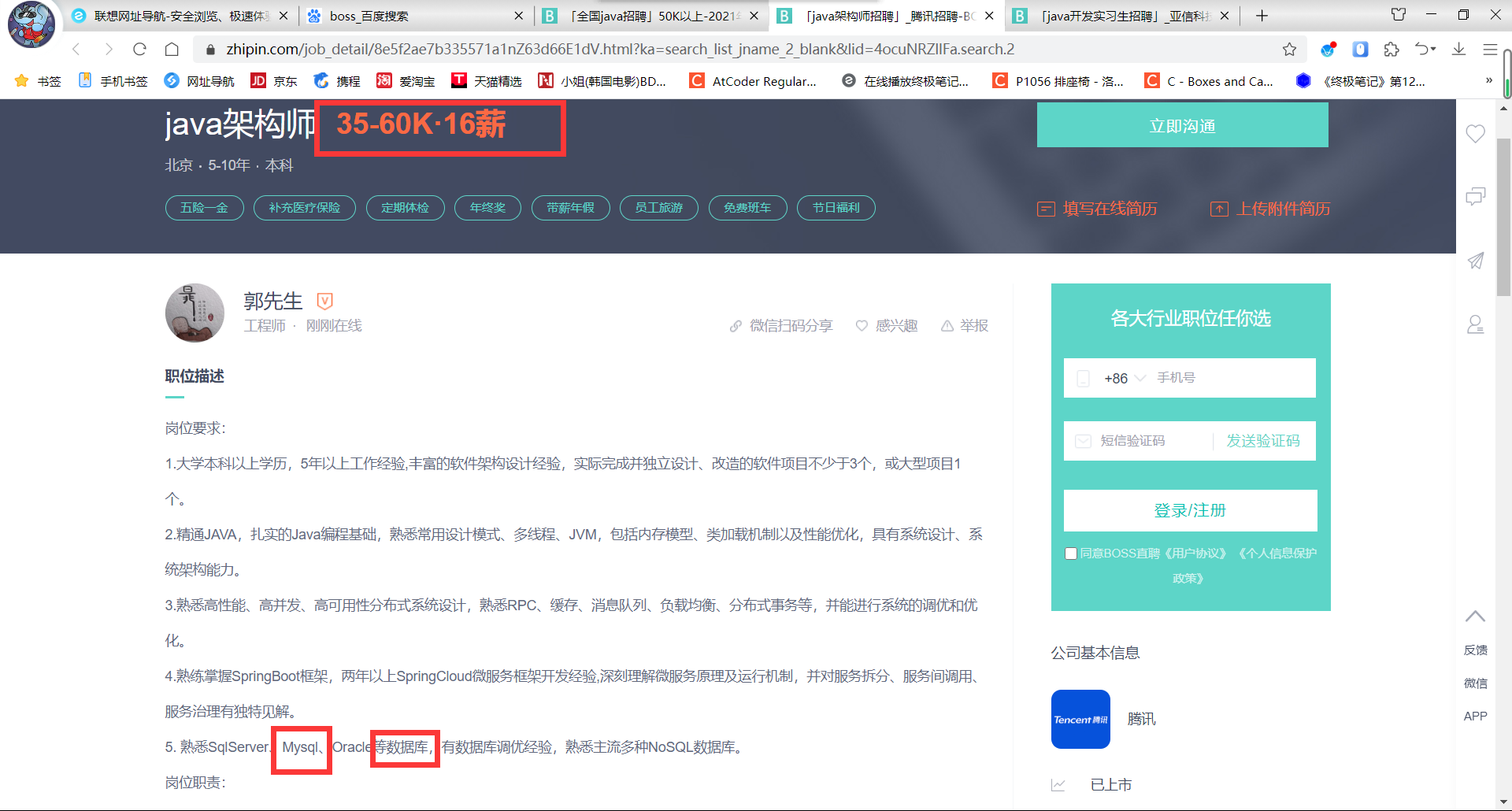
岗位需求(最主要的)
无论是高薪/平均工资,在对于java程序员的招新时,在其岗位要求都会要求对MySQL精通
![image-20210214205806287]()
![image-20210214205859215]()
-
大数据时代
-
在写代码的时候需要存数据(被迫需求)
-
数据库是所有软件体系中最核心的存在
如:由此应运而生的岗位:DBA (Database Administrator),数据库管理员
什么是数据库(DB,DataBase)
概念:安装在操作系统之上(在操作系统上不是跨平台的,类似于 JVM 的跨平台原理)的一个软件,是一个数据仓库。
SQL,是一个操作数据库的语句(学MySQL的核心),可以存储大量数据(500万以下的数据),超过的话需要做相应的优化
数据库分类
-
关系型数据库(SQL)
MySQL,Oracle,DB2,SQLlite(例如网站用的比较多,比较容易集成去安装的等等)
通过表和表之间,行和列之间进行数据的存储
-
非关系型数据库(NoSQL——Not Only SQL,不是NO SQL噢!)
Redis,MongDB
以对象存储,通过对象自身的的属性来决定
数据库管理系统(DBMS,DataBase Management System)——数据库的管理软件
科学有效的管理我们的数据,维护和获取数据
MySQL介绍
(从百度百科copy来的)
MySQL是一个关系型数据库管理系统由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版(收费or不收费),由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站(或大型网站——如果一个数据库不够用,可以集群)的开发都选择 MySQL 作为网站数据库。
关于安装MySQL
虽然大家可能到现在已经安装完了,当然咱不排除有那么一小丢丢同学还没有安装,解释一下当初富哥为啥说尽量不要用exe安装,用压缩包安装。
用exe安装,卸载麻烦,它会往注册表(操作系统、硬件设备以及客户应用程序得以正常运行和保存设置的核心“数据库”,也可以说是一个非常巨大的树状分层结构的数据库系统)里面走,相当于你卸载了,其实并没有卸载掉(想当初某学姐因为这个被迫重装了电脑系统,惨惨子)
我遇到的问题:
解决方法:安装了一个缺失的插件
成功进入mysql:
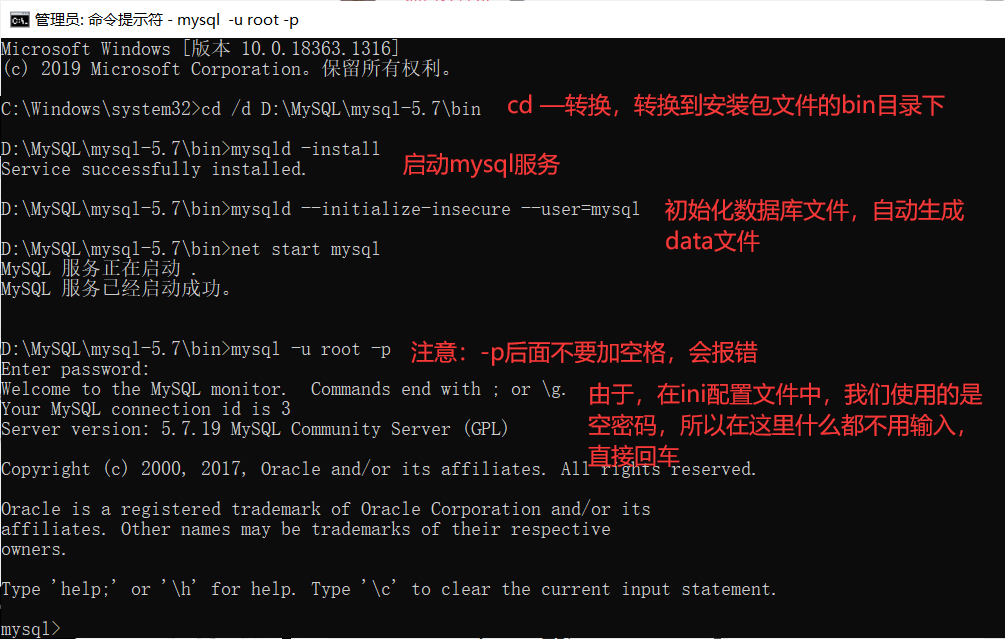
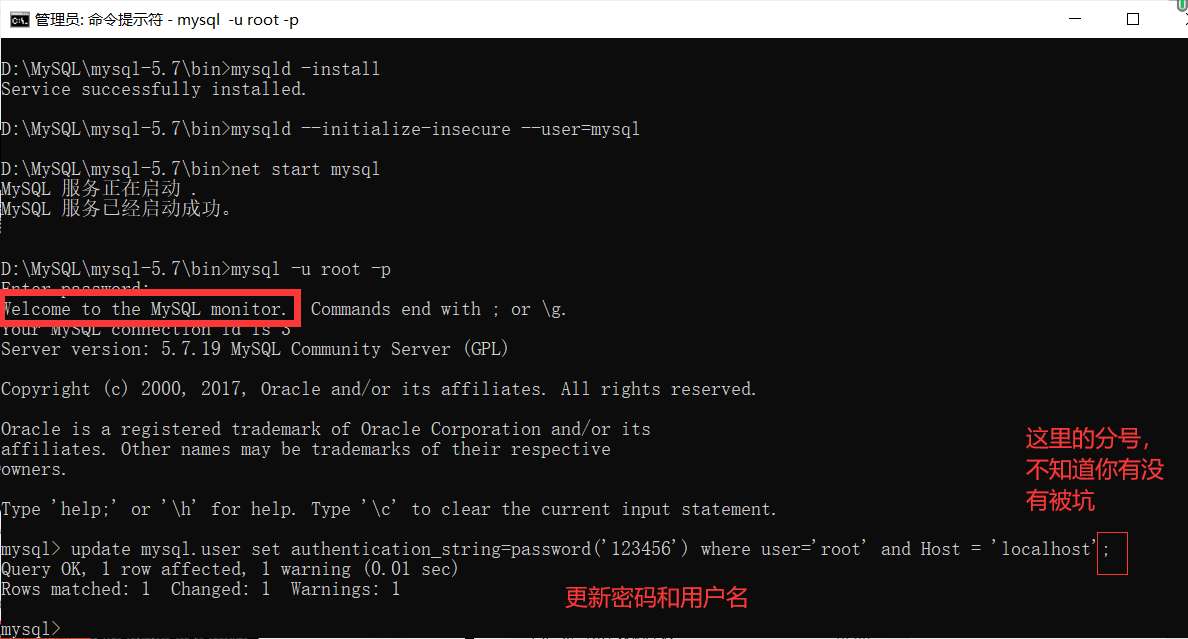
最后成功:
出了问题的,可以清空再来,清空服务命令:sc delete mysql
安装SQLyog
-
无脑安装
-
注册
名称:随意取
注册码:我在CSDN上找的
-
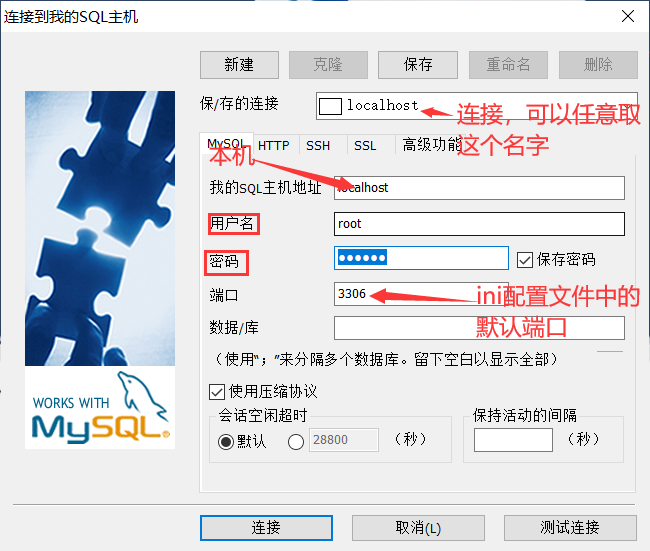
打开链接数据库
用户名/密码为之前在CMD中设置的
-
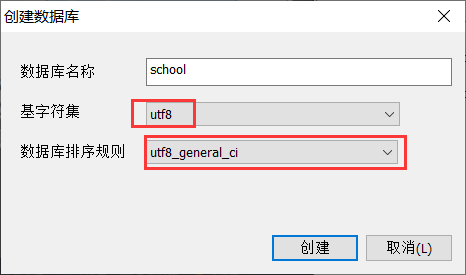
新建一个数据库 school
![image-20210215123553457]()
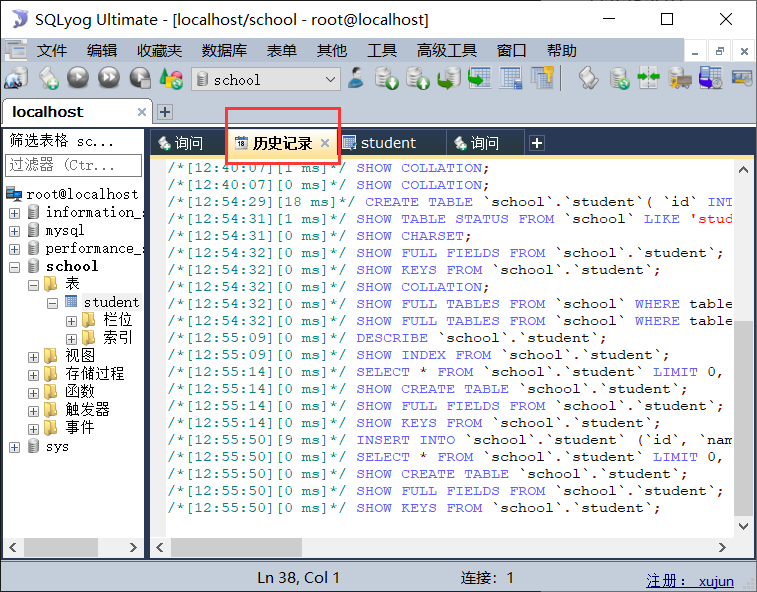
# 每一个SQLyog的执行操作,本质就是对应了一个sql,可以在软件的历史记录中查看
![image-20210215130031037]()
-
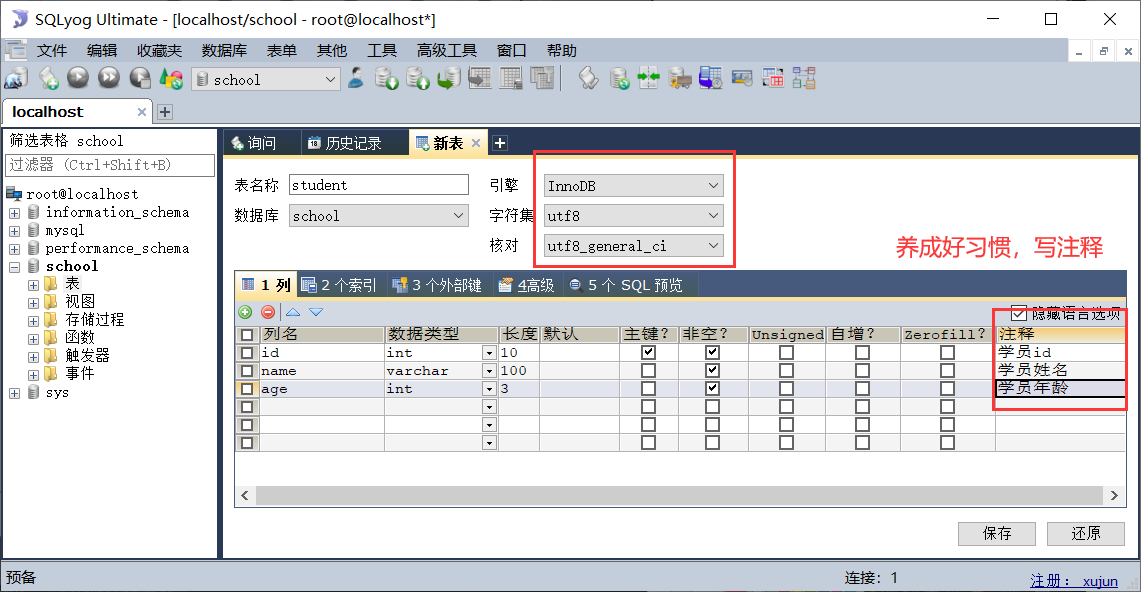
新建一张表 student
![image-20210215125413133]()
-
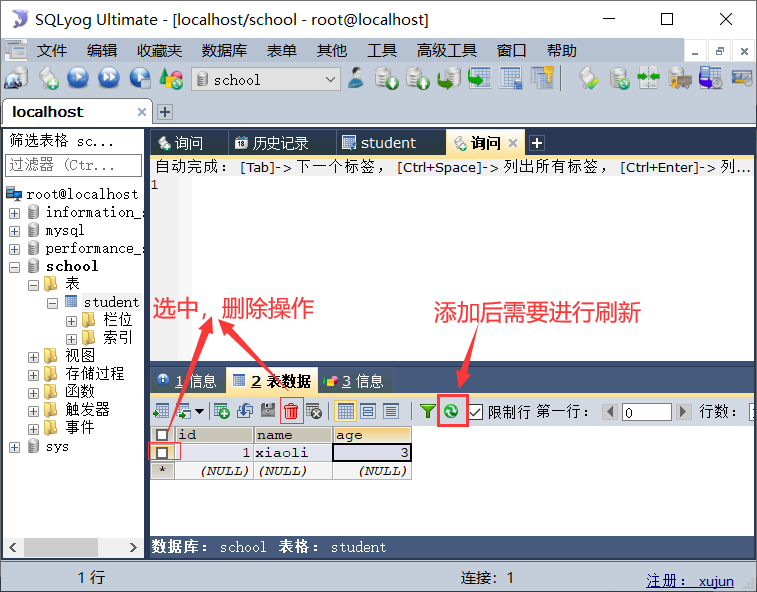
基操
![image-20210215125820744]()
基本的命令行操作
连接数据库
方法一:SQLyog连接(如上)
方法二:命令行连接
mysql -u root -p --连接数据库
顺便讲一下,sql的注释方式:
-
使用"#"
“#”的本质和“--”一样,但是不建议使用,markdown中就不支持它的高亮
-
#单行注释 #安装的时候,可能会 #skip-grant-tables #意思就是注释掉最开始的密码为空 -
使用 "-- " 注意,--后跟有一个空格(SQL 本来的注释)
-
MySQL单行注释方法二 -- 啦啦啦啦,好好学习 -
多行注释: 使用/* */
-
/* 啦啦啦啦啦,天天向上 */
update mysql.user set authentication_string=password('123456') where user='root' and Host = 'localhost'; --修改用户密码
flush privileges; --刷新权限
show databases; --展示所有的数据库
mysql> use school --切换数据库 use 数据库名
Database changed
show tables; --查看数据库中所有的表
describe student;--显示指定表的信息
create database westos;--创建一个数据库
exit;--退出连接
注:所有的代码语句都以“;”结尾!!!但是像“切换数据库这种是命令不是代码语句,不必加分号”
使用CMD不方便(不美观),直接使用SQLyog
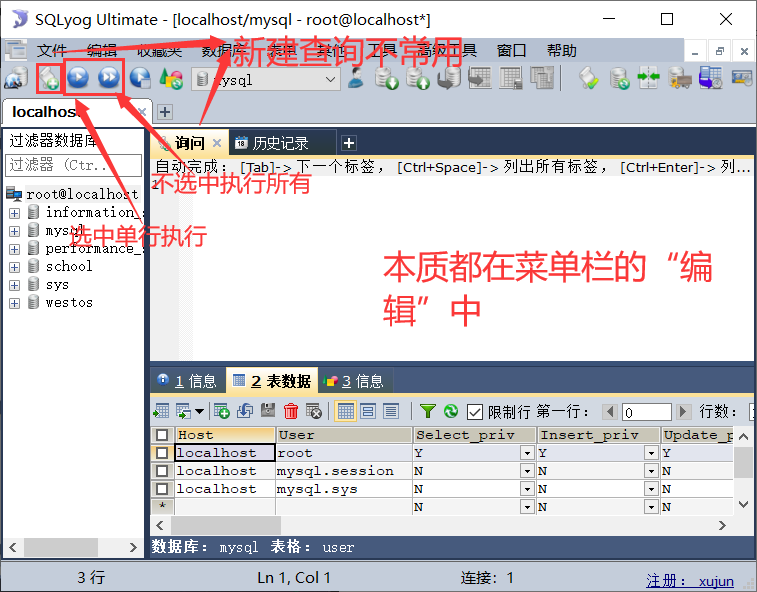
数据库语言
CRUD增删改查
- DDL 数据定义语言
- DML 数据操作语言
- DQL 数据查询语言
- DCL 数据控制语言
- TCL 事物控制语言(百度百科)
操作数据库
操作数据库 > 操作数据库中的表 > 操作数据库中表中的数据
mysql关键字不区分大小写
操作数据库
-
创建数据库(net)
CREATE DATABASE IF NOT EXISTS net --IF NOT EXISTS 是可选的 -
删除数据库(net)
DROP DATABASE IF EXISTS net ----IF EXISTS 是可选的 -
使用数据库
use `school` --如果你的表名或者是字段名是一个特殊字符,就需要` `(Tab键上面) -
查看数据库
SHOW DATABASES --查看所有的数据库
数据库的列类型(数据类型)
数值
-
tinyint 十分小的数据 1个字节
-
smallint 较小的数据 2个字节
-
mediumint 中等大小的数据 3个字节
-
**int 标准的整数 4个字节(常用) **
-
bigint 较大的数据 8个字节
-
float 浮点数 4个字节
-
double 浮点数 8个字节
以上浮点数存在精度问题,所以一般在金融计算的时候,一般都是使用decimal类型
-
decimal 字符串形式的浮点数
字符串
-
char 固定大小的字符串 0-255
-
varchar 可变字符串 0-65535(常用的变量,对应java中的String)
-
tinytext 微型文本 2^8-1
-
text 文本串 2^16-1(保存大文本)
char,varchar的单位事字节,tinytext和text的单位是比特,一个字节等于8个比特位
时间日期
对应java的类:java.util.Date
- date YYY-MM-DD 日期
- time HH:mm:ss 时间格式
- datatime YYY-MM-DD HH:mm:ss(最常用的时间格式)
- timestamp 时间戳,1970.1.1到现在的毫秒数(也较为常用)
- year 年份表示
null
空值,未知
注意:不要使用NULL进行运算,如果使用NULL进行计算,结果均为NULL
说完数据类型,随便说一下数据类型的长度:MySQL中数据类型的长度问题总结
数据库的字段属性(重)
Unsigned:
- 无符号的整数
- 声明了该列不能声明为负数
Zerofill:
-
0填充的
-
不足的位数,使用0来填充
例:int(3) 5 -> 005
自增:
-
通常理解为自增,自动在上一条记录的基础上+1(默认)
-
通常用来设计唯一的主键~index,必须是整数类型
-
可以自定义设置主键自增的起始值和步长
![image-20210215155059346]()
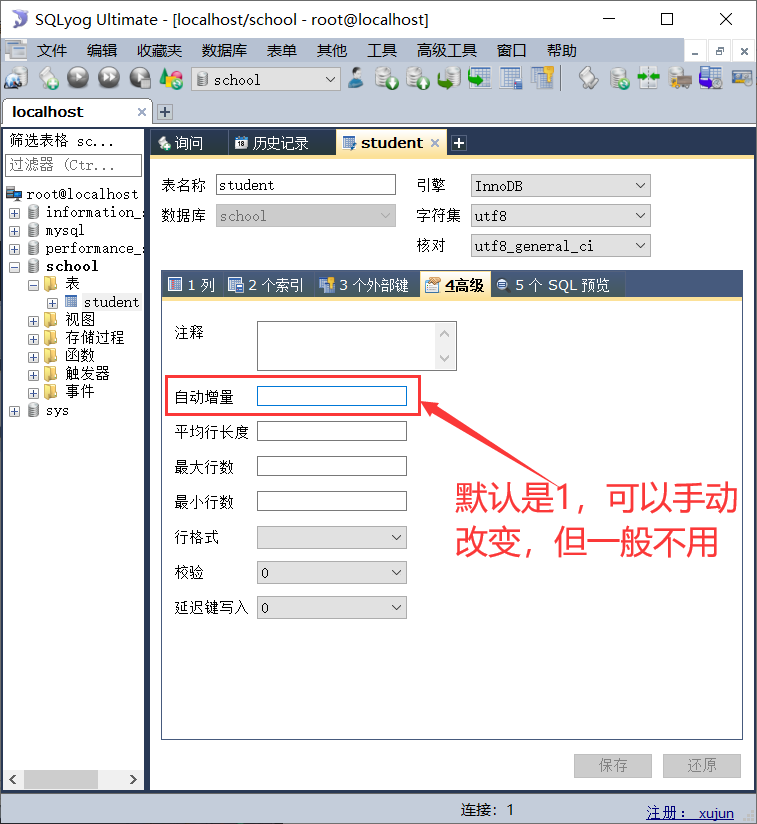
非空: null / not null
- 假设设置为 not null ,如果不给它赋值,就会报错
- 假设设置为null,如果不赋值,则默认为null
默认:
- 设置默认的值
创建数据库表(重)
-- 目标:创建一个school数据库
-- 创建学生表(列,字段),使用SQL创建
-- 学号,姓名,密码,性别,出生日期,家庭住址,邮箱
格式:
-- IF NOT EXISTS是可选的
CREATE TABLE IF NOT EXISTS 表名(
'字段名' 列类型 [属性][索引][注释],
'字段名' 列类型 [属性][索引][注释],
......
'字段名' 列类型 [属性][索引][注释]
)[表类型][字符集设置][注释]
-- 注意:()使用英文的括号,表的 名称 和 字段 尽量使用 ``(反单引号),防止和关键字冲突
-- 字符串使用单引号/双引号括起来!
-- 所有的语句后面加 英文的逗号(,),最后一个不用加
-- comment 注释
-- default 默认
-- AUTO_INCREMENT 自增
-- PRIMARY KEY 主键,一般一个表哦只有唯一的一个主键
CREATE TABLE IF NOT EXISTS `student`(
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',-- 10000
`name` VARCHAR(30) NOT NULL DEFAULT '匿名'COMMENT '姓名',
`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',
`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',
`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
三个命令(偷懒小妙招)
去SQLyog执行演示
SHOW CREATE DATABASE school -- 查看创建数据库的定义语句
SHOW CREATE TABLE student -- 查看student数据表的定义语句
DESCRIBE student -- 显示表的结构
-- DESCRIBE可写为 DESC
表类型
/*
关于数据库引擎
INNODB 默认使用
MYISAM 早些年使用的
*/
| MYISAM | INNODB | |
|---|---|---|
| 事务支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持(表锁) | 支持(行锁) |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间的大小 | 较小 | 较大,约为2倍 |
常规使用操作:
- MYISAM 节约空间,速度较快
- INNODB 安全性高,事务的处理,多表多用户操作
字符集设置
CHARSET=UTF8
不设置的话,会是mysql默认的字符集编码是Latin1(不支持中文)
--在my.ini中配置默认的编码
character-set-server=utf8
修改/删除数据表字段
-
修改
-- 修改表名 ALter TABLE 旧表名 RENAME AS 新表名 ALTER TABLE student RENAME AS student1 -- 增加表的字段 ALTER TABLE 表名 ADD 字段名 列属性 ALTER TABLE student1 ADD QQ INT(11) -- 修改表的字段(重命名,修改约束!) --ALTER TABLE 表名 MODIFY 字段名 列属性[] ALTER TABLE student1 MODIFY QQ VARCHAR(11) -- 修改约束 --ALTER TABLE 表名 CHANGE 旧名字 新名字 列属性[] ALTER TABLE student1 CHANGE QQ QQ1 INT(11) -- 字段重命名modify和change的区别:
- change用来字段重命名,不能修改字段类型和约束
- modify不用来字段重命名,只能修改字段类型和约束
-
删除
-- 删除表的字段 ALTER TABLE student1 DROP QQ -- 删除表(如果表存在的话,再删除) DROP TABLE IF EXISTS student
所有的创建和删除操作尽量加上判断,以免报错*
MySQL数据管理
外键(了解)
方式一:在创建表的时候,增加约束(麻烦,比较复杂)
-- 学生表的 gradeid 字段 要去引用年级表的 gradeid
-- 定义外键key
-- 给这个外键添加约束(执行引用)
CREATE TABLE IF NOT EXISTS `student`(
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` VARCHAR(30) NOT NULL DEFAULT '匿名'COMMENT '姓名',
`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',
`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',
`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',
`gradeid` INT(10) NOT NULL COMMENT '学生的年级',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY(`id`),
KEY `FK_gradeid`(gradeid), -- 定义外键key
CONSTRAINT `FK_gradeid` FOREIGN KEY (`gradeid`) REFERENCES `grade`(`gradeid`) -- 给这个外键添加约束(执行引用)
)ENGINE=INNODB DEFAULT CHARSET=utf8
CREATE TABLE IF NOT EXISTS `grade`(
`gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年级id',
`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',
PRIMARY KEY(`gradeid`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
删除有外键关系的表的时候,必须要先删除引用别人的表(从表,外键在的表是从表),再删除被引用的表(主表)
方式二:创建表成功后,添加外键关系
CREATE TABLE IF NOT EXISTS `grade`(
`gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年级id',
`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',
PRIMARY KEY(`gradeid`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
-- 学生表的 gradeid 字段 要去引用年级表的 gradeid
-- 定义外键key
-- 给这个外键添加约束(执行引用)
CREATE TABLE IF NOT EXISTS `student`(
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` VARCHAR(30) NOT NULL DEFAULT '匿名'COMMENT '姓名',
`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',
`sex` VARCHAR(2) NOT NULL DEFAULT '女' COMMENT '性别',
`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT '家庭住址',
`gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '学生的年级',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
ALTER TABLE `student`
ADD CONSTRAINT `FK_gradeid` FOREIGN KEY(`gradeid`) REFERENCES `grade`(`gradeid`);
-- ALTER TABLE 表名 ADD CONSTRAINT 约束名 FOREIGN(作为外键的列) REFERECES 哪个表(哪个字段)
以上的操作都是物理外键,数据库级别的外键,不建议使用(避免数据库过多造成困扰)
DML语言——数据操作语言(记得记住哦)
添加,插入语句(Insert)
-- 插入语句(添加)格式
INSERT INTO 表名(字段名1,字段名2,字段名3)values('值1','值2','值3')
-- 由于主键自增我们可以省略(如果不写表的字段,他就会一一匹配),但自增主键能使用null占位
-- 一般写插入语句要数据和字段一一对应
-- 插入字段
INSERT INTO `grade`(`gradename`) VALUES ('大四')
-- 插入多个字段
INSERT INTO `student`(`name`,`pwd`,`sex`)
VALUES('小李','555','男'),('小陈','666','女')
修改(Update)
-- 修改语句(格式),如果不指定条件的情况下,会改动所有的表
UPDATE 修改谁(表名) SET 原来的值 = 新值 (, 原来的值 = 新值) where (条件)
-- 修改单个属性
UPDATE `student` SET `name`='小李' WHERE id = 1;
-- 修改多个属性
UPDATE `student` SET `name`='小李',`email`='123456' WHERE id = 1;
删除(delete,truncate)
-
delete
DELETE FROM `student` -- 相当于删除表数据但是避免这样用 -- 删除数据(全部) DELETE FROM `student` -- 删除指定数据 DELETE FROM `student` WHERE id = 1delete 删除问题,重启数据库后,使用不同引擎,效果不同
- InnoDB 自增列会从1开始(因为是存在内存当中的,断电会丢失数据)
- MyISAM 继续从上一个自增量开始(存在文件中,不会丢失)
-
truncate
-- TRUNCATE 表名 TRUNCATE `STUDENT`
delete 和 truncate 的区别
相同:都能删除数据,都不会删除表结构
不同:
- truncate 重新设置自增列,计数器会归零
- truncate 不会影响事务
CREATE TABLE `test`(
`id` INT(4) NOT NULL AUTO_INCREMENT,
`coll` VARCHAR(20) NOT NULL,
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO `test`(`coll`)VALUES ('1'),('2'),('3')
DELETE FROM `test` -- 不会影响自增
TRUNCATE TABLE `test` -- 影响自增,自增归零
DROP TABLE IF EXISTS student
-- 删除操作前面说了一个DROP,但是DROP是直接删除整个表,包括表结构
WHERE条件子句
作用:检索数据中符合条件的值
搜索的条件就是由一个或多个表达式组成
操作符会返回布尔值,为true才会执行操作
| 操作符 | 含义 | 范围 | 结果 |
|---|---|---|---|
| = | |||
| <> / != | 不等于 | ||
| > | |||
| < | |||
| >= | |||
| <= | |||
| BETWEEN...AND... | 在某范围内 | ||
| AND && | 都真才真 | a and b/a&&b | |
| OR || | 都假才假 | a or b/a || b | |
| NOT ! | 非 | not a/ ! a |
尽量使用英文字母
DQL查询数据( !!)
Data Query Language——数据查询语言
- 数据库中最核心的语言,最重要的语句
- 所有的查询(简单查询/复杂查询)操作都是用:Select
指定查询字段
--格式
SELECT 字段... FROM 表
-- 查询全部的学生 SELECT 字段 FROM 表
SELECT * FROM student1
-- 查询指定字段
SELECT `studentno`,`studentname` FROM student1
-- 给查询结果起别名 AS
SELECT `studentno` AS 学号,`studentname` AS 学生姓名 FROM student1
-- 拼接字符串 函数 Concat(a,b)
SELECT CONCAT('姓名:',studentname) AS 新名字 FROM student1
去重数据(distinct)
// unique
作用:去除SELECT查询出来的结果中重复的数据,重复的数据只显示一条
-- 查询全部的考试成绩
SELECT * FROM result
-- 查询有哪些同学参加了考试
SELECT `studentno` FROM result
-- 发现重复数据,去重
SELECT DISTINCT `studentno` FROM result
数据库的列(表达式)
- 文本值
- 列
- null
- 函数
- 计算表达式
- 系统变量
-- 查看系统版本(函数)
SELECT VERSION()
-- 计算(表达式)
SELECT 100*3-1 AS 计算结果
-- 查询自增的步长(变量)
SELECT @@auto_increment_increment
-- 学员考试成绩均+1分
SELECT `studentno`,`studentresult`+1 AS 提分后 FROM result
模糊查询:比较运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| IS NULL | a is null | 如果操作符为NULL,结果为真 |
| IS NOT NULL | a is not null | 如果操作符不为NULL,结果为真 |
| BETWEEN...AND... | a between b and c | 若a在b和c之间,则结果为真 |
| LIKE | a like b | SQL匹配,如果a匹配b,则结果为真 |
| IN | a in(a1,a2,a3) | 假设a在a1,或者a2...其中的某一个值中,结果为真 |
-- like 结合%(代表0到任意一个字符) _(一个字符)
-- 查询姓张的同学
SELECT `studentno`,`studentname` FROM `student1`
WHERE studentname LIKE '张%'
-- 查询姓氏后面,只有一个字的
SELECT `studentno`,`studentname` FROM `student1`
WHERE studentname LIKE '张_'
-- 查询名字中间带强字的 %强%
SELECT `studentno`,`studentname` FROM `student1`
WHERE studentname LIKE '%强%'
--IN,查询具体的一个或者多个值
-- 查询100,101号学生
SELECT `studentno`,`studentname` FROM `student1`
WHERE studentno IN(100,101);
--NULL NOT NULL
-- 查询地址为空的学生 null or ''
SELECT `studentno`,`studentname` FROM `student1`
WHERE address='' OR address IS NULL
-- 查询出生日期不为空的学生
SELECT `studentno`,`studentname` FROM `student1`
WHERE `borndate` IS NOT NULL
联表查询——JOIN 对比
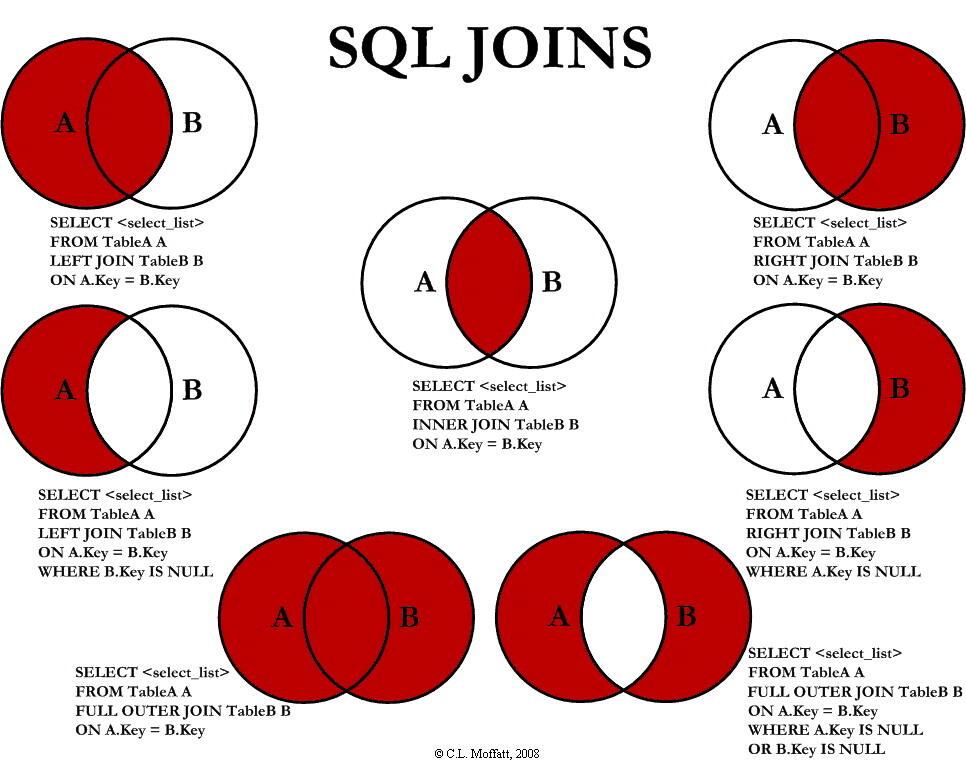
-- INNER 交集
SELECT s.studentno,`studentname`,`subjectno`,`studentresult`
FROM `student1` AS s
INNER JOIN `result` r -- AS 可省略
ON s.studentno = r.studentno
-- RIGHT JOIN
SELECT s.studentno,`studentname`,`subjectno`,`studentresult`
FROM `student1` s
RIGHT JOIN `result` r
ON s.studentno = r.studentno
-- LEFT JOIN 查询缺考的同学
SELECT s.studentno,`studentname`,`subjectno`,`studentresult`
FROM `student1` s
LEFT JOIN `result` r
ON s.studentno = r.studentno
WHERE `studentresult` IS NULL
-- join on用在多表。查完的结果是一张临时表,然后用where再筛选
| 操作 | 描述 |
|---|---|
| Inner join | 如果表中至少有一个匹配,就返回行 |
| left join | 会从左表中返回所有的值,即使右表中没有匹配 |
| right join | 会从右表中返回所有的值,即使左表中没有匹配 |
通俗点讲:left join以左边表为基准,左边表的所有on元素值都会列出来,right同理;而inner要两张表都有的元素才会列出来
Mysql 多表联合查询效率分析及优化,看看笛卡尔积(交叉连接),有助于理解
ON 和 WHERE 的区别:
-
join on 连接查询
where 等值查询
-
on是先筛选后关联,where是先关联后筛选
-
on用于批量,where用于单个
-
where在inner join中可以用,但不能用于left join和right join
自连接(了解,很有意思)
概念:自己的表和自己的表连接。
核心:一张表拆为两张一样的表即可
-- 先创建一个分类表
CREATE TABLE `school`.`category`(
`categoryid` INT(3) NOT NULL COMMENT 'id',
`pid` INT(3) NOT NULL COMMENT '父id 没有父则为1',
`categoryname` VARCHAR(10) NOT NULL COMMENT '种类名字',
PRIMARY KEY (`categoryid`)
) ENGINE=INNODB CHARSET=utf8 COLLATE=utf8_general_ci;
INSERT INTO `school`.`category` (`categoryid`, `pid`, `categoryname`)
VALUES ('2', '1', '信息技术'),
('3', '1', '软件开发'),
('5', '1', '美术设计'),
('4', '3', '数据库'),
('8', '2', '办公信息'),
('6', '3', 'web开发'),
('7', '5', 'ps技术');
-- 查询父子信息
SELECT a.`categoryname` AS '父类',b.`categoryname` AS '子类'
FROM `category`AS a,`category` AS b
WHERE a.`categoryid`= b.`pid`
把上诉表拆分出来就是:
父类:
| categoryid | categroyname |
|---|---|
| 2 | 信息技术 |
| 3 | 软件开发 |
| 5 | 美术设计 |
子类:
| pid | categoryid | categoryname |
|---|---|---|
| 3 | 4 | 数据库 |
| 3 | 8 | web开发 |
| 2 | 6 | 办公信息 |
| 5 | 7 | 美术设计 |
操作:查询父类对应的子类关系
| 父类 | 子类 |
|---|---|
| 信息技术 | 办公信息 |
| 软件开发 | 数据库 |
| 软件开发 | web开发 |
| 美术设计 | ps技术 |
ps:感觉有点像树形结构(俺画的有点丑)
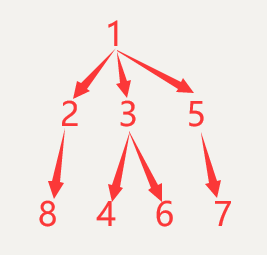
分页(limit)和排序(order by)
排序:
- 升序 ASC
- 降序 DESC
--排序格式
ORDER BY 通过哪个字段排序 怎么排(ASC/DESC)
-- 查询参加考试学生的成绩,并按照学生成绩进行排序
SELECT s.studentno,`studentname`,`subjectno`,`studentresult`
FROM `student1` AS s
INNER JOIN `result` r
ON s.studentno = r.studentno
ORDER BY studentresult ASC -- 升序
ORDER BY studentresult DESC -- 降序
分页:
- 作用:缓解数据库压力,给人的体验更好
-- 分页(limit是所有语句的最后一行)
-- 分页格式
limit 当前页(起始值),页面的大小
-- 相当于:第n+1页,每页显示几行数据
SELECT s.studentno,`studentname`,`subjectno`,`studentresult`
FROM `student1` s
INNER JOIN `result` r
ON s.studentno = r.studentno
ORDER BY studentresult ASC
LIMIT 0,2
-
关于网页页面:当前页,总的页数,页面的大小
-- pageSize: 页面大小 -- (n-1)*pageSIze: 起始值 -- n: 当前页 -- 总页数 = 数据总数/页面大小(向上取整)
例子:
-- 查询 高等数学-2 课程成绩排名前二的学生,并且分数要大于50的学生信息(学号,姓名,课程名称,分数)
SELECT s.`studentno`,`studentname`,`subjectname`,`studentresult`
FROM `student1` s
INNER JOIN `result` r
ON s.studentno = r.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname = '高等数学-2' AND studentresult >= 50
ORDER BY studentresult DESC -- 降序
LIMIT 0,2 -- 当前一页只显示排名前二
分组和过滤(后面讲函数的时候倒回来说)
-- 查询不同课程的平均分,最高分,最低分,且平均分大于50
-- 核心:根据不同的课程分组
SELECT `subjectname`,AVG(`studentresult`) AS 平均分,MAX(`studentresult`) AS 最高分,MIN(`studentresult`) AS 最低分
FROM `result` r
INNER JOIN `subject` sub
ON r.`subjectno` = sub.`subjectno`
GROUP BY r.`subjectno` -- 通过什么来分组
HAVING 平均分>50
/*写成 where 平均分>50,会报错嗷!
平均分的实质是:AVG(`studentresult`) AS 平均分,where不能使用聚集函数,所以使用having,对函数过滤用having。
where是判断每一条记录,having二次过滤可以判断组
*/
-- WHERE 指定结果需要满足的条件
-- GROUP BY 指定结果按照哪几个字段来分组
-- HAVING 过滤分组的记录必须满足的次要条件(过滤分组后的信息,条件和where是一样的,但是位置不同)
子查询和嵌套查询(由里及外)
本质:在where语句中嵌套一个子查询语句
子查询不一定必须出现在select语句内部,只是出现在select语句内部的时候比较多
where(select * from)
-- 查询 高等数学-2 的所有考试结果(学号,科目编号,成绩),降序排序
-- 方式一:使用连接查询
SELECT `studentno`,r.`subjectno`,`studentresult`
FROM `result` r
INNER JOIN `subject` sub
ON r.`subjectno` = sub.`subjectno`
WHERE `subjectname` = '高等数学-2'
ORDER BY `studentresult` DESC
-- 方式二:使用子查询
SELECT `studentno`,`subjectno`,`studentresult`
FROM `result`
WHERE `subjectno` = (
SELECT `subjectno` FROM `subject`
WHERE `subjectname` = '高等数学-2'
)
ORDER BY `studentresult` DESC
-- 查询 高等数学-2 的课程编号
-- select `subjectno` from `subject` where `subjectname` = '高等数学-2'
-- 有点相当于IN子句,不过这个范围集要自己select出来
-- 使用嵌套查询
-- 查询课程为 高等数学-2 且分数不小于 50 的同学的学号和姓名(在之前问题上增加一个分数)
SELECT `studentno`,`studentname`
FROM `student1`
WHERE `studentno` IN (
SELECT `studentno` FROM `result` WHERE `studentresult` >= 50
AND `subjectno` = (
SELECT `subjectno` FROM `subject` WHERE `subjectname` = '高等数学-2'
)
)
相对于连表,子查询会花费更多的时间(运行效率),但是按逻辑,子查询效率更高
select小结(别问为啥没手打,问就是懒,懒鬼本人)
MySQL的函数
不记得的可以去官网查!不认识英文,用谷歌可以页面翻译(嘿嘿嘿!小机灵鬼本人)
常用函数
(名字打假,它才不常用,问就是狂神说的)
-- 所有的查询要获得一个结果都需要用SELECT
-- 数学运算(自个感觉我还是比较常用)
SELECT ABS(-8) -- 绝对值
SELECT CEILING(9.4) -- 向上取整
SELECT FLOOR(4.3) -- 向下取整
SELECT RAND() -- 随机数(0到1之间的)
SELECT SIGN(10) -- 判断数的符号,负数返回-1,正数返回1
-- 字符串函数
SELECT CHAR_LENGTH('你这个女人居然妄图教会我sql') -- 字符串长度
SELECT CONCAT('膜拜','大佬们','!') -- 拼接字符串
SELECT LOWER('CAIJI') -- 转大写为小写
SELECT UPPER('caiji') -- 转小写为大写
SELECT INSTR('xiaoli','l') -- 搜索字符串中子串首字母的位置,字符串下标从1开始
SELECT REPLACE('今天没有好好学习','没有','有') -- 替换出现指定的字符串,将'没有'替换成'有'
-- 例:将查询姓张的同学改成跟俺姓
SELECT REPLACE(studentname,'张','李') FROM student1
WHERE studentname LIKE '张%'
-- 时间和日期函数(重点!)
SELECT CURRENT_DATE() -- 获取当前日期
SELECT NOW() -- 获取当前的日期和时间
-- 只要年月日
SELECT YEAR(NOW())
SELECT SYSDATE() -- 系统时间
聚合函数(常用)
| 函数名称 | 描述 |
|---|---|
| COUNT() | 计数 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| ... | ... |
SELECT COUNT(studentname) FROM student1 -- COUNT(指定列/字段),会忽略所有的null值(如果有null值得话,会不记数)
-- 下面两个俺感觉差异不大,本质都是计算行数
SELECT COUNT(*) FROM student1 -- COUNT(*),不会忽略null值
SELECT COUNT(1) FROM student1 -- COUNT(1),不会忽略null值
分组和过滤:(上面)
事务
基础:
借鉴一下dalao是怎么讲的,嘿嘿事务ACID理解
原子性(Atomicity):
- 要么都成功
- 要么都失败
一致性(Consistency):
- 无论怎么样,最后的总值不变
- 最终一致性:事务前后的数据完成性要保证一致
持久性(Durability):
- 事务没有提交:恢复原状
- 事务已经提交:持久化到数据库(事务一旦提交就不可逆)
隔离性(Isolation):
- 一旦隔离失败,会产生问题:
- 脏读:指一个事物读取了另一个事务未提交的数据
- 不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同(不一定是错误,只是某些场合不对)
- 虚读(幻读):值在一个事务内读取到了别的事务插入的数据,导致前后读取不一致
操作:
-- mysql 是默认开启事务自动提交的
-- 手动处理事务
SET autocommit = 0 -- 关闭自动提交
START TRANSACTION -- 事务开启,标记一个事务的开始,从这个之后的 sql 都在同一个事务内
-- 过程(了解)
SAVEPOINT 保存点名 -- 设置一个事务的保存点
ROLLBACK TO SAVEPOINT -- 回滚到保存点
RELEASE SAVEPOINT -- 撤销保存点
-- 提交:持久化(成功!)
COMMIT
-- 回滚:回到的原来的样子(失败)
ROLLBACK
-- 事务结束
SET autocommit = 1 -- 开启自动提交
案例:
CREATE DATABASE shop CHARACTER SET utf8 COLLATE utf8_general_ci
USE shop
CREATE TABLE `account`(
`id` INT(3) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(30) NOT NULL,
`money` DECIMAL(9,2) NOT NULL, -- DECIMAL(9,2)代表一个九位数,其中小数位是两位
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO `account`(`name`,`money`)
VALUES ('A',1000.00),('B',200.00)
-- 模拟转账(事务的过程)
SET autocommit = 0; -- 关闭自动提交
START TRANSACTION -- 开启一个事物
-- 以下这两部属于同一个过程
UPDATE `account` SET `money`=`money`-200 WHERE `name` = 'A' -- A减200
UPDATE `account` SET `money`=`money`+200 WHERE `name` = 'B' -- B加200
COMMIT; -- 提交事务,就被持久化了
ROLLBACK; -- 回滚,若没提交就回滚,相当于之前的操作白做了
SET autocommit = 1; -- 恢复默认值
索引
定义:索引(index)是帮助MySQL高效获取数据的数据结构(索引的本质:数据结构)
索引的分类
在一个表中,主键索引只能有一个,唯一索引可以有多个(唯一是指字段唯一)
- 主键索引(PRIARY KEY)
- 唯一的标识:主键不可重复,只能有一个列
- 唯一索引(UNIQUE KEY)
- 避免重复的列出现,唯一索引可以重复,即一个表中可以标识多个唯一索引
- 常规索引(KEY/INDEX)
- 默认的,index/key关键字来设置
- 全文索引(FullText)
- 在特定的数据库引擎下才有,MyISAM
- 快速定位数据
索引的使用
-- 显示所有的索引信息
SHOW INDEX FROM student1
-- 在创建表的时候给字段增加索引
-- 创建完毕后,增加所有
-- 表已经创建完毕了,增肌一个全文索引 索引名(列名)
ALTER TABLE school1.student1 ADD FULLTEXT INDEX `studentname`(`studentname`);
-- CREATE INDEX 索引名 ON 表(字段)
-- id_ 表名 _ 字段名 ---> 索引命名
CREATE INDEX id_app_user_name ON app_user(`name`);
-- explain 分析sql执行的状况
EXPLAIN SELECT * FROM student1; -- 常规索引/非全文索引
EXPLAIN SELECT * FROM student1 WHERE MATCH(`studentname`) AGAINST('赵');
索引的测试
CREATE TABLE `app_user` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) DEFAULT '',
`eamil` VARCHAR(50) NOT NULL,
`phone` VARCHAR(20) DEFAULT '',
`gender` TINYINT(4) UNSIGNED DEFAULT '0',
`password` VARCHAR(100) NOT NULL DEFAULT '',
`age` TINYINT(4) DEFAULT NULL,
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
-- 插入100万条数据
DELIMITER $$
-- 写函数之前必须要写,标志 (界定符)
CREATE FUNCTION mock_data1()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO app_user(`name`,`eamil`,`phone`,`gender`,`password`,`age`)
VALUES(CONCAT('用户',i),
'2199932534@qq.com',CONCAT('18',
FLOOR(RAND()*((999999999-100000000)+100000000))),
FLOOR(RAND()*2),
UUID(),
FLOOR(RAND()*100));
SET i=i+1;
END WHILE;
RETURN i;
END;
SELECT mock_data1()
SELECT * FROM app_user WHERE `name` = '用户11111'; -- 0.450 sec
SELECT * FROM student -- 0.009 sec
CREATE INDEX id_app_user_name ON app_user(`name`) -- 创建索引需要耗费时间,3.077 sec
SELECT * FROM app_user WHERE `name` = '用户11111'; -- 创建索引之后再查询,0.009 sec
-- 索引在小数据量的时候,用处不大,但在大数据的时候,区别十分明显
索引的原则
- 索引不是越多越好
- 不要对经常变动的数据加索引(变动的数据在更新时反而会拖慢性能)
- 小数据量的表不需要加索引
- 索引一般加在常用来查询的字段上
权限管理和备份
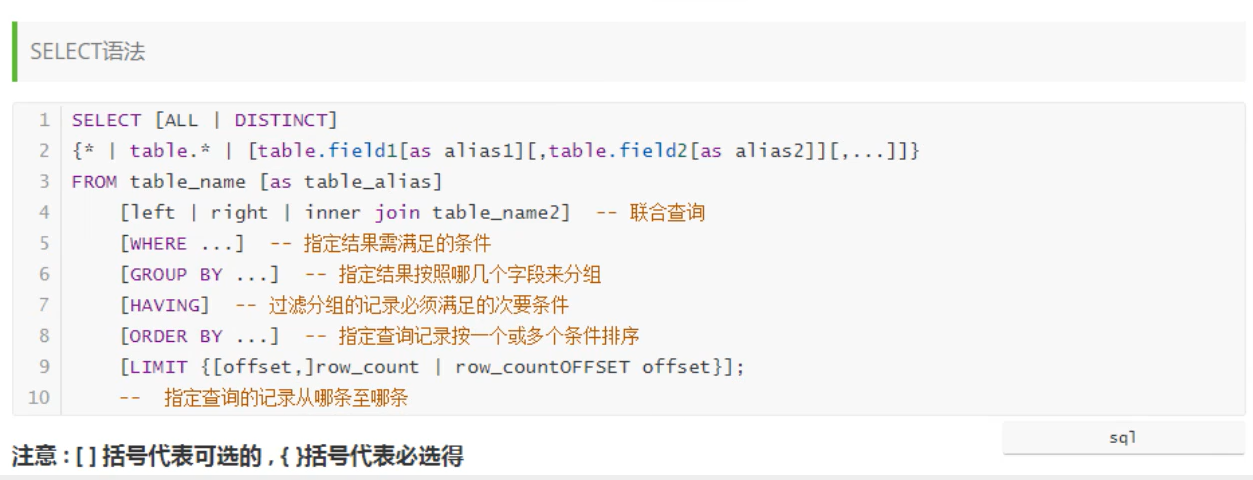
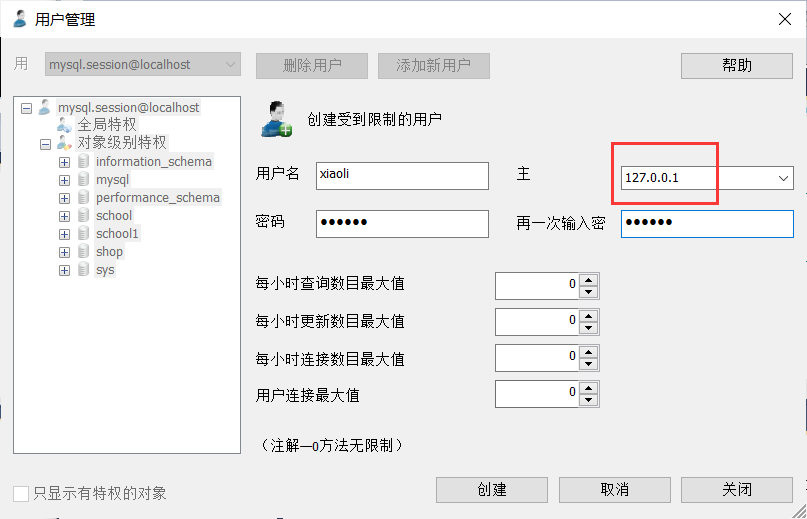
用户管理
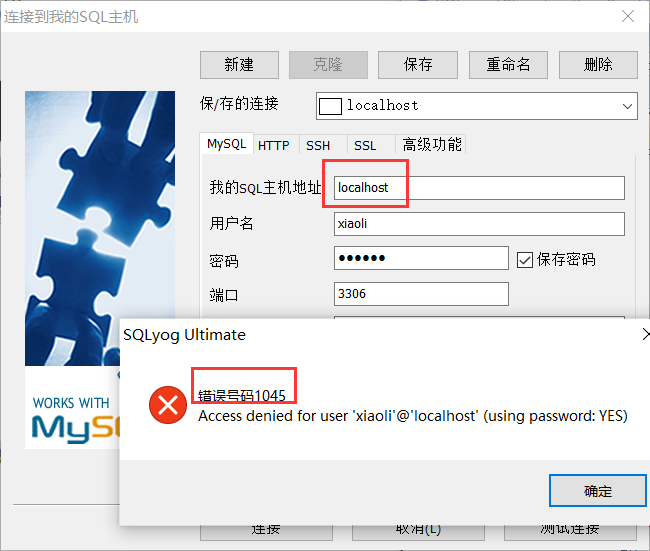
SQLyog可视化管理
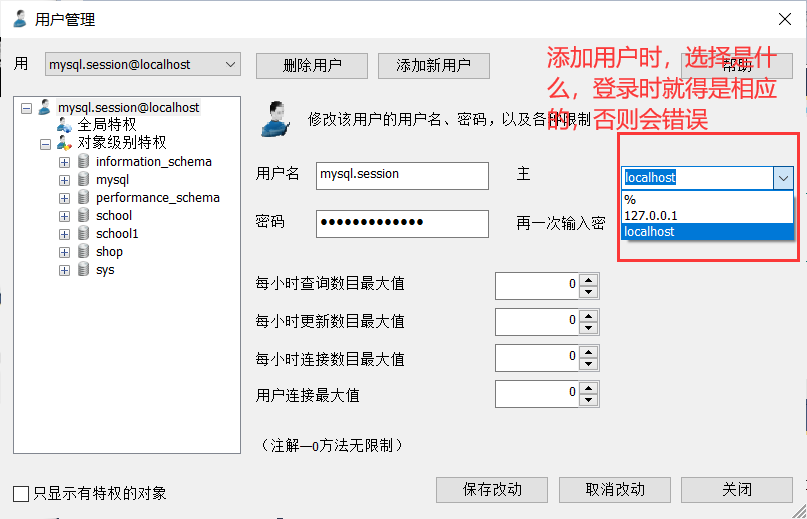
相同成功:
不同失败:
SQL命令操作
本质:对mysql数据库下的user表的增删改查
-- 创建用户
-- 格式:CREATE USER 用户名 IDENTIFIED BY '密码'
CREATE USER xiaoli -- 创建成功
IDENTIFIED BY '123456' -- 设置密码
-- 修改当前用户密码
SET PASSWORD = PASSWORD('111111')
-- 修改指定用户密码
SET PASSWORD FOR xiaoli = PASSWORD('111111')
-- 重命名
-- 格式:RENAME USER 原来名字 TO 新名字
RENAME USER xiaoli TO dali
-- 用户授权
-- ALL PRIVILEGES 包括所有的权限,除了给别人授权
GRANT ALL PRIVILEGES ON *.* TO dali -- *.* 表示该用户所有的库.表
-- 查询指定用户的权限
SHOW GRANTS FOR dali
-- 查询系统权限
SHOW GRANTS FOR root@localhost
-- root用户权限:Grants for root@localhost
GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION
-- 撤销权限
REVOKE ALL PRIVILEGES ON *.* FROM dali
-- 删除用户
DROP USER dali
备份
作用
- 保证重要数据不丢失
- 数据转移
备份方式
-
直接拷贝物理文件——data
-
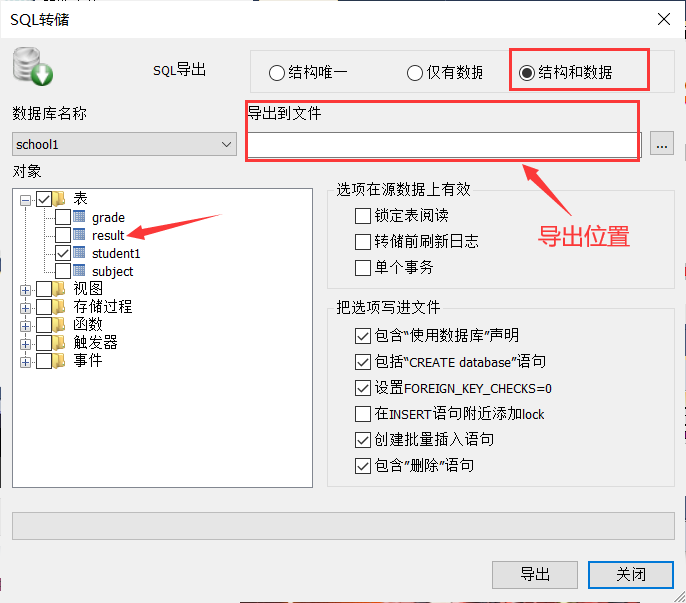
在Sqlyog中用可视化工具手动导出
![image-20210220172130246]()
-
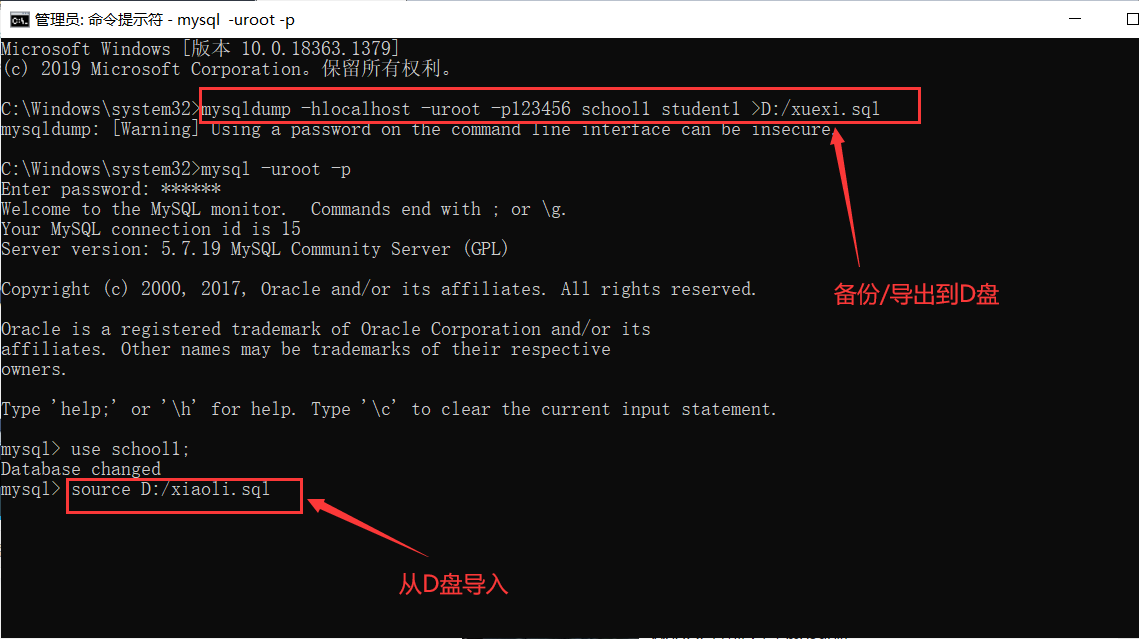
使用命令行导出 mysqldump(CMD)
-- 导出格式:mysqldump -h 主机 -u 用户名 -p 密码 数据库 表1,表2,表3 > 物理磁盘位置/文件名 mysqldump -hlocalhost -uroot -p123456 school1 student1 >D:/xuexi.sql -- 导入(在已启动并登录mysql的情况下,切换到指定数据库) mysql> use school1; Database changed mysql> source D:/xiaoli.sql![image-20210220174110470]()
数据库设计
设计原因:数据库比较复杂,就需要设计
良好的数据库设计:
- 节省内存空间(避免数据冗余,浪费空间)
- 保证数据库的完整性(出现异常,数据库删除插入都比较麻烦),屏蔽使用物理外键
- 程序的性能好,方便开发系统
设计数据库的步骤
- 分析需求:分析业务和需要处理的数据库的需求
- 概要设计:设计关系图E-R图
例子:个人bolg
- 收集信息,分析需求
- 用户表(用户登录住校,用户的个人信息,写博客,创建分类)
- 分类表(文章分类,谁创建的)
- 文章表(文章的信息)
- 评论表
- 友链表(友链信息)
- 说说表(发表心情)
- 标识实体(把需求落地到字段)
设计规范:三大范式
为什么需要数据规范化
- 信息重复
- 更新异常
- 插入异常:无法正常显示信息
- 删除异常:丢失有效的信息
三大范式
[关系型数据库设计:三大范式的通俗理解](https://www.cnblogs.com/wsg25/p/9615100.html)
第一范式(1NF)
原子性:保证每一列不可再分(每个列表述清楚)
第二范式(2NF)
前提:满足第一范式
每张表只描述一件事情(每张表表述清楚)
第三范式(3NF)
前提:满足第一范式和第二范式
需要确保数据表中的每一列数据和主键直接相关,二不能间接相关
规范性 和 性能 的问题
阿里规定:关联查询的表不得超过三张表
- 考虑商业化的需求和目标(成本,用户体验)数据库的性能更加重要
- 在规范性能的问题的时候,需要适当的考虑一下 规范性
- 故意给某些表增加冗余的字段(从多表查询中变为单表查询)
- 故意增加一些计算列,索引也行(但是索引也是比较占内存的),从大数据量降低为小数据量的查询

 浙公网安备 33010602011771号
浙公网安备 33010602011771号