

分离,参数化,测试报告,数据驱动4种文件
分离测试固件
@staticmethod和@classmethod是python中的两个装饰器(装饰器理解请见:python装饰器)。
@staticmethod将函数转换成为一个静态方法,@classmethod将函数转换成为一个类方法。

以下是分离出的初始化信息
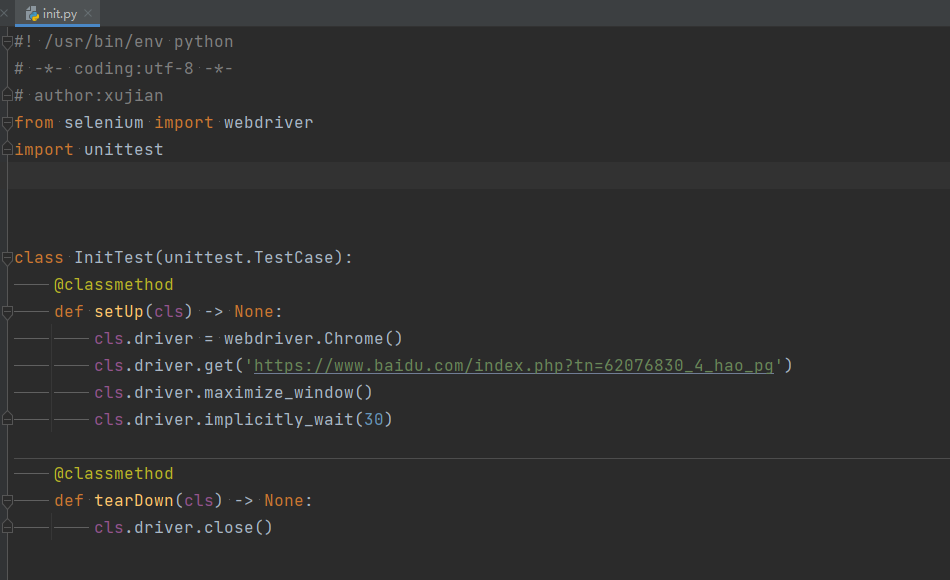
下面直接写测试用例
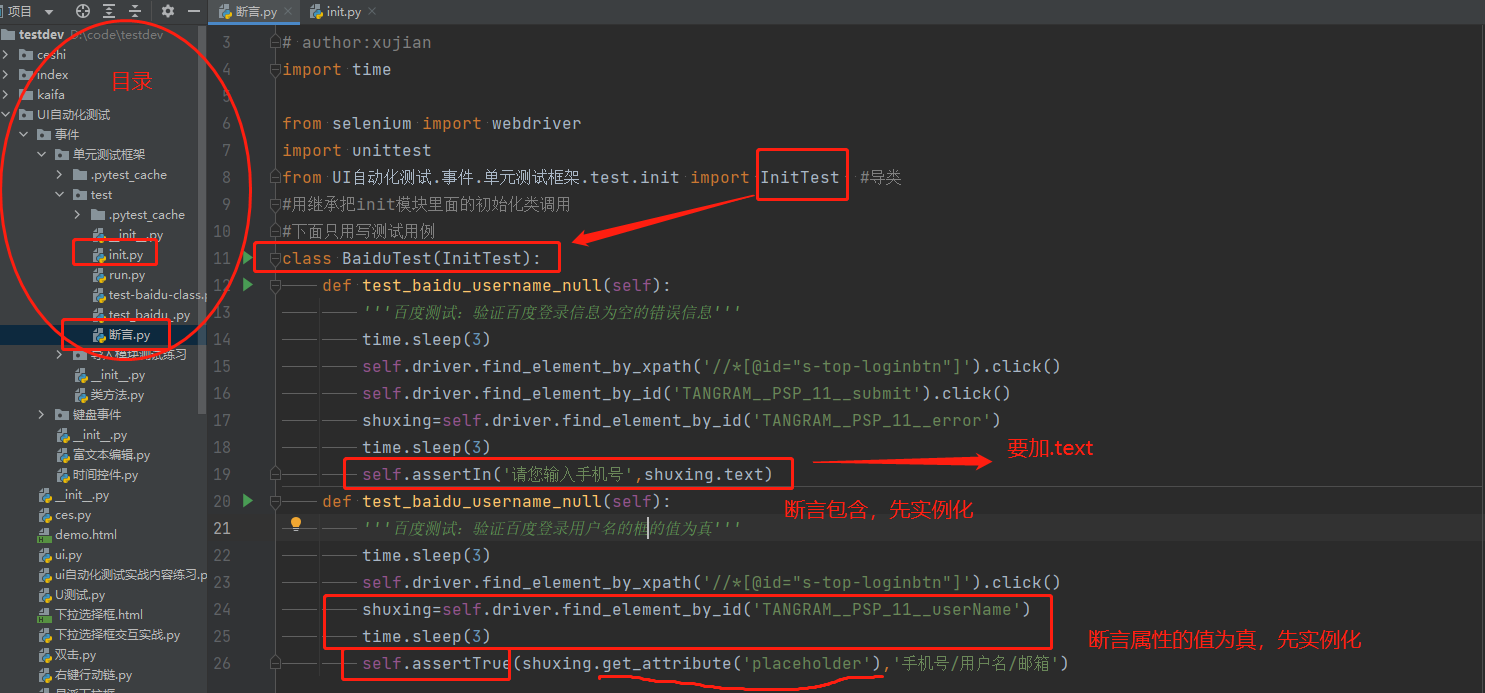
参数化
相同的测试步骤,不同的测试场景
我们以测试sina邮箱首页登录场景为例,我们需要测试账号密码为空的场景、邮箱格式错误的场景、账号密码不符的场景
unittest之参数化
在unittest的测试框架中,可以结合ddt的模块来达到参数化的应用,当然关于ddt库的应用在数据驱动
方面有很详 细的解释,这里就直接说另外的一个第三方的库parameterized,安装的命令为:
pip3 install parameterized安装成功后,实现 登录如下:
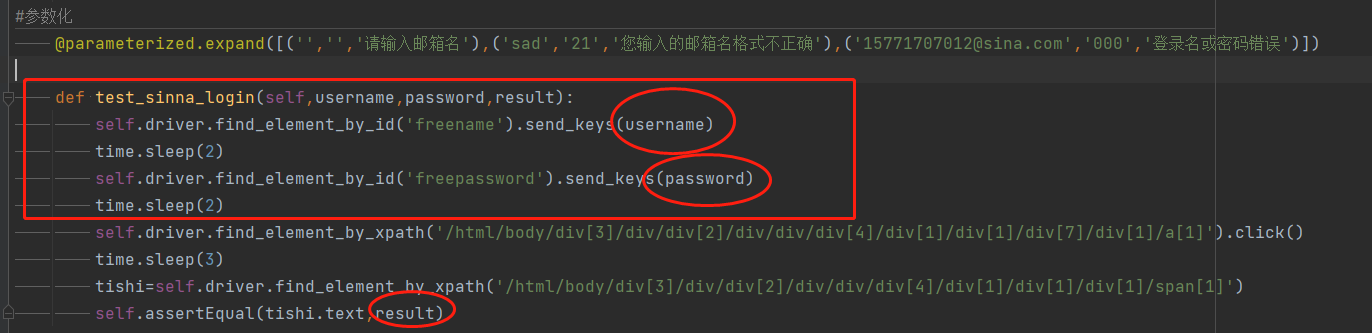
参数化代码

import time
from selenium import webdriver
import unittest
from parameterized import parameterized,param
'''
本质思想:把测试的数据看成列表当中的一个元素,
那么针对列表进行循环的时候,把每个元素进行赋值
'''
class sinalogin(unittest.TestCase):
def setUp(self) -> None:
self.driver=webdriver.Chrome()
self.driver.get('https://mail.sina.com.cn/')
self.driver.implicitly_wait(20)
def tearDown(self) -> None:
self.driver.close()
#参数化
@parameterized.expand([('','','请输入邮箱名'),('sad','21','您输入的邮箱名格式不正确'),('15771707012@sina.com','000','登录名或密码错误')])
def test_sinna_login(self,username,password,result):
self.driver.find_element_by_id('freename').send_keys(username)
time.sleep(2)
self.driver.find_element_by_id('freepassword').send_keys(password)
time.sleep(2)
self.driver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div/div[4]/div[1]/div[1]/div[7]/div[1]/a[1]').click() #点击登录
time.sleep(3)
tishi=self.driver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div/div[4]/div[1]/div[1]/div[1]/span[1]') #找到提示的信息
self.assertEqual(tishi.text,result) #断言提示信息文本和我参数化文本一致
if __name__ == '__main__':
unittest.main()
# #在 @paramiterized.expand() 中, 每个元组都被认为是一条测试用例。 元组中的数据为该条测试用例变化的值。在测试用例
# 中,通过参数来取每个元组中的数据。
# 参数化会自动多个加上 '0', '1', '2', '3' 来区分每条用例, 在元组中定义的 'case1', 'case2', 'case3', 'case4'
# 也会作为每条测试用例名称的后缀出现
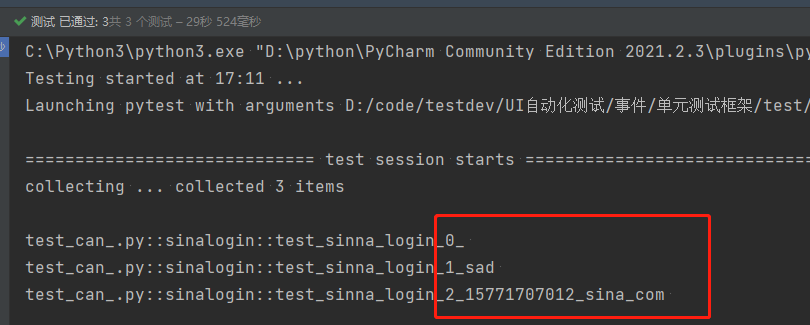
测试报告HTMLtestRunner
default默认 strftime() 格式化时间函数,time.strftime()
函数的作用是:根据区域设置格式化本地时间/日期。
os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口;sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
import os,time,unittest
from HTMLTestRunner import HTMLTestRunner #要使用 HTMLTestRunner 首先要导入模块
#获取所有测试文件,看做是个容器
def allTest():#
suite=unittest.TestLoader().discover(start_dir=os.path.dirname(__file__),pattern='test*.py')
return suite
def base_dir(): #获取上一级的目录
return os.path.dirname(os.path.dirname(__file__))
def runnnnnn():
#打开文件,把上级路径和report\report.html拼接,以wb二进制的方式写入。
#创测试报告的html文件,此时还是个空文件
fp=open(os.path.join(base_dir(),'report','report.html'),'wb')
#定义 HTMLTestRunner 测试报告,stream=定义报告所写入的文件;
runner=HTMLTestRunner(stream=fp,title='这是自动化测试报告标题',description='这是描述')
runner.run(allTest()) #运行测试容器中的用例,并将结果写入的报告中 #run是运行方法返回结果return result,
runnnnnn()
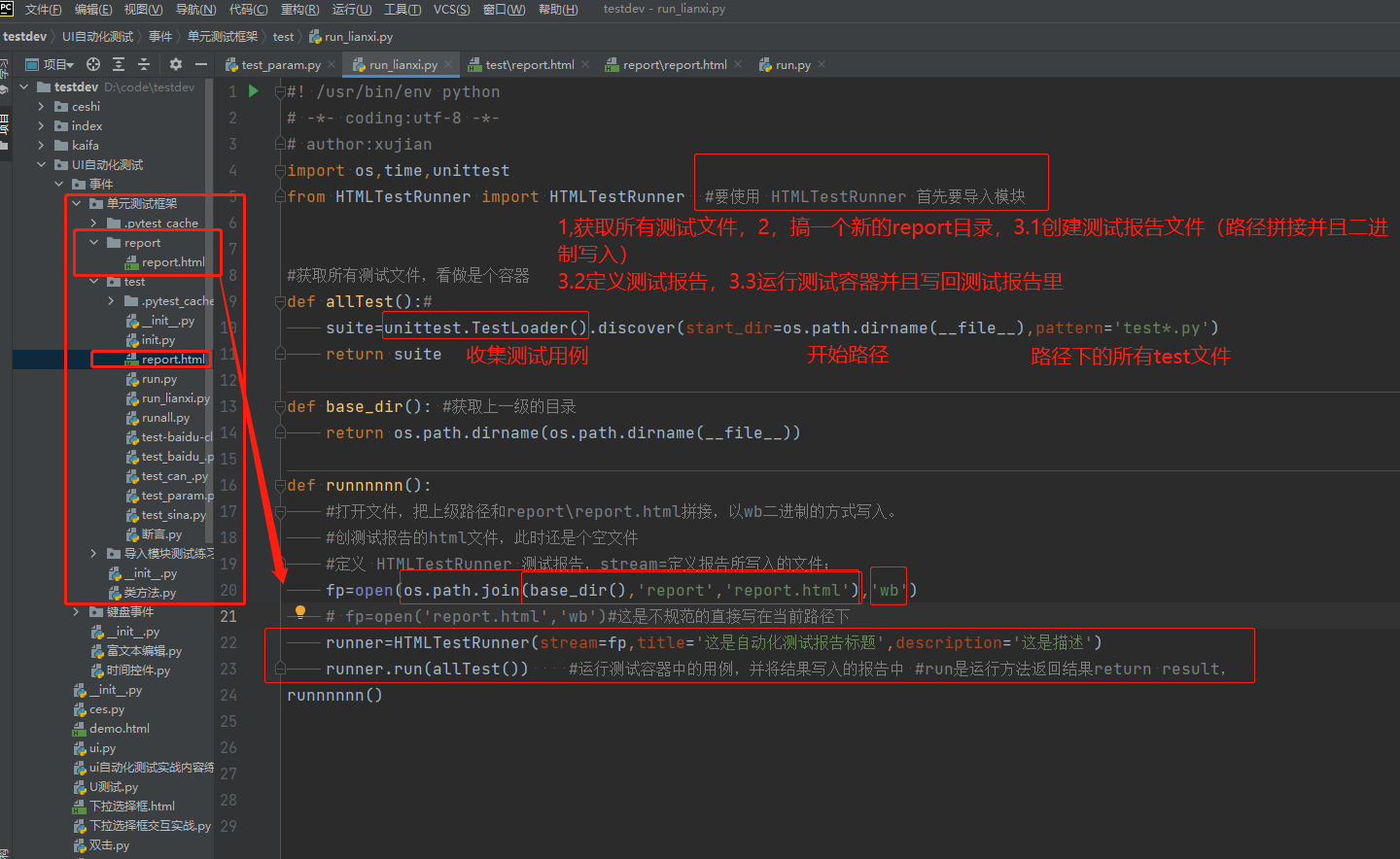
测试报告加入时间戳
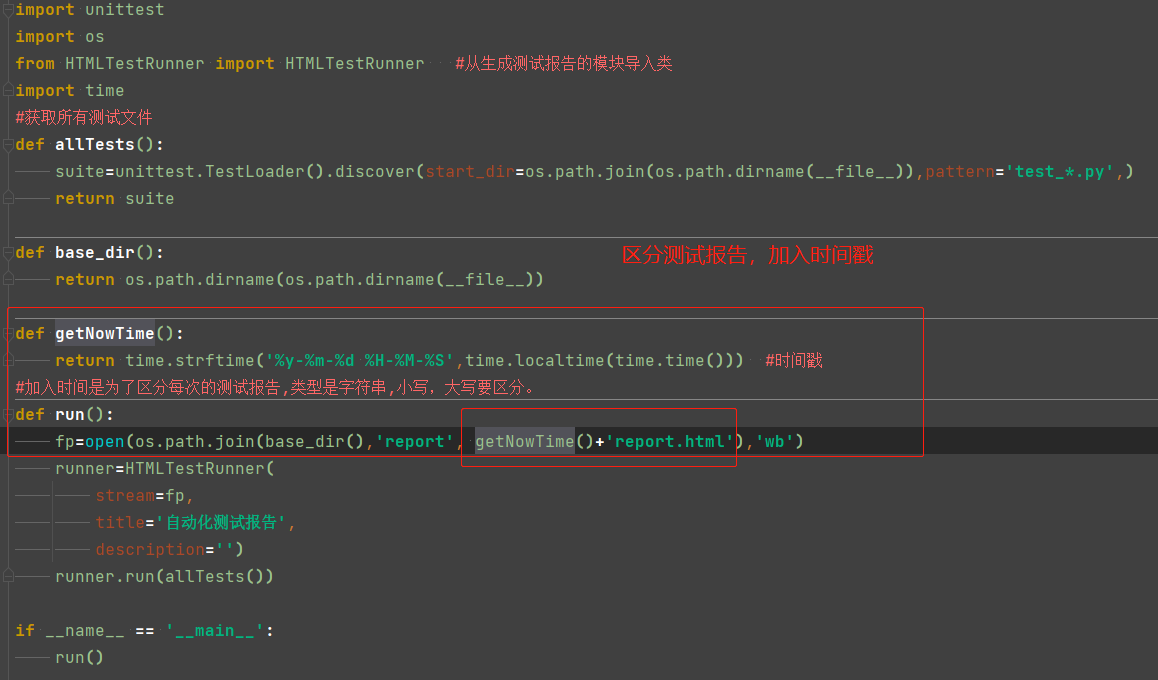
数据驱动
数据驱动的思想:在自动化测试过程中,把测试过程中使用到的数据单独的分离到文件中,这样统一来管理具体的测试数据。
先解释下为什么要使用数据驱动模式:
-
使脚本重复使用,一套数据用同一个脚本
-
数据和脚本分开达到 数据分离,可以让数据多处调用
json yaml csv excel mysql
初次接触自动化测试时,对数据驱动和关键字驱动不甚理解,觉得有点故弄玄须,不就是参数和函数嘛
json文件
json模块提供四个功能:dumps、dump、loads、load
dumps:将python中的字典转换为字符串。
这里的json和python中的字典相似,但是json作为文件进行保存或者在传输的过程中都是字符串的形式,这点与字典有很大的不同。所以这里将python中的字典转换成字符串,也就是将python的字典格式转换成json格式。
json文件:
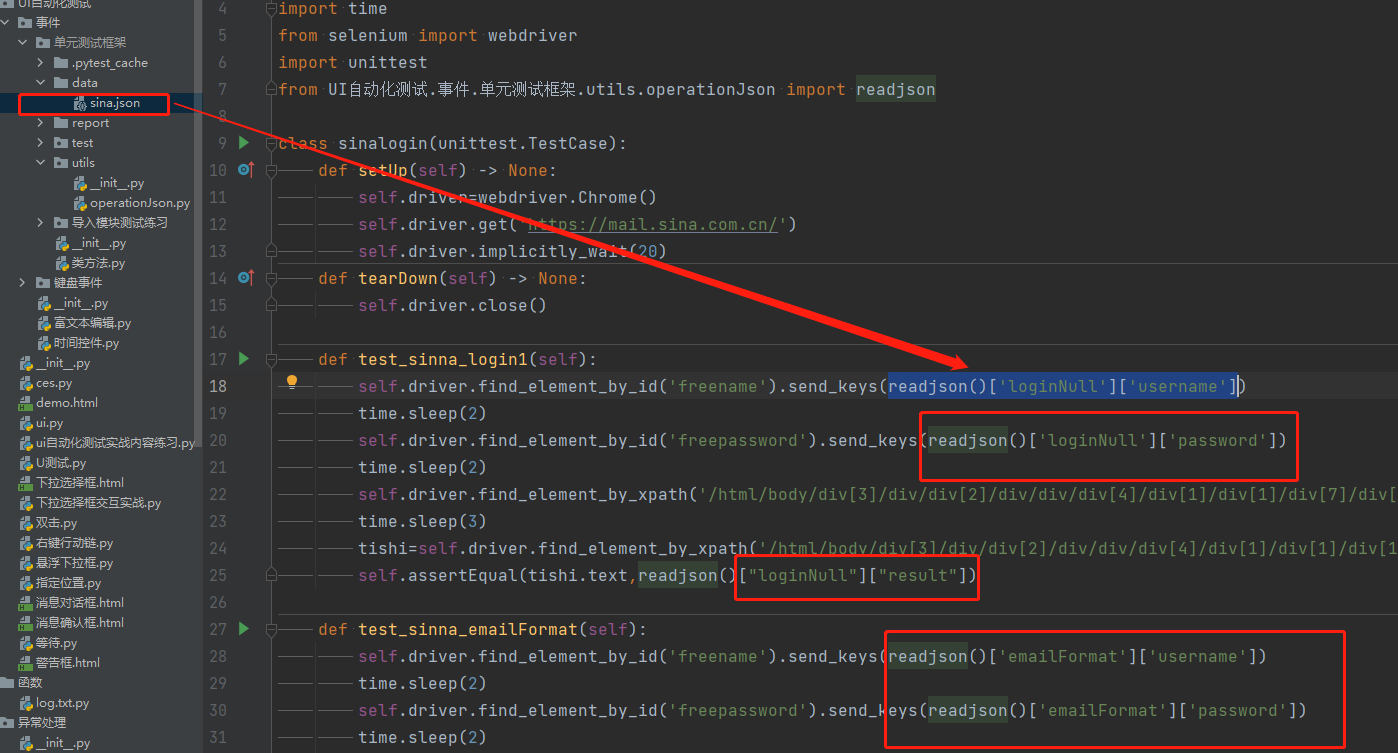
1 2 3 4 5 | { "loginNull": {"username": "","password": "","result": "请输入邮箱名"}, "emailFormat": {"username": "sadert","password": "asrtr","result": "您输入的邮箱名格式不正确"}, "loginError": {"username": "sdrtdt@sina.com","password": "aserty","result": "登录名或密码错误"}} |
json文件读取调用代码:
import json,os
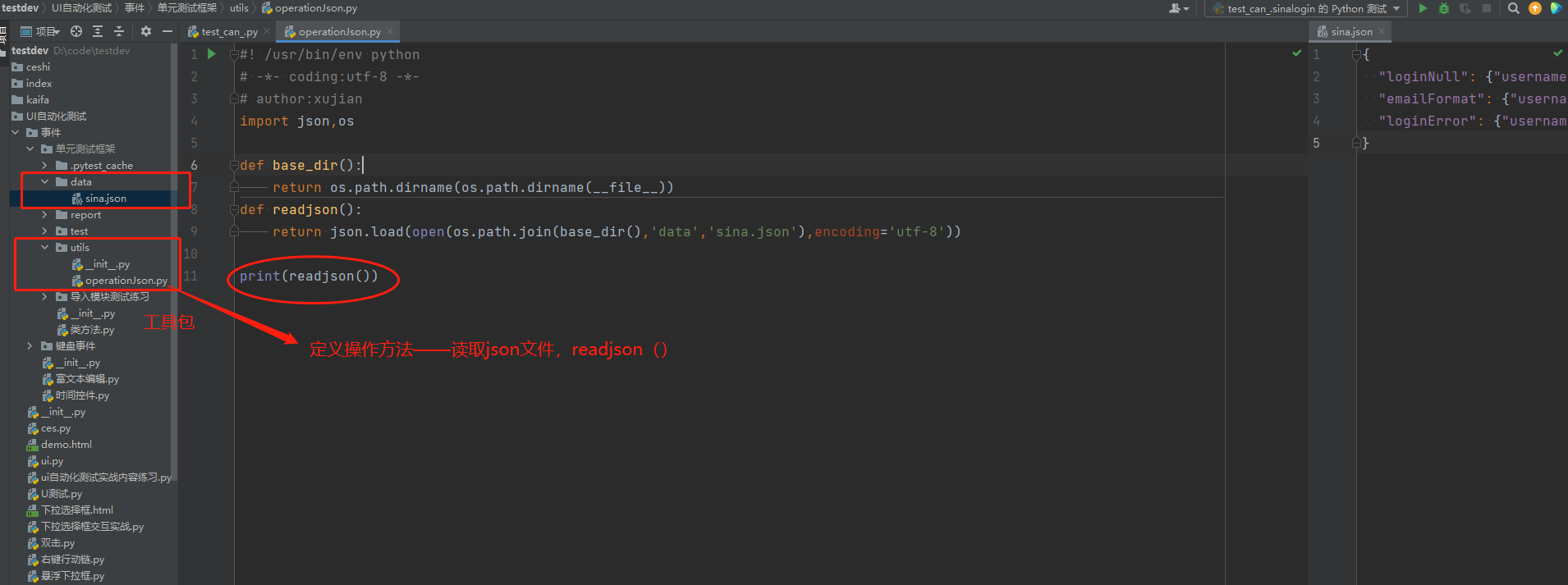
def base_dir():
return os.path.dirname(os.path.dirname(__file__))
def readjson():
return json.load(open(os.path.join(base_dir(),'data','sina.json'),encoding='utf-8')) # 拼接路径加读取json文件
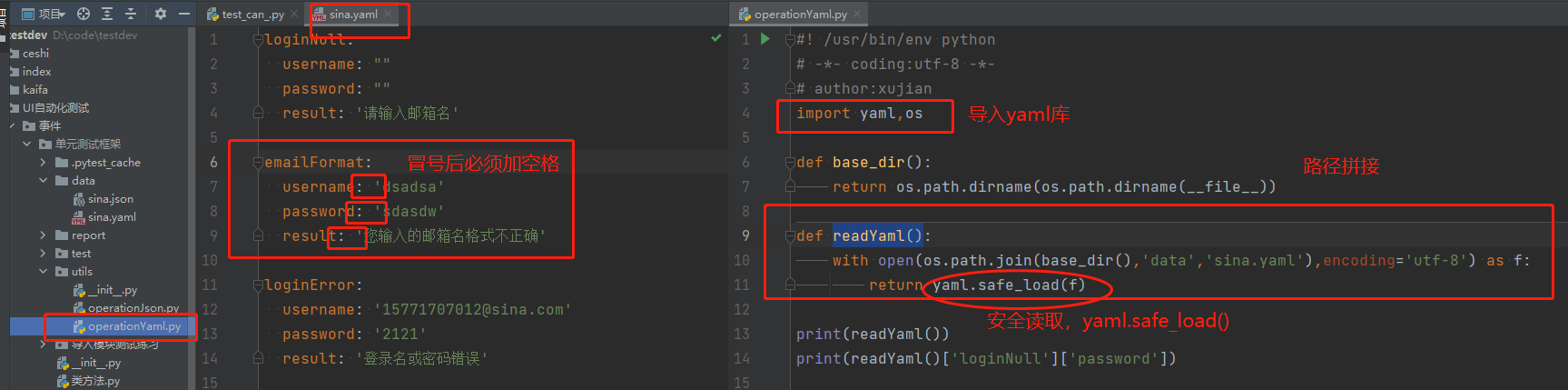
yaml文件
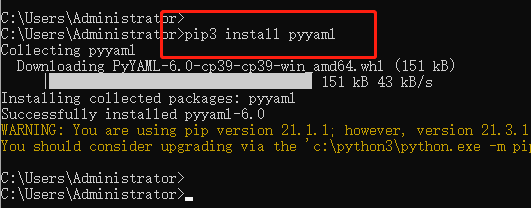
使用yaml.safe_load(),这个只解析基本的yaml标记,用来保证代码的安全性,不过这对于平常保存数据是足够了
创建yamal文件和操作包
编程免不了要写配置文件,怎么写配置也是一门学问。
YAML 是专门用来写配置文件的语言,非常简洁和强大,远比 JSON 格式方便
它的基本语法规则如下。
- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用Tab键,只允许使用空格。
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
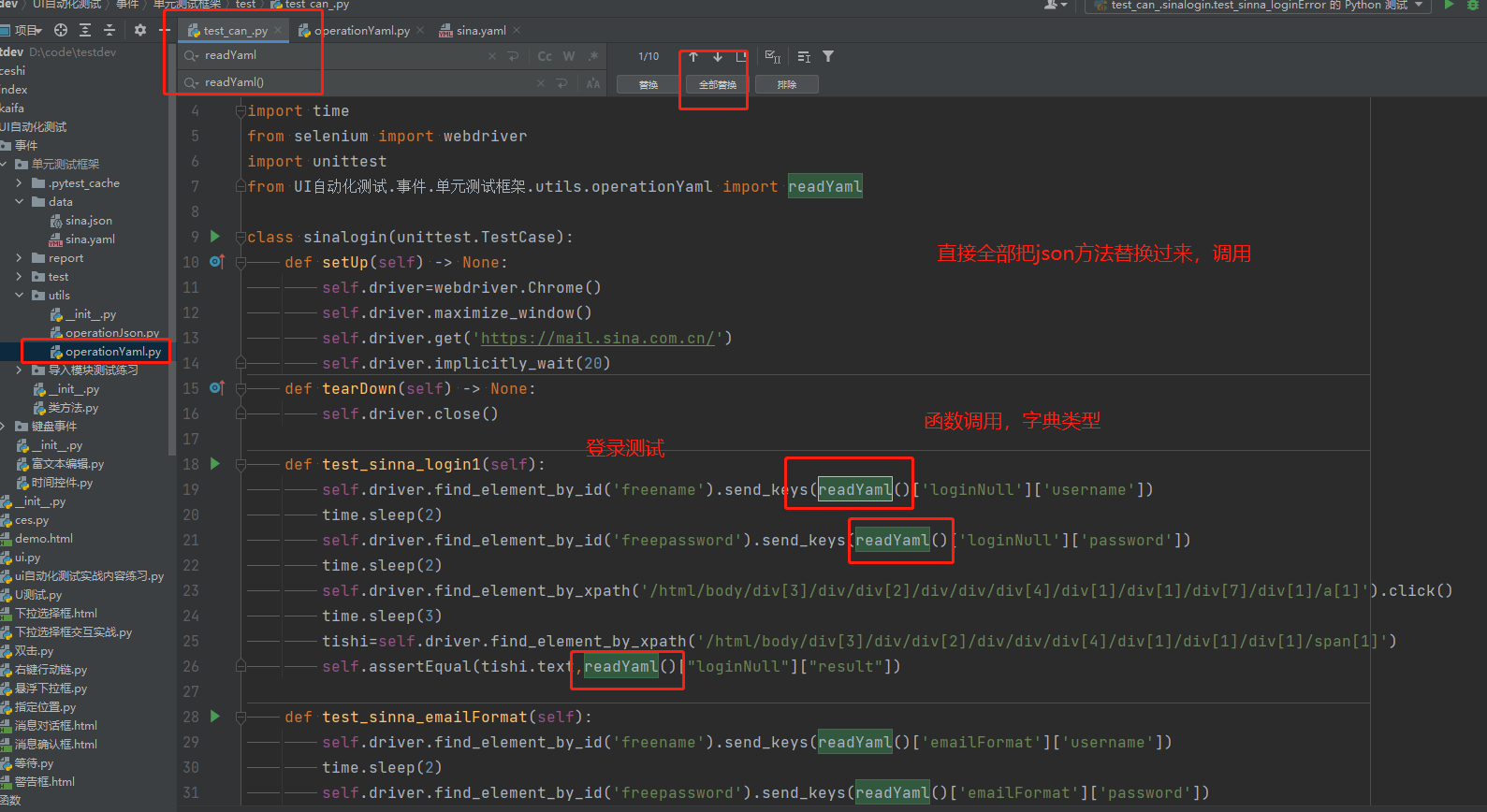
yaml文件和读取亚麻文件:
csv的文件
首先我们拿到的excel文件格式转化为csv文件:Excel->文件->另存为->csv文件,切记不可直接更改文件后缀格式
在Python中读取csv⽂件⾥⾯的使⽤直接使⽤标准库csv就可以的,在csv的库⾥⾯,读取⽂件的⽅式主要分为两种的⽅式,字典或者是列表的⽅式来读取数据。
注意: csv和excl的列表形式要跳过第一行(字典不用)csv的next()忽略第一行 excle的range()从1开始也忽略第一行
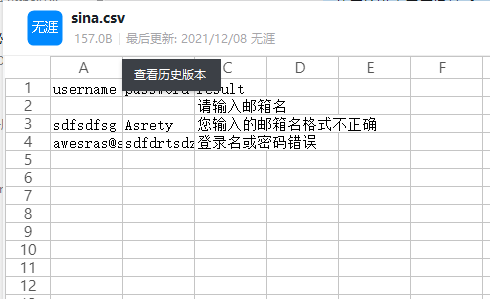
把文件直接复制到data下面
下面是csv文件

两种操作文件的函数
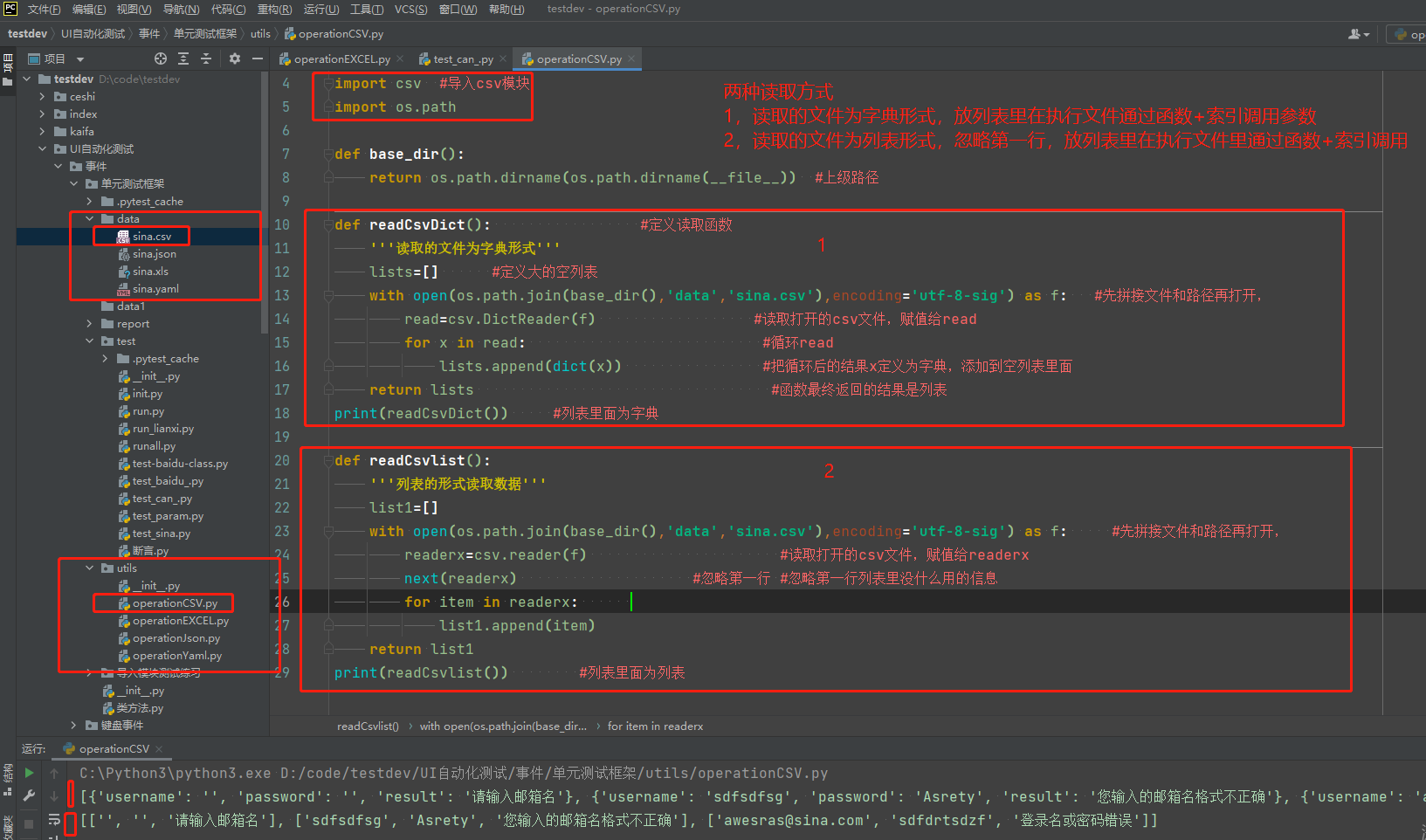
测试的原始文件
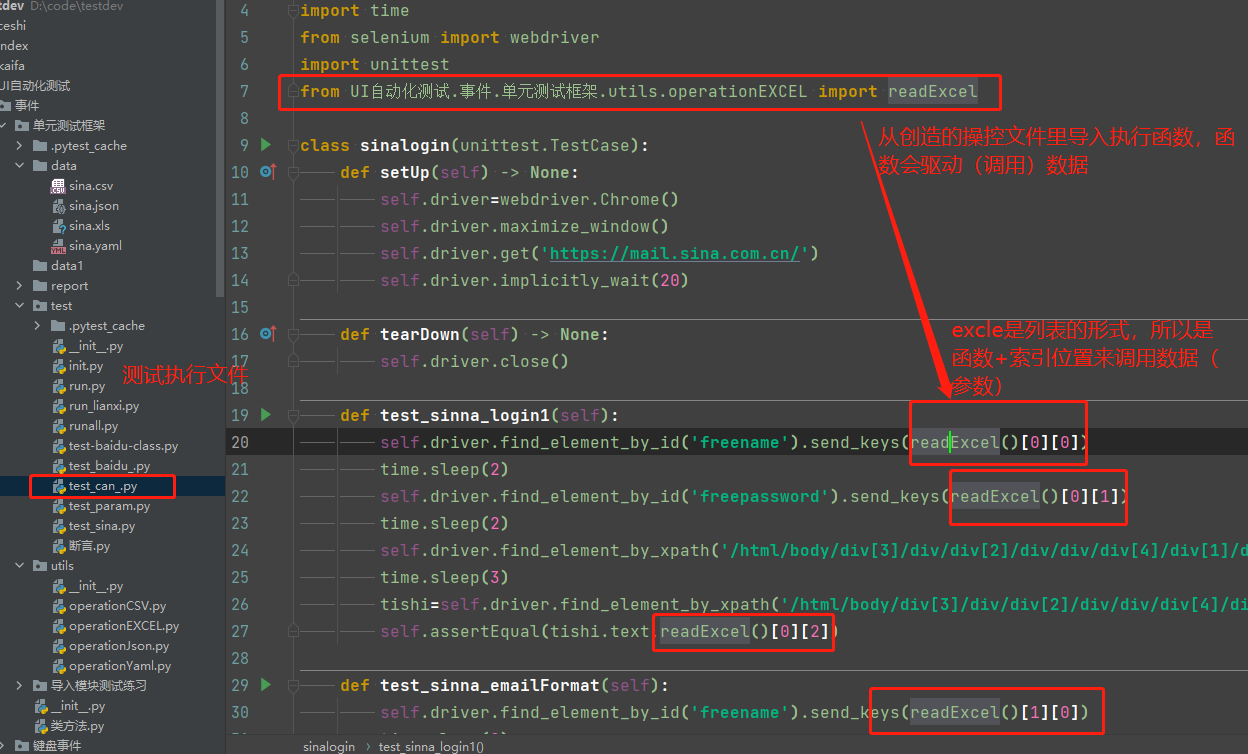
表格操作的函数
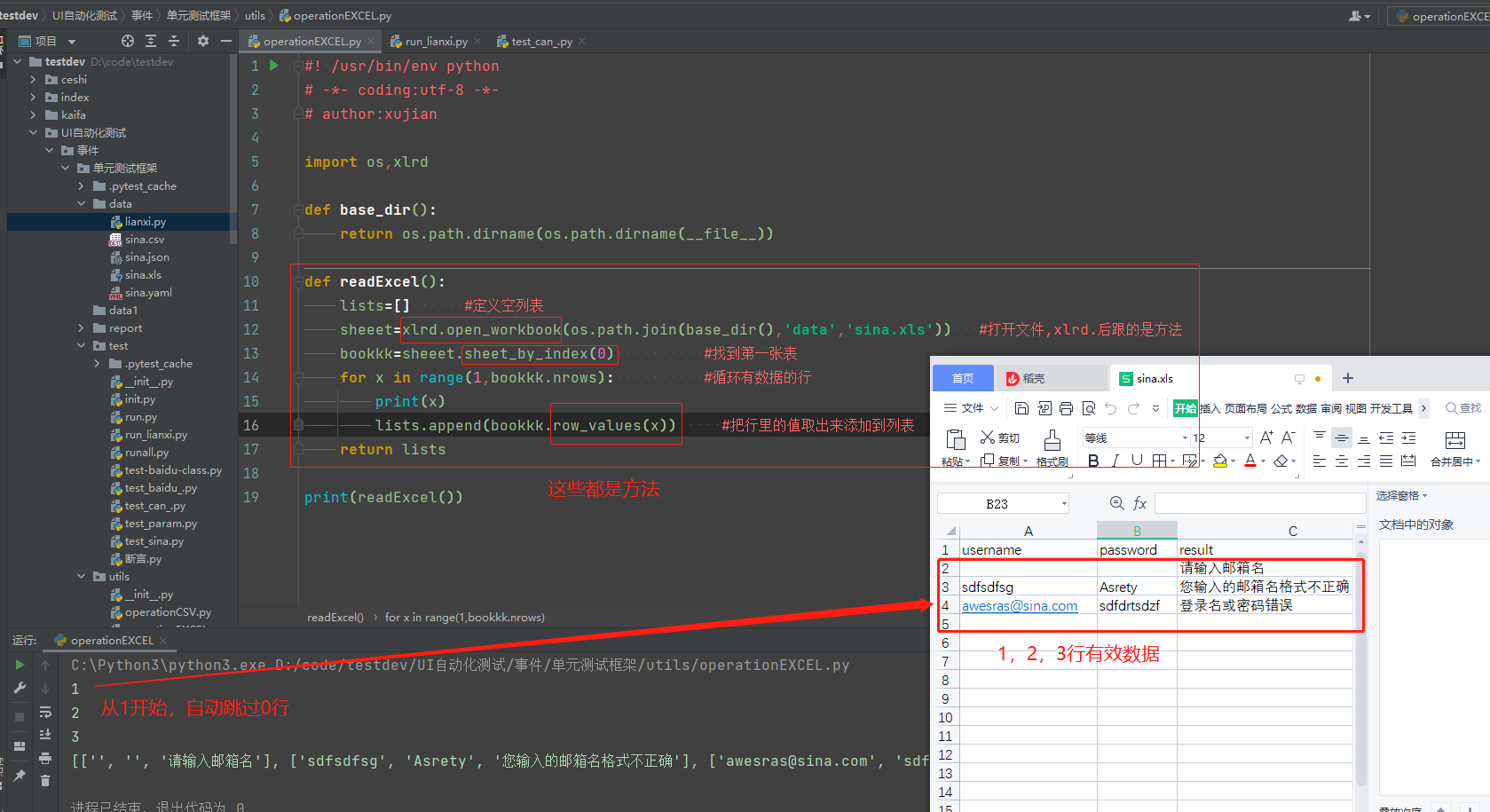
def readExcel():
lists=[] #定义空列表
sheeet=xlrd.open_workbook(os.path.join(base_dir(),'data','sina.xls')) #打开文件,xlrd.后跟的是方法
bookkk=sheeet.sheet_by_index(0) #找到第一张表
for x in range(1,bookkk.nrows): #循环有数据的行
lists.append(bookkk.row_values(x)) #把行里的值取出来添加到列表
return lists


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)