《spring cloud微服务实战》读书笔记
一、基础知识
1.使用微服务比单应用模式,需要增加的挑战:
1)运维的变复杂,需要自动化工具来支持
2)接口的管理,服务接口化、接口服务化,接口的管理和维护工作很重要
3)分布式带来的复杂性:网络延迟、分布式事务、异步消息等
2.微服务架构的九大特性:
1)服务组件化:解耦、可替换
2)按业务组织团队:每个APP都要独立的人(全栈)或团队,来开发和维护。这样业务的变动,才不会波及整个组织
3)做“产品”的态度:持续关注服务运作情况,并不断分析以帮助用户来改善业务功能
4)智能端点和哑管道:更粗粒度的通信协议,通常用http或者轻量级消息总线
5)去中心化治理:每个服务(APP)技术异构,可以针对业务场景选择适合的技术
6)去中心化管理数据:每个APP使用自己的数据库实例。这也导致了数据库一致性的问题,需要通过补偿机制达成最终结果一致
7)基础设施自动化:自动化测试、自动化部署
8)容错设计:监控和日志组件,保证xi系统稳定性
9)演进式设计:初期使用单应用APP,后面随着业务发展,拆出去多个APP,核心app保持不变
3.spring cloud就像电脑中的品牌机,虽然性能可能没有自己定制的“兼容机”好,但是好处是快速上手,稳定,便宜
4.SC(spring cloud)的版本号,是按ABC开头的单词命名的,后面跟各个版本的发布版本号。注意SC里面每个子项目的版本,要和SC的版本对应
二、 微服务构建:spring boot
1.starterPOMs:spring boot提供的一些列轻便依赖包,采用spring-boot-starter-*。开发者不需要再去关注复杂的依赖配置
2.在使用命令行方式启动Spring Boot时,连续两个减号--就是对application.properties中的属性值进行赋值的标识
3.spring boot有一套自己的配置加载顺序。可以很方便的在不同环境下使用多套配置
4.actuator的原生端点主要有三大类:
1)应用配置:帮助我们获取系统繁杂的配置内容,包括自动化配置报告(/conditions)、创建的所有bean(/beans)、系统配置属性(/configprops)、系统环境属性(/env)、控制器映射关系(/mappings,有点像swagger)、自定义信息(/info)
2)度量指标:帮助我们获取系统运行时的一些状态报告,包括各类度量指标(/metrics,也可以自定义指标参数)、健康指标信息(/health,可重写接口)、线程信息(/dump)、http跟踪信息(/trace)
3)操作控制:远程关闭应用(/shutdown,可重写接口)
三、服务治理spring cloud eureka
0.注册中心、服务提供者、服务消费者
1.eureka服务端,提供了完备的restful API来支持非java语言构建的微服务纳入体系
2.eureka服务端支持集群和故障恢复功能,不同区域的服务端是通过异步模式互相复制状态的,所以在同一时间点,不同服务注册中心状态会有细微差别
3.eureka客户端,主要负责服务注册与发现,周期性的发送心跳来更新服务租约,同时也把注册中心的服务信息缓存在本地
4.可以通过简单的配置,使单节点服务注册中心,变成集群,从单节点模式变成实现高可用模式
5.服务续约(Renew):服务提供者会维护一个心跳来告诉Eureka Server状态可用。服务续约的过期时间和发送间隔可以通过参数配置
6.注册的服务,进行正常的关闭操作时,会发送“下线”通知给注册中心
7.服务注册中的“自我保护”机制,在dev环境下,最好关闭,可以便于调试(实时发现服务)。但是生产环境最好开启,因为生产环境网络可能不稳定,所以要给注册的服务容错机制
8.eureka的几乎所有配置,都可以在配置文件里重新定义,包括ip,实例名,端口号,注册地址等
9.服务提供模块,可以通过修改配置,使与服务注册中心的“心跳”实现方式,通过模块的/health端点来实现。然后再根据自身的实际业务逻辑,自定义/health端点的状态判断
四、客户端负载均衡:spring cloud ribbon
1.通过ribbon实现负载均衡,只需要1.让服务提供者讲多个服务实例注册到注册中心;2.服务消费者直接调用被@LoadBalanced注解修饰过的RestTemplate来实现面向服务接口调用
2.ribbon默认实现默认实现了区域亲和策略,实现了跨区域的容错机制实现。
3.eureka实现服务治理机制,强调了CAP原理中的AP,即可用性与可靠性(弱化一致性)
4.eureka在连接失败的时候,有重试机制。减少了由于系统缺乏一致性,所带来的服务故障的问题。
五、服务容错保护:spring cloud hystrix
1.断路器,类似保险丝的功能,在微服务框架中,通过断路器的故障监控,像调用方返回一个错误响应,避免长时间等待。
2.Hystrix具有:服务降级、服务熔断、线程和信号隔离、请求缓存、请求合并以及服务监控等强大功能:
1)断路器:有一个“半开”状态,会定时请求当前状态,如果正常,会关闭断路器开关。
2)依赖隔离:仓壁模式
3)使用详解:同步/异步创建请求命令
4)服务降级:getFallback()方法,可以用来处理错误、超时、线程池拒接、断路器熔断等情况
5)异常处理:Hystrix可以忽略指定异常
6)命令名称:通过设定Hystrix命令名称,可以给命令分组,同时划分线程池。
7)请求缓存:可以通过注解,对提供的服务提供缓存
8)请求合并:可以通过注解设定合并接口,在高并发情况下,对服务请求进行合并。注意,请求合并本身也有开销,所以不是适用所有场景。
9)Hystrix有许多有用的属性注解,包括:Command属性、collapser属性、threadPool属性
10)Hystrix仪表盘:通过与actuator的整合,监控流量、成功数、超时数等信息
11)turbine:集群监控工具
12)与消息代理结合:trubine可以通过基于消息代理的收集实现
六、声明式服务调用:spring cloud feign
1.定义要暴露的服务接口:@FeignClient("xxx")
2.可以通过发布接口JAR包到maven仓库的方式,让服务消费者引入jar包来更方便的使用接口(前提是接口要稳定、向上兼容)
3.可以通过配置ribbon的参数,来实现超时、重试的配置
4.可以设置请求压缩,提高传输性能
5.可以为每个feign设置日志级别
七、API网关服务:Spring Cloud Zuul
1. 请求路由:路由转发
2.请求过滤:对请求过滤和拦截
3.本地跳转:实现forward的跳转
4.设置请求头:可以通过设置请求头,来解决安全验证、cookie、重定向等问题
5.可以通过网关的动态路由设置,来避免因修改路由而引起的服务挂起
6.可以通过动态过滤器加载,来保证服务的持续服务能力
八、分布式配置中心:Spring Cloud Config
1.获取配置URL:服务IP+端口/{应用名}/{环境名(dev)}/{分支名},其它方法方式:

2.配置中心server,可以配置多套环境的GIT仓库。还可以通过通配符的表达式,来实现复杂的配置需求。
3.可以使用{application}、{profile}、{laber}这些占位符,来配置URI
4.可以通过设置子目录的方式,来为一个应用配置一个目录:spring.cloud.config.server.git.searchPaths={application}
5.可以通过actuator的端点接口(refresh),重新获取和刷新配置。
九、 消息总线:spring cloud bus
1.消息总线的功能:广播消息
2.spring cloud config可以整合spring cloud bus,通过简单的配置,就能实现发送请求,动态刷新配置的功能
3.也可以通过和kafka整合,达到同样的效果
4.spring cloud bus,是使用了spring cloud stream构架的上层应用。如果要使用其它消息中间件,可以实现一套指定消息代理的绑定器即可
十、消息驱动的微服务:spring cloud stream
1.核心概念:
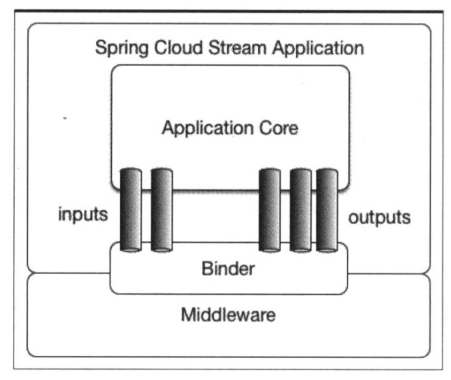
2.绑定器(Binder):用于连接消息中间件和业务逻辑的一个中间层。
3.topic主题:发布共享消息给消费者的地方。RabbitMQ中对应的是Exchange,Kafka中对应topic。
4.channel:消息通道
5.发布-订阅模式:当一条消息被投递到消息中间件之后,它会通过共享的topic主题进行广播,消息消费者在订阅的主题中收到它
6.消费组:针对多实例的情况,把不同实例的服务,设定为一个组,只消费消息一次
7.消息分区:消息的特征ID,用来保证同类的消息,能被发送到一个特定的实例上实现累计统计的效果
8.spring cloud stream 整合了 spring bott 和 spring integration(消息框架)
十一、分布式服务跟踪spring cloud sleuth
1.实现跟踪:主要通过traceId+spanId
2.跟踪原理:
1)traceId:唯一标识
2)spanId:记录开始、结束时间和状态
3)请求header中增加的跟踪信息:
-
- X-B3-TraceId:一条链路的唯一标识,必填
- X-B3-SpanId:一个工作单元的唯一标识,必填
- X-B3-ParentSpanId:上一个工作单元,root span的该值为空
- X-B3-Sampled:是否被抽样输出的标志,1表示需要被输出,0表示不需要被输出
- X-Span-Name:工作单元的名称
4)抽样收集:通过设定抽样收集策略,可以指定收集的百分比,也可以针对特定的业务场景收集
5)与logstash整合:ELK平台(三个开源工具组合)
6)与zipkin整合:监控与时间消耗相关的需求。可以查某个时间段内用户请求的处理时间
7)http收集:可以根据zipkin的WEB页面,查看各类监控信息
8)消息中间件收集:通过加入spring cloud stream,可以时间通过消息中间件收集跟踪信息
9)收集原理:
-
- 数据模型:span、trace、annotation(cs、sr、ss、cr)、binary annotation
- 收集机制:每个系统实例,合并span后发送
10)数据存储:默认提供支持mysql
11)API接口:zipkin的UI模块也是基于它的restFul API开发的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号