
《Elasticsearch实战》读书笔记
遗留问题:
1._source字段和field字段的区别
2.q和search的区别(查询请求中)
3.输入关键字的大小写,参考prefix查询,match_phrase_prefix查询(4.4.2),有些查询不会被分析,所以区分大小写
第一章:ES介绍
1..快速查询:
1)Lucene使用倒排索引,创建一个数据结构,记录每个单词出现在哪些数据中的清单
2)为了提升搜索的性能和相关性,需要更多的磁盘空间来储存索引。增加新内容会越来越慢,因为每次添加数据就要更新索引。所以ES需要调优。
2.相关性:
1)词频、逆文档词频。
2)ES提供了很多内置功能来计算相关性得分,可以定制化,如:更新时间、出现位置、精确模糊
3.精确匹配:
1)处理错误的拼写
2)支持变体
3)使用统计信息
4)给予自动提示
4.ES的用法:当做独立的数据库、当做中间件(搜索)、当做工具(ELK)
第二章:深入功能
1.ES的逻辑结构:索引->类型->文档(数据库->数据表->行数据)
2.文档:
1)ES的最小单位
2)json
3)灵活的结构,层次
4)文档的字段可以随意增减,但是字段类型及其设置,需要保存
3.类型
1)映射:每个类型中字段的定义
2)映射包含某个类型中当前索引的所有文档的所有字段定义。但不是所有的文档必须要有所有的字段定义
3)如果有新文档带来了新的未定义的字段,ES可以自动猜测它,但不一定准,所以最好手动预先定义好
4.索引
1)索引是(映射)类型的容器,包含所有字段定义和其它设置,如refresh_interval索引更新间隔(ES被称为是准实时的,就是指这种刷新过程)
2)ES可以跨索引或类型搜索
5.分片:
1)一个分片是一个目录中的文件,Lucene用这些文件储存索引
2)一份分片是一个Lucene的索引。多个分片,组合成一个ES的索引
3)副本分片是主分片的完整备份,用于搜索或者主分片丢失后成为新分片
4)分片下包含:词条(倒排索引)、文档(ID)、词频(用于相关性计算)
7.节点、集群:
1)一个节点是一个ES的实例,在服务器上启动ES之后,就拥有了一个节点(一个进程)。在一个服务器上启动多个进程,可以开多个节点
2)多个节点可以加入一个集群(默认设置)。节点的分片在不同节点有副本分片。所以任何一个节点都可以宕机。
3)集群的缺点,对于节点间的通信要快、稳。
8.水平扩展和垂直扩展
1)水平扩展:通过集群,增加更多的节点
2)垂直扩展:在同一个节点上,增加硬件条件(CPU、内存)
9.关于搜索:
1)可以设置超时时间,对于大批量的数据,只会返回超时前所收集的结果
2)会返回搜索相关的分片,成功失败信息
3)可以用使用过滤器来查询结果,这样结果不会根据得分来排序
4)可以通过聚集,来搜索结果,类似SQL里的group by 和 count
5)可以通过ID,精确获取文档
第3章:索引、更新和删除数据
1.ES三种类型的字段:
1)核心:字符串,数值型,日期,布尔
2)数组和多元字段:如tags字段可以储存多个标签
3)预定义:_ttl(time to live)和_timestamp,_all(所有字段)
2.字段设置:
1)index:analyzed(默认)、not_analyzed(不分析词条:小写+拆分词条)、no(不索引,不会被搜索)
2)所有核心类型都支持数组,无需修改映射,既可以使用但一值,也可以使用数组。也可以使用多字段(fields),针对每个下级字段进行设置
3)预定义字段:
1._source:原始json文档
2._all:有所的字段一起索引
3.唯一识别文档:_uid,_id,_type,_index
4.其它:_size(原始文档内容大小)、_routing(路由到哪些分片)。其它还有很多
3.关于储存和搜索文档
1)ES默认储存文档并放在_source字段里。也可以设置值存某些字段的数据(store字段设置)
2)_source字段只是ES里的概念,对Lucene来说,和别的字段没有区别
3)_all是索引所有的信息(_source是储存所有信息,注意区别),当搜索不指定特定字段时,会从它里面搜索。字段也可以设置不保存在_all字段中。
4)ES内部有一个_uid,_id和_type组成它,是ES里文档的唯一标识。一般不可见,常用_id和_type
5)文档字段中的_index(索引)默认是无法搜索它的(需要显示指定哪个index搜索)。_index字段在聚集(第7章)上有其价值
4.可以通过指定Groovy语法的脚本来更新文档(直接写语句):变量赋值,线程等待
5.关于更新时的版本控制:冲突时可以设置自动重试,更新时可以指定版本号,也可以使用外部版本号来同步到ES的版本号(需要设置参数)
6.可以按照类型去删除数据,也可以通过查询来删除文档(2种URL请求格式)
7.关闭索引:有些业务场景, 需要保留业务数据(如日志),可以选择关闭索引而不是删除它。这样可以大大降低ES的性能消耗,也可以保留数据
第四章:搜索数据
1.确定搜索范围:以符号分割的方式来命名索引,可以通过别名的方式来一次搜索所有相关的索引(通配符?)
2.搜索请求中,可以设置通配符,可以设置要返回和不要返回的字条
3.关于排序,可以选择按字段排序或者按得分排序,也可以2者结合一起用。避免在多值(数组)和分析字段上排序,结果不可预期
4.搜索结果返回的内容详见4.1.4小节
5.查询和过滤器:后者没有打分+有缓存,可以提升效率
6.查询:
1)match_all:使用过滤器的时候,或者查询所有文档的时候用
2)query_string:查询输入框,可以支持强大的Lucene语法
3)term:词条
4)terms:多个词条,可以指定匹配的最小数量
5)match和phrase:可以查询有间隔的词组(分词?),将slop设为非1或者2
6)multi_match:查询多个匹配字段
PS.match查询是核心的查询类型
7.组合查询-bool查询(过滤器):可以实现必须、非必须、包含、非包含的逻辑
8.range查询:范围查询,因为不是二元匹配的,为了获得更好的性能,最好用在过滤器而不是查询中
9.wildcard查询:模糊匹配,性能压力更大,慎用。另一个类似的查询regexp查询,见第6章。
{ "wildcard" : { "assistantBook.name" : { "wildcard" : "*汤试题搜索验证书一*", "boost" : 1.0 } } }
注意:上面代码,会自动使用分词来查找,如果系统没做过分词,上面代码会搜不到任何结果(只能在单个字的时候,搜到)
"wildcard" : { "assistantBook.name.keyword" : { "wildcard" : "*汤试题搜索验证书*", "boost" : 1.0 } }
解决方法:我们在使用wildcard模糊查询的时候如果不想对字段内容进行分词查询的话,可以将内容变成keyword模式去查询,这样我们进行查询的时候就不会进行分词查询了
10.exsits和missing过滤器:查询相关字段是否存在
11.可以将query_string作为过滤器条件去设置,这样可以优化和缓冲此类查询(日志耗时告警?)
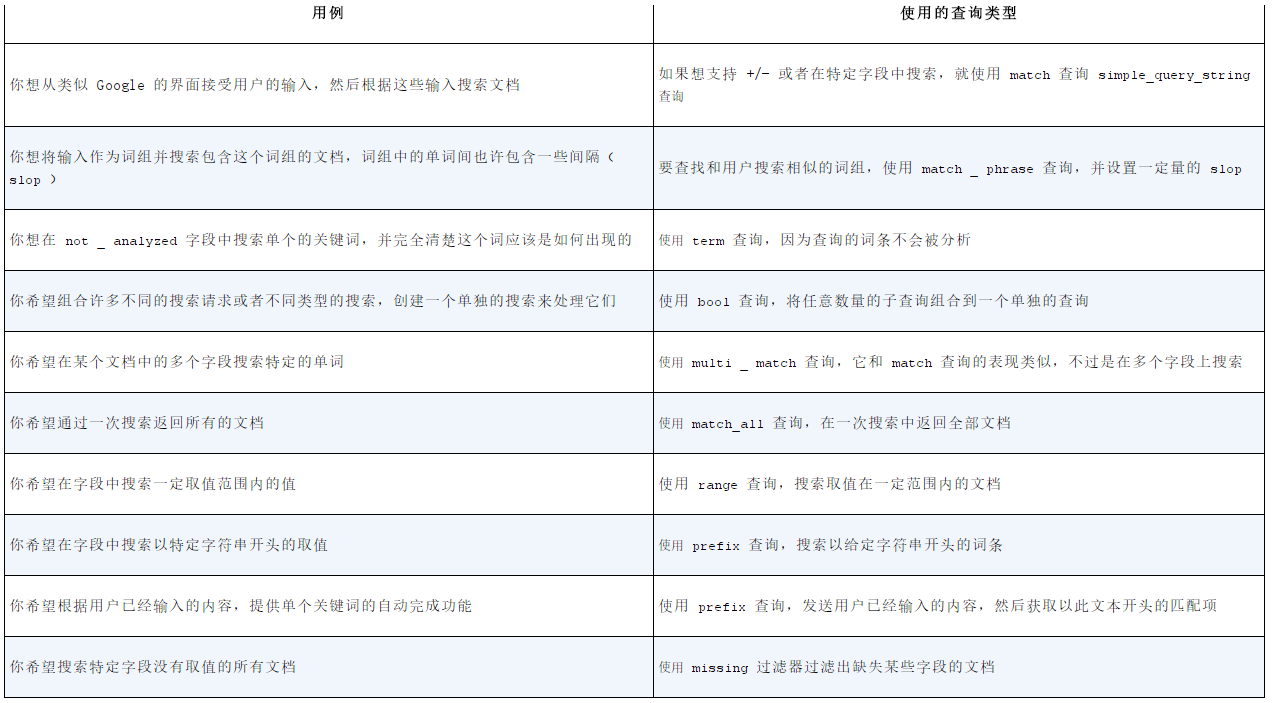
12.查询使用场景总结:
第五章:分析数据
1.分析处理步骤:
1)字符过滤——使用字符过滤器转变字符
2)文本切分为分词——将文本切分为单个或多个分词
3)分词过滤——使用分词过滤器转变每个分词
4)分词索引——将这些分词储存到索引中
2.在搜索的时候,可以对搜索的文本进行“分析”。注意,match\match_phrase会分析,而term\terms则不会。
3.针对同一个内容进行索引多次的时候,可以使用fileds(多字段类型)来储存分析方式不同的文本
4.可以使用API来测试分析的过程
5.一个分析器包括一个可选的字符过滤器、一个单个分词器、0个或多个分词过滤器
6.可以使用字典等多种方式来来提取词干(多种分词过滤器)
第六章:使用相关性进行搜索
1. TF-IDF:词频-逆文档频率。一篇文章中的词频越高,出现在多文档中的次数越小,相关得分越高
2.boosting,可以在索引文档,或者查询(推荐)的时候设置
3.可以通过explain参数(接口),来查询分析检索的结果,包括为什么不匹配,得分的解释
4.可以使用rescore(再打分)的方式,来优化打分效率,只针对前几页的返回结果打分排序(缩小查询范围)
5. 6.6章继续...
第八章:文档间的关系
1.对象类型:最快、最便捷的方法,但是没法保证内部文档之间的边界(因为每个对象的字段都被拍平储存)。所以会查询出期望之外的结果。在储存数据包含多个相似内容的时候(一堆数组的对象)。
2.嵌套类型(nested):将多个对象所以到多个分隔的文档,达到隔离的效果。但是可能会降低性能和并发性(因为每次更改都要索引整篇文档),这取决于文档多大,以及操作的频繁程度。
3.父子关系:将文档放在不同的类型,并在每种类型的映射中定义它们之间的关系
4.反规范化:将数据进行复制,达到多对多的关系
5.应用端的连接:将数据单独储存,在分组中指包含它们的ID。
6.使用方式:
1)对象映射:一对一关系
2)嵌套文档和父子结构:一对多关系
3)反规范化和应用端的连接:多对多关系
其它:
附录C——高亮功能:
1.可以设置no_match_size字段,来让没有命中的情况也返回字段内容
2.其它高亮选项:
1)调整碎片的大小和数量
2)修改高亮标签和编码
3)为高亮指定不同的查询,而不是原来的主查询
3.高亮器的实现方式:
1)简单型(plain)
2)后高亮器(Posting Hignlignter)
3)快速向量高亮器(Fast Vector Highlighter)
资料:
1.获取所有分片列表:10.0.11.135:9200/_cat/shards?v
2.获取映射列表:url/索引名称/_mapping/
3.获取映射:url/索引名称/_mapping/[具体的映射]
4.获取某个文档:url/索引/类型/文档ID
5.获取某个文档的字段:url/索引/类型/文档ID?fields=字段名1,字段名2
6.定义新的映射:参见3.1.1 .2
7.更新文档:url/索引/类型/文档ID/_update。可以使用upsert字段来设置当文档不存在时的内容。
8.删除文档:(delete请求)url/索引/类型/文档ID。删除操作也有版本号的控制。删除操作默认会缓存60秒,防止因已经删除的文档被立刻更新而创建
9.删除类型:(delete请求)url/索引/类型
10.查询并删除:(delete请求)url/索引/_query?q=关键字
11.搜索相关:
12.curl 'localhost: 9200/ get- together/_ search? from= 10& size= 10' ←--- 请求 匹配 了 所有 文档, URL 中 发送 了 from 和 size 参数
13.
配置:
1.elasticsearch.yml:ES的主要配置
2.logging.yml:日志配置
3.elasticsearch.in.sh:内存设置,JVM配置。ES的内存建议设置为可用内存的一半
4.ES的类型,是ES的一个逻辑概念,不属于Lucene。因此,不同类型的,同名字段应该设置为同一类型。 否则,ES无法识别。
5.

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步