
个人项目9/12(二)
| 软件工程 | 计科22级12班 |
|---|---|
| 作业要求 | 第二次作业要求 |
| 作业目标 | 通过全流程项目实践,了解软件开发过程中 需要具备的方式与良好的软件功能必须的测试过程 |
项目地址 github-xuicst
一、项目要求
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位。
二、项目开发记录
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 50 |
| Estimate | 估计这个任务需要多少时间 | 1460 | 1290 |
| Development | 开发 | 600 | 540 |
| Analysis | 需求分析 (包括学习新技术) | 40 | 35 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 (和同事审核设计文档) | 50 | 45 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范 | 30 | 20 |
| Design | 具体设计 | 80 | 70 |
| Coding | 具体编码 | 200 | 160 |
| Code Review | 代码复审 | 80 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 80 |
| Reporting | 报告 | 60 | 60 |
| Test Report | 测试报告 | 60 | 40 |
| Size Measurement | 计算工作量 | 20 | 20 |
| Postmortem & Process Improvement Plan |
事后总结, 并提出过程改进计划 | 40 | 50 |
| 合计 | 1460 | 1290 | |
三、算法代码模块
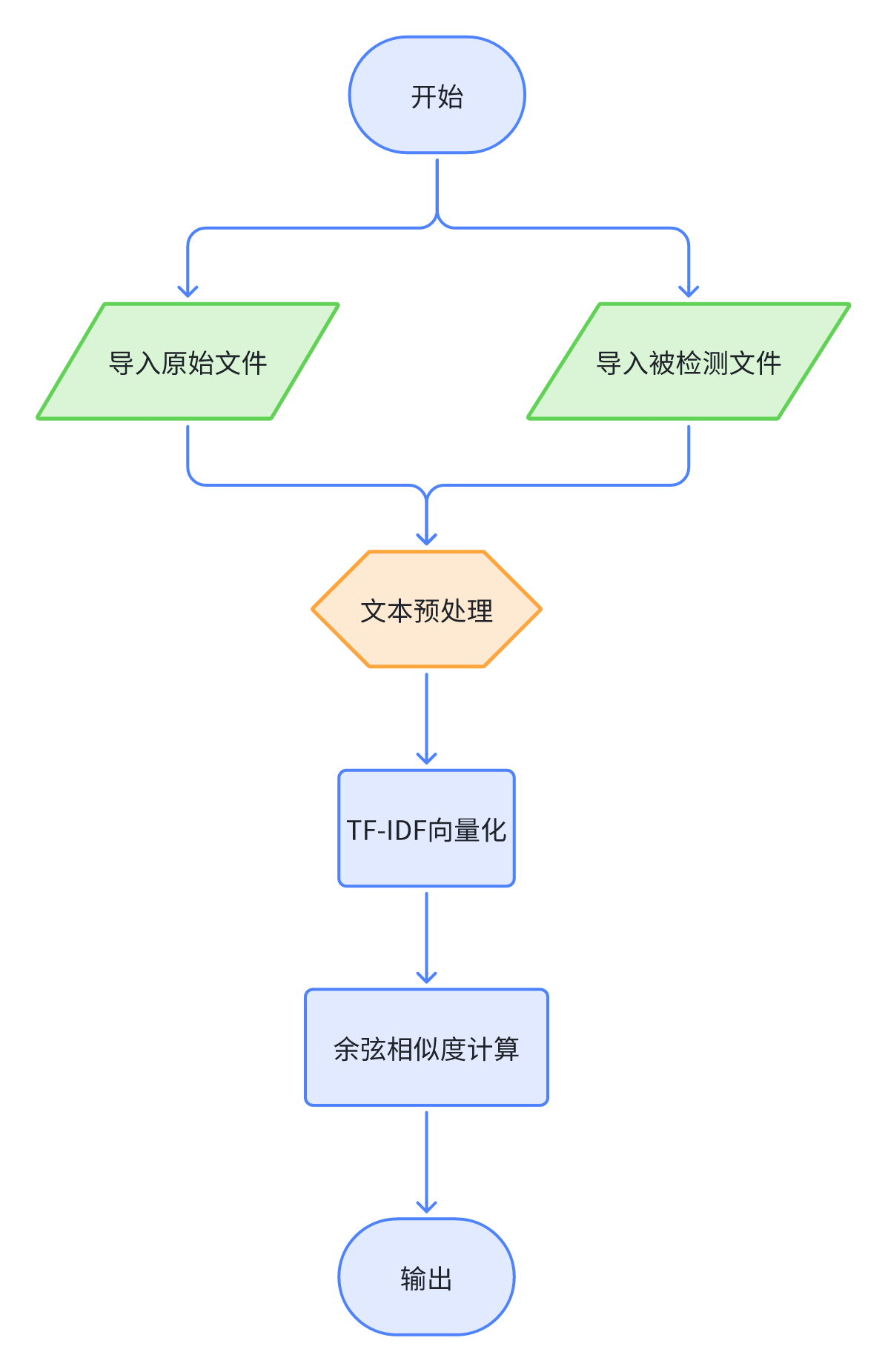
在开始设计的思路,本查重项目为论文查重,故文件信息量不算很大。查重过程中为找出于原始样本文件相似,即内容上,语句表述上具有极强的相似程度。因此,采用以词为单位,.txt的文件类型。
本项目采用 Term Frequency-Inverse Document Frequency(TF-IDF)的文本处理方式,统计单个词在文章出现频率 \(\text{TF}(t) = \frac{\text{词} t \text{在文档中出现的次数}}{\text{文档中总词数}}\)。将提取出的值进行向量化后,计算两个文本间的相似度,通过 sklearn.metrics.pairwise 库调用cosine_similarity((X: Any, Y: Any)模块,也就是使用 Cosine Similarity 余弦相似度进行处理,也就是 \(\text{Cosine Similarity} = \frac{A \cdot B}{||A|| \cdot ||B||}\)。
整体流程图如下:
四、运行结果与代码检测
-
环境:
Windows 11
PyCharm 2024.2.1 (Community Edition)
Memory: 2008M
Cores: 16
scikit-learn~=1.4.1.post1
jieba~=0.42.1 -
代码检测:
Qodana
界面如下:
五、计算性能
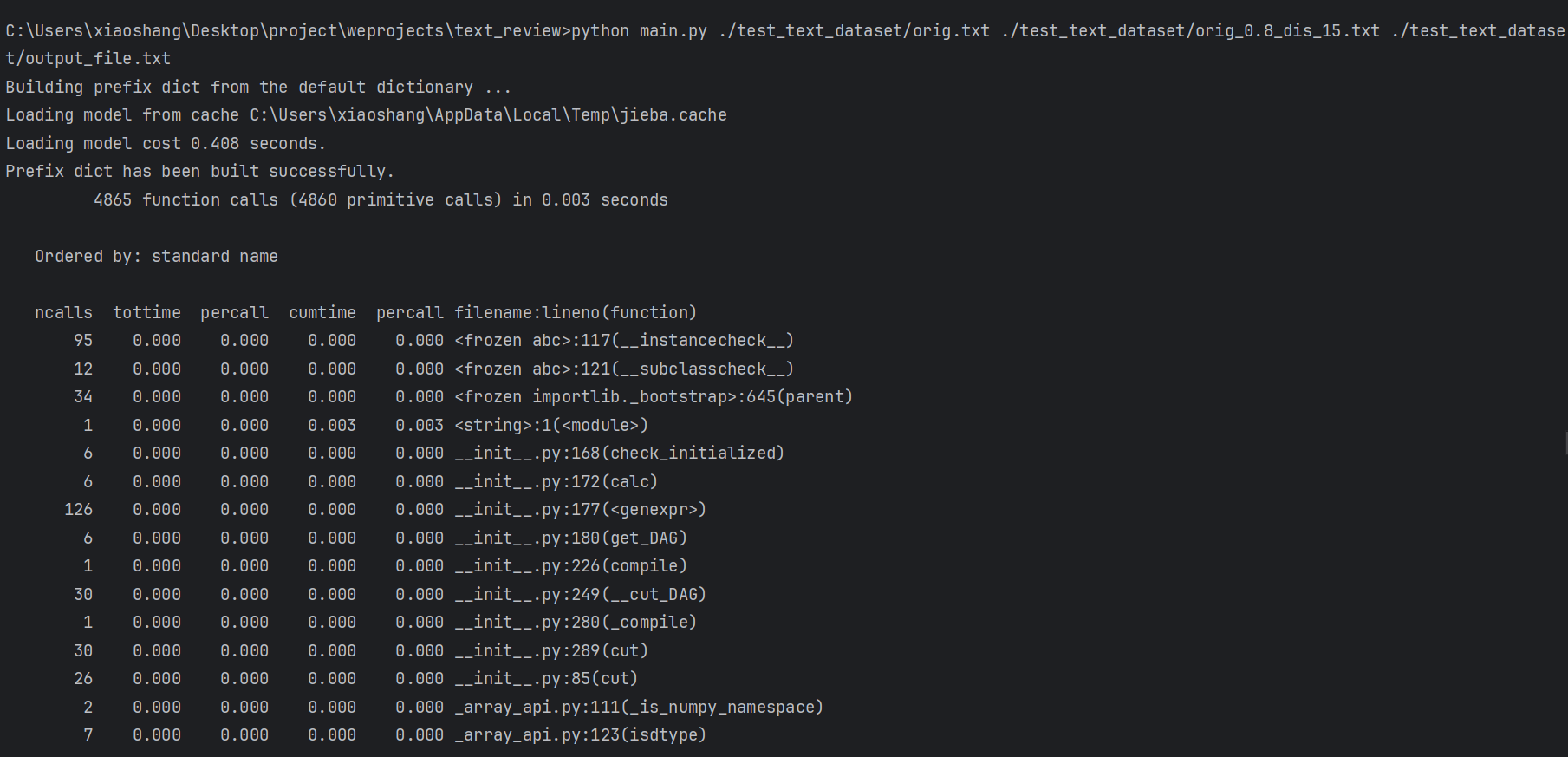
由于在pycharm编译器中实现项目,故利用cProfile进行性能分析。
import cProfile
import test_module
cProfile.run('calculate_similarity(orig_file, plag_file)')
六、总结
在项目过程中,查重程序的功能和推广适用性上还略显稚嫩。在后续中,更加完整的考虑项目实现的系统性和多样测试的需要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号