
使用正则表达式,取得点击次数,函数抽离
1. 用正则表达式判定邮箱是否输入正确。
import re
def isEmail(email): #声明函数isEmail实现邮箱格式验证
if re.match("^.+\\@(\\[?)[a-zA-Z0-9\\-\\.]+\\.([a-zA-Z]{2,3}|[0-9]{1,3})(\\]?)$", email):
print('邮箱格式正确!')
else:
print('邮箱格式不正确!')
isEmail('1807772746@qq.com')#调用函数isEmail,传入参数1807772746@qq.com
效果演示如下图所示:

2. 用正则表达式识别出全部电话号码。
str='''版权所有:广州商学院 地址:广州市黄埔区九龙大道206号
学校办公室:020-82876130 招生电话:020-82872773
粤公网安备 44011602000060号 粤ICP备15103669号'''
telePhones=re.findall('(\d{3,4})-(\d{6,8})',str)
print(telePhones)
效果演示如下图所示:
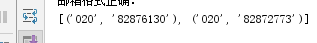
3. 用正则表达式进行英文分词。re.split('',news)
news='''Always heard puzzled how English email for friends, worry about don't understand the habit of foreigners email be rude, and worry that use too much E-mail "routine" is its logic is not clear. From today, we will learn some polite and not wordy English email writing! The first sentence of an email is always difficult to begin with.''' word=re.split(r'[\s,.:;?\!"]',news) print(word)
效果演示如下图所示:

4. 使用正则表达式取得新闻编号
import re
newsUrl='http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html'
res=re.match('http://news.gzcc.cn/html/2018/xiaoyuanxinwen_(.*).html',newsUrl).group(1).split('/')[-1]
# res=re.search('\_(.*).html',newsUrl).group(1)
# res=re.findall('\_(.*).html',newsUrl)[0]
print(res)
效果演示如下图所示:

5. 生成点击次数的Request URL

6. 获取点击次数
import requests
res=requests.get('http://oa.gzcc.cn/api.php?op=count&id=9183&modelid=80')
res.encoding="utf-8"
result=int(res.text.split(".html")[-1].lstrip("(')").rstrip("');"))
print(result)
效果演示如下图所示:

7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
import requests
import re
newsUrl = 'http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html'
def getClickCount(newsUrl):
newsId = re.search('\_(.*).html',newsUrl).group(1).split('/')[-1]
res = requests.get('http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId))
return (int(res.text.split('.html')[-1].lstrip("(')").rstrip("');")))
myClick = getClickCount(newsUrl)
print(myClick)
效果演示如下图所示:

8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
import requests
import re
from bs4 import BeautifulSoup
# 获取点击次数
def click(url):
# urll = 'http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html'
urll = url
num = re.findall('\d{1,4}/\d{1,4}', urll)
num = num[0].split('/')[1]
# print(num)
ress = requests.get('http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(num))
ress.encoding = 'utf-8'
text = ress.text
fi = re.findall('\d{1,4}', text)[-1]
return fi
url = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
news = soup.select('li')
for new in news:
if len(new.select('.news-list-title')) > 0:
title = new.select('.news-list-title')[0].text # 标题
aurl = new.select('a')[0].attrs['href'] # URL
clicknum = click(aurl)
text = new.select('.news-list-description')[0].text # 正文
print(title + '\n' + text + '\n' + aurl)
res2 = requests.get(aurl)
res2.encoding = 'utf-8'
soup2 = BeautifulSoup(res2.text, 'html.parser')
info = soup2.select('.show-info')[0].text
info = info.lstrip('发布时间:').rstrip('点击:次')
# print(info)
time = info[:info.find('作者')] # 发布时间
author = info[info.find('作者:') + 3:info.find('审核')] # 作者
check = info[info.find('审核:') + 3:info.find('来源')] # 审核
source = info[info.find("来源:") + 3:info.find('摄影')] # 来源
print(time, author, check, source, clicknum, end="")
if (info.find("摄影:") > 0):
photogra = info[info.find("摄影:") + 3:] # 来源
print(photogra + '\n')
else:
print('\n')
效果演示如下图所示:

