搭建ELK+Kafka+filebeat日志分析系统
摘要
顾名思义ELK+Kafka+Filebeat是由Elasticsearch,Logstash,Kibana,Kafka以及Filebeat几大组件构成的一个基于web页面的日志分析工具。
日志分析是运维工程师解决系统故障,发现问题的主要手段。日志包含多种类型,包括程序日志,系统日志以及安全日志等。通过对日志分析,预发故障的发生,又可以在故障发生时,寻找到蛛丝马迹,快速定位故障点。及时解决。
一、组件介绍
1.1、Elasticsearch
是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
1.2、Logstash
主要是用来日志的搜索、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等
1.3、Kibana
是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图标,为用户提供强大的数据可视化支持,它能够搜索、展示存储在Elasticsearch中索引数据。使用它可以很方便的使用图表、表格、地图展示和分析数据
1.4、Kafka
数据缓冲队列。作为消息队列解耦了处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃
- 发布和订阅记录流,类似于消息队列或企业消息传递系统
- 以容错持久的方式存储记录流
- 处理记录发生的流
1.5、filebeat
隶属于Beats,轻量级数据收集引擎。基于原先Logstash-forwarder的源码改造出来。换句话说:Filebeat就是新版的Logstash-forwarder,也会是ELK Stack在Agent的第一选择,目前Beats包含四种工具:
- Packetbeat(搜集网络流量数据)
- Metricbeat(搜集系统、进程和文件系统级别的CPU和内存使用情况等数据)
- Filebeat(搜集文件系统)
- Winlogbeat(搜集Windows事件日志数据)
二、环境介绍
|
主机名 |
IP地址 |
系统版本 |
安装软件 |
|
master |
20.0.0.10 |
Centos7.4 |
Elasticsearch/zookeeper/kafka/Logstash/kibana |
|
node1 |
20.0.0.20 |
Elasticsearch/zookeeper/kafka |
|
|
node2 |
20.0.0.30 |
Elasticsearch/zookeeper/kafka |
|
|
node3 |
20.0.0.40 |
Filebeat |
三、版本说明
jdk:1.8
Elasticsearch: 6.5.4
Logstash: 6.5.4
Kibana: 6.5.4
Kafka: 2.11.1
Filebeat: 6.5.4
相应的版本最好下载对应的插件
四、搭建架构
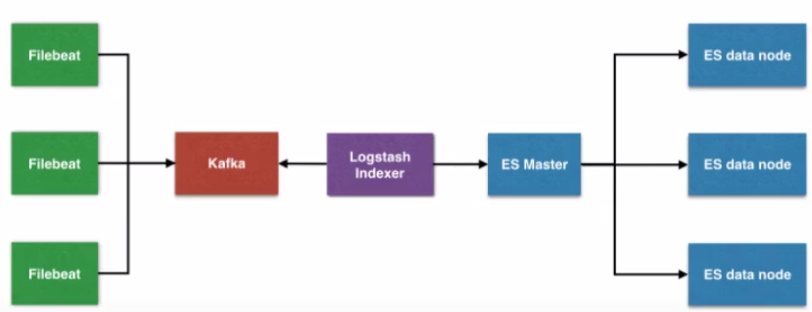
相关地址:
官网地址:https://www.elastic.co
官网搭建:https://www.elastic.co/guide/index.html
五、实施部署
下载并上传软件包到对应机器上
5.1、Elasticsearch集群部署
5.1.1、基本配置(四台节点都要设置)
1 修改主机名
2 [root@server1 ~]# hostnamectl set-hostname master
3 [root@server2 ~]# hostnamectl set-hostname node1
4 [root@server3 ~]# hostnamectl set-hostname node2
5 [root@server4 ~]# hostnamectl set-hostname node3
6
7 关闭防火墙和核心防护
8 [root@master ~]# systemctl stop firewalld.service #master上演示
9 [root@master ~]# setenforce 0
10
11 添加映射
12 [root@master ~]# vi /etc/hosts #master上演示
13 20.0.0.10 master
14 20.0.0.20 node1
15 20.0.0.30 node2
16 20.0.0.40 node3
5.1.2、安装配置jdk(下面的操作在master、node1和node2上配置,master上演示)
1 解压缩
2 [root@master ~]# tar zxf jdk-8u91-linux-x64.tar.gz -C /usr/local/
3
4 改文件名
5 [root@master ~]# mv /usr/local/jdk1.8.0_91/ /usr/local/java
6
7 环境变量
8 [root@master ~]# echo '
9 JAVA_HOME=/usr/local/java
10 PATH=$JAVA_HOME/bin:$PATH
11 export JAVA_HOME PATH
12 ' >> /etc/profile.d/java.sh
13
14 执行脚本
15 [root@master ~]# source /etc/profile.d/java.sh
16
17 查看java版本
18 [root@master ~]# java -version
19 java version "1.8.0_91"
20 Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
21 Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
5.1.3、安装配置ES
①创建运行ES的普通用户
1 [root@master ~]# useradd elsearch
2 [root@master ~]# echo "123456" | passwd --stdin "elsearch"
②安装配置ES
1 解压缩
2 [root@master ~]# tar zxf elasticsearch-6.5.4.tar.gz -C /usr/local/
3 [root@master ~]# mv /usr/local/elasticsearch-6.5.4/ /usr/local/elasticsearch
4
5 修改配置文件
6 [root@master ~]# vim /usr/local/elasticsearch/config/elasticsearch.yml
7 cluster.name: elk
8 node.name: elk01 #node1为elk02,node2为elk03
9 node.master: true
10 node.data: true
11 path.data: /data/elasticsearch/data
12 path.logs: /data/elasticsearch/logs
13 bootstrap.memory_lock: false
14 bootstrap.system_call_filter: false
15 network.host: 0.0.0.0
16 http.port: 9200
17 discovery.zen.ping.unicast.hosts: ["20.0.0.10","20.0.0.20","20.0.0.30"]
18 discovery.zen.ping_timeout: 150s
19 discovery.zen.fd.ping_retries: 10
20 client.transport.ping_timeout: 60s
21 http.cors.enabled: true
22 http.cors.allow-origin: "*"
23
24 创建ES数据及日志存储目录
25 [root@master ~]# mkdir -p /data/elasticsearch/data
26 [root@master ~]# mkdir -p /data/elasticsearch/logs
27
28 修改安装目录及存储目录权限
29 [root@master ~]# chown -R elsearch:elsearch /data/elasticsearch
30 [root@master ~]# chown -R elsearch:elsearch /usr/local/elasticsearch
配置项解读
1 cluster.name #集群名称,各节点配成相同的集群名称
2 node.name #节点名称,各节点配置不同
3 node.master #指示某个节点是否符合成为主节点的条件
4 node.data #指示节点是否为数据节点。数据节点包含并管理索引的一部分
5 path.data #数据存储目录
6 path.logs #日志存储目录
7 bootstrap.memory_lock #内存锁定,是否禁用交换
8 bootstrap.system_call_filter #系统调用过滤器
9 network.host #绑定节点IP
10 http.port #rest api端口
11 discovery.zen.ping.unicast.hosts #提供其他Elasticsearch服务节点的单点广播发现功能
12 discovery.zen.ping_timeout #节点在发现过程中的等待时间
13 discovery.zen.fd.ping_retries #节点发现重试次数
14 http.cors.enabled #是否允许跨源REST请求,用于允许head插件访问ES
15 http.cors.allow-origin #允许的源地址
③系统优化
1 修改内存参数
2 [root@master ~]# vim /etc/security/limits.conf
3 #末尾添加
4 * soft nofile 65536
5 * hard nofile 131072
6 * soft nproc 2048
7 * hard nproc 4096
8
9 增加最大内存映射数
10 [root@master ~]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf
11 [root@master ~]# sysctl -p
12 vm.max_map_count = 262144
④启动ES
1 切换到elsearch用户
2 [root@master ~]# su - elsearch
3
4 启动ES
5 [elsearch@master ~]$ cd /usr/local/elasticsearch/
6 [elsearch@master elasticsearch]$ nohup bin/elasticsearch &
7 [1] 41611
8 [elsearch@master elasticsearch]$ nohup: 忽略输入并把输出追加到"nohup.out"
9
10 查看进程
11 [elsearch@master elasticsearch]$ jobs
12 [1]+ 运行中 nohup bin/elasticsearch &
13
14 查看进程启动情况
15 [elsearch@master elasticsearch]$ tailf nohup.out
16 ......
17 [2020-12-10T16:32:24,284][INFO ][o.e.n.Node ] [elk01] started #显示started启动成功
⑤网页访问http://20.0.0.10:9200
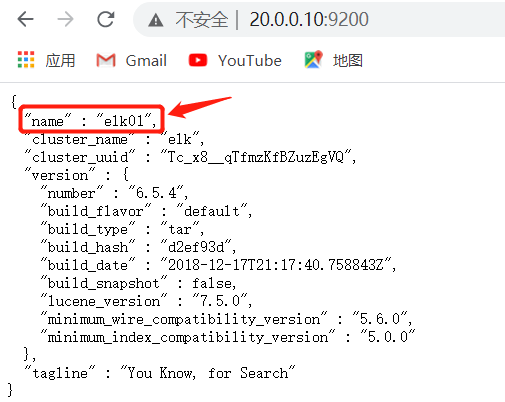
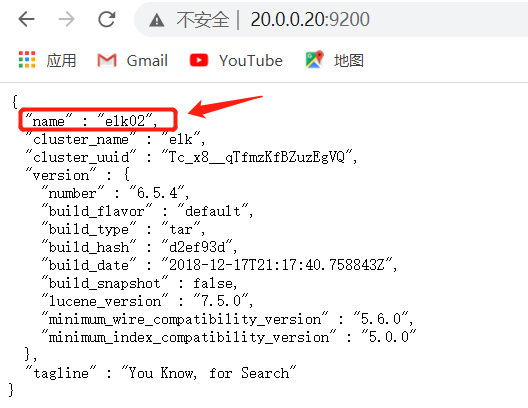
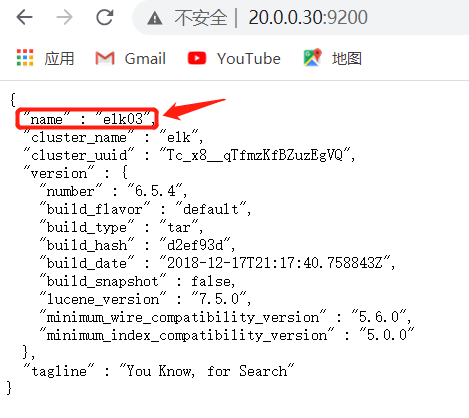
⑥安装配置head监控插件
1)安装node
1 添加阿里云源并重建yum源
2 [root@master elasticsearch]# wget -O /etc/yum.repos.d/CentOS-Base-epel.repo http://mirrors.aliyun.com/repo/Centos-7.repo
3 [root@master elasticsearch]# wget -P /etc/yum.repos.d http://mirrors.163.com/.help/CentOS7-Base-163.repo
4 [root@master elasticsearch]# yum clean all
5 [root@master elasticsearch]# yum makecache
6
7 安装node
8 [root@master elasticsearch]# wget https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gz #下载
9 [root@master ~]# tar zxf node-v4.4.7-linux-x64.tar.gz -C /usr/local/ #解压缩
10 [root@master ~]# mv /usr/local/node-v4.4.7-linux-x64/ /usr/local/node
11 [root@master ~]# echo '
12 NODE_HOME=/usr/local/node
13 PATH=$NODE_HOME/bin:$PATH
14 export NODE_HOME PATH
15 ' >> /etc/profile.d/node.sh
16 [root@master ~]# source /etc/profile.d/node.sh
17 [root@master ~]# node --version #检查版本
18 v4.4.7
2)下载head插件
1 [root@master ~]# wget https://github.com/mobz/elasticsearch-head/archive/naster.zip
2 [root@master ~]# unzip -d /usr/local/ master.zip
3)安装grunt
1 [root@master ~]# cd /usr/local/elasticsearch-head-master/
2 [root@master elasticsearch-head-master]# npm install -g grunt-cli
3 [root@master elasticsearch-head-master]# grunt --version #查看版本
4 [root@master elasticsearch-head-master]# grunt --version
5 grunt-cli v1.3.2
4)修改head源码
1 [root@master elasticsearch-head-master]# vi /usr/local/elasticsearch-head-master/Gruntfile.js
2 94 connect: {
3 95 server: {
4 96 options: {
5 97 port: 9100,
6 98 base: '.',
7 99 keepalive: true,
8 100 hostname:'*'
9 #注意要在true后面加“,”而hostname“*”后不需要
10
11 [root@master elasticsearch-head-master]# vi /usr/local/elasticsearch-head-master/_site/app.js
12 4385 init: function(parent) {
13 4386 this._super();
14 4387 this.prefs = services.Preferences.instanc e(); 4388 this.base_uri = this.config.base_uri || t his.prefs.get("app-base_uri") || "http://20.0.0.10:9200";
15 #原本是http://localhost:9200
5)下载head必要的文件
1 [root@master ~]# wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
2 [root@master ~]# yum -y install bzip2
3 [root@master ~]# tar jxf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /tmp
6)运行head
1 [root@master elasticsearch-head-master]# npm install --registry=https://registry.npm.taobao.org
2 [root@master elasticsearch-head-master]# nohup grunt server &
3 [1] 42584
4 [root@master elasticsearch-head-master]# nohup: 忽略输入并把输出追加到"nohup.out"
7)测试网页访问https://20.0.0.10:9100
5.2、Kibana部署
5.2.1、安装配置Kibana(master上安装)
①安装
1 [root@master ~]# tar zxf kibana-6.5.4-linux-x86_64.tar.gz -C /usr/local/
②配置
1 [root@master ~]# echo '
2 server.port: 5601
3 server.host: "20.0.0.10"
4 elasticsearch.url: "http://20.0.0.10:9200"
5 kibana.index: ".kibana"
6 ' >> /usr/local/kibana-6.5.4-linux-x86_64/config/kibana.yml
③启动
1 [root@master ~]# cd /usr/local/kibana-6.5.4-linux-x86_64/
2 [root@master kibana-6.5.4-linux-x86_64]# nohup ./bin/kibana &
3 [2] 42730
4 [root@master kibana-6.5.4-linux-x86_64]# nohup: 忽略输入并把输出追加到"nohup.out"
5.3、Kafka部署
5.3.1、安装配置jdk(master、node1和node2上操作,master上演示)
1 解压缩
2 [root@master ~]# tar zxf jdk-8u91-linux-x64.tar.gz -C /usr/local/
3
4 改文件名
5 [root@master ~]# mv /usr/local/jdk1.8.0_91/ /usr/local/java
6
7 环境变量
8 [root@master ~]# echo '
9 JAVA_HOME=/usr/local/java
10 PATH=$JAVA_HOME/bin:$PATH
11 export JAVA_HOME PATH
12 ' >> /etc/profile.d/java.sh
13
14 执行脚本
15 [root@master ~]# source /etc/profile.d/java.sh
16
17 查看java版本
18 [root@master ~]# java -version
19 java version "1.8.0_91"
20 Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
21 Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
5.3.2、安装配置ZK
Kafka运行依赖ZK,Kafka官网提供的tar包中,以及包含了ZK,这里不再额外下载ZK程序
①安装
1 [root@master ~]# tar zxf kafka_2.11-1.1.1.tgz -C /usr/local/
②配置
1 [root@master ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-1.1.1/config/zookeeper.properties #所有未注释内容前加#
2 [root@master ~]# echo '
3 > dataDir=/opt/data/zookeeper/data
4 > dataLogDir=/opt/data/zookeeper/logs
5 > clientPort=2181
6 > tickTime=2000
7 > initLimit=20
8 > syncLimit=10
9 > server.1=20.0.0.10:2888:3888
10 > server.1=20.0.0.20:2888:3888
11 > server.1=20.0.0.30:2888:3888
12 > ' >>/usr/local/kafka_2.11-1.1.1/config/zookeeper.properties
③创建目录
1 [root@master ~]# mkdir -p /opt/data/zookeeper/{data,logs}
④创建myid文件
1 [root@master ~]# echo 1 > /opt/data/zookeeper/data/myid #每台Kafka机器都要做成唯一ID
5.3.3、配置Kafka
①配置
1 [root@master ~]# sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-1.1.1/config/server.properties
2
3 echo '
4 broker.id=1 #Kafka机器的每个ID和myid保持一样
5 listeners=PLAINTEXT://20.0.0.10:9092 #监听自己的IP地址
6 num.network.threads=3
7 num.io.threads=8
8 socket.send.buffer.bytes=102400
9 socket.receive.buffer.bytes=102400
10 socket.request.max.bytes=104857600
11 log.dirs=/opt/data/kafka/logs
12 num.partitions=6
13 num.recovery.threads.per.data.dir=1
14 offsets.topic.replication.factor=2
15 transaction.state.log.replication.factor=1
16 transaction.state.log.min.isr=1
17 log.retention.hours=168
18 log.segment.bytes=536870912
19 log.retention.check.interval.ms=300000
20 zookeeper.connect=20.0.0.10:2181,20.0.0.20:2181,20.0.0.30:2181
21 zookeeper.connection.timeout.ms=6000
22 group.initial.rebalance.delay.ms=0
23 ' >> /usr/local/kafka_2.11-1.1.1/config/server.properties
②创建log目录
1 [root@master ~]# mkdir -p /opt/data/kafka/logs
③启动、验证ZK集群
1 启动
2 [root@master kafka_2.11-1.1.1]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
3 [3] 43030
4 [root@master kafka_2.11-1.1.1]# nohup: 忽略输入并把输出追加到"nohup.out"
5
6 验证,查看ZK配置
7 [root@master kafka_2.11-1.1.1]# echo conf | nc 127.0.0.1 2181
8 clientPort=2181
9 dataDir=/opt/data/zookeeper/data/version-2
10 dataLogDir=/opt/data/zookeeper/logs/version-2
11 tickTime=2000
12 maxClientCnxns=60
13 minSessionTimeout=4000
14 maxSessionTimeout=40000
15 serverId=0
16
17 查看ZK状态
18 [root@master kafka_2.11-1.1.1]# echo stat | nc 127.0.0.1 2181
19 Zookeeper version: 3.4.10-39d3a4f269333c922ed3db283be479f9deacaa0f, built on 03/23/2017 10:13 GMT
20 Clients:
21 /127.0.0.1:42614[0](queued=0,recved=1,sent=0)
22
23 Latency min/avg/max: 0/0/0
24 Received: 5
25 Sent: 4
26 Connections: 1
27 Outstanding: 0
28 Zxid: 0x0
29 Mode: standalone
30 Node count: 4
31
32 查看端口
33 [root@master kafka_2.11-1.1.1]# lsof -i:2181
34 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
35 java 43030 root 96u IPv6 85536 0t0 TCP *:eforward (LISTEN)
④启动、验证Kafka
1 启动
2 [root@master kafka_2.11-1.1.1]# cd /usr/local/kafka_2.11-1.1.1/
3 [root@master kafka_2.11-1.1.1]# nohup bin/kafka-server-start.sh config/server.properties &
4 [4] 43413
5 [root@master kafka_2.11-1.1.1]# nohup: 忽略输入并把输出追加到"nohup.out"
6
7 验证
8 在20.0.0.10上创建topic
9 [root@master kafka_2.11-1.1.1]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic
10 Created topic "testtopic".
11 查询20.0.0.10上的topic
12 [root@master kafka_2.11-1.1.1]# bin/kafka-topic.sh --zookeeper 20.0.0.10:2181 --list
13 testtopic
14 查询20.0.0.20上的topic
15 [root@node1 kafka_2.11-1.1.1]# bin/kafka-topic.sh --zookeeper 20.0.0.20:2181 --list
16 testtopic
17 查询20.0.0.30上的topic
18 [root@node2 kafka_2.11-1.1.1]# bin/kafka-topic.sh --zookeeper 20.0.0.30:2181 --list
19 testtopic
5.4、Logstash部署
5.4.1、安装(master上安装)
1 [root@master ~]# tar zxf logstash-6.5.4.tar.gz -C /usr/local/
5.4.2、配置
1 创建目录
2 [root@master ~]# mkdir -p /usr/local/logstash-6.5.4/etc/conf.d
3
4 [root@master ~]# vi /usr/local/logstash-6.5.4/etc/conf.d/input.conf
5 input {
6 kafka {
7 type => "httpd_kafka"
8 codec => "json"
9 topics => "httpd"
10 decorate_events => true
11 bootstrap_servers => "20.0.0.10:9092, 20.0.0.20:9092, 20.0.0.30:9092"
12 }
13 }
14
15 [root@master ~]# vi /usr/local/logstash-6.5.4/etc/conf.d/output.conf
16 output {
17 if [type] == "httpd_kafka" {
18 elasticsearch {
19 hosts => ["20.0.0.10","20.0.0.20","20.0.0.30"]
20 index => 'logstash-httpd-%{+YYYY-MM-dd}'
21 }
22 }
23 }
5.4.3、启动
1 [root@master logstash-6.5.4]# nohup bin/logstash -f etc/conf.d/ --config.reload.automatic &
2 [7] 46230
3 [root@master logstash-6.5.4]# nohup: 忽略输入并把输出追加到"nohup.out"
5.5、Filebeat部署
5.5.1、下载(node3上安装)
1 [root@node3 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.4-linux-x86_64.tar.gz
5.5.2、解压
1 [root@node3 ~]# tar zxf filebeat-6.5.4-linux-x86_64.tar.gz -C /usr/local/
2 [root@node3 ~]# cd /usr/local/
3 [root@node3 local]# mv filebeat-6.5.4-linux-x86_64/ filebeat
4 [root@node3 local]# cd filebeat/
5.5.3、修改配置
修改Filebeat配置,支持收集本地目录日志,并输出日志到Kafka集群中
1 [root@node3 filebeat]# cp filebeat.yml filebeat.yml.bak
2 [root@node3 filebeat]# vim filebeat.yml
3 filebeat.prospectors:
4 - input_type: log
5 paths:
6 - /var/log/httpd/access_log
7 json.keys_under_root: true
8 json.add_error_key: true
9 json.message_key: log
10
11 output.kafka:
12 hosts: [ "20.0.0.10:9092","20.0.0.20:9092","20.0.0.30:9092" ]
13 topic: 'httpd'
5.5.4、安装httpd服务
1 [root@node3 filebeat]# yum -y install httpd
2 [root@node3 filebeat]# systemctl start httpd
3 [root@node3 filebeat]# netstat -anpt | grep httpd
4 tcp6 0 0 :::80 :::* LISTEN 57726/httpd
5 [root@node3 filebeat]# ll /var/log/httpd/
6 总用量 4
7 -rw-r--r--. 1 root root 0 12月 10 18:38 access_log
8 -rw-r--r--. 1 root root 925 12月 10 18:38 error_log
5.5.5、启动
1 [root@node3 filebeat]# nohup ./filebeat -e -c filebeat.yml &
2 [1] 57774
3 [root@node3 filebeat]# nohup: 忽略输入并把输出追加到"nohup.out"
5.5.6、查看状态
1 [root@node3 filebeat]# tailf nohup.out
5.5.7、查看master上logstash
[root@master kibana-6.5.4-linux-x86_64]# cd /usr/local/logstash-6.5.4/
[root@master logstash-6.5.4]# tailf nohup.out
5.5.8、网页访问http://20.0.0.40(多访问几次)
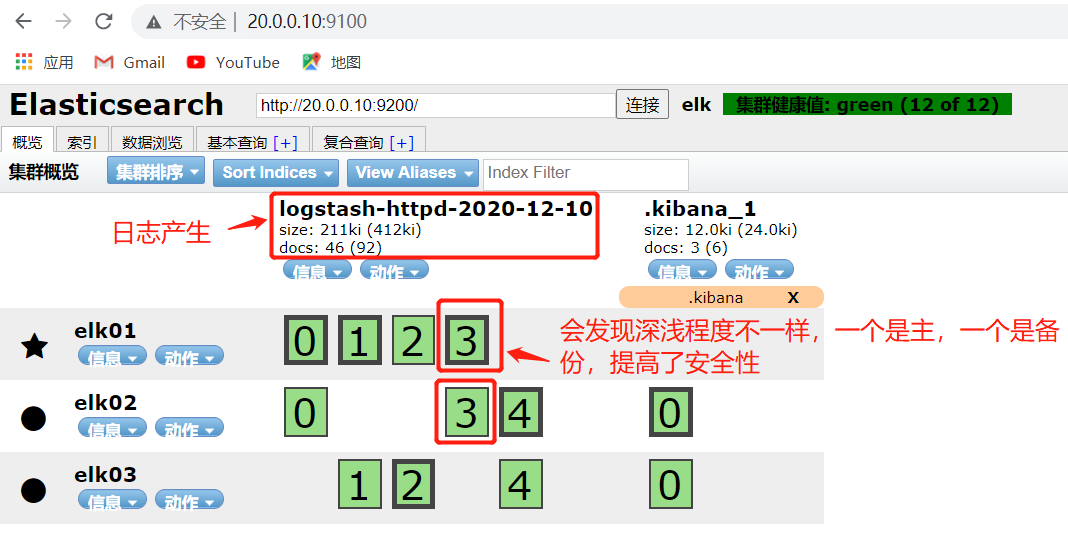
5.5.9、网页访问http://20.0.0.10:9100,查看是否有所有日志产生
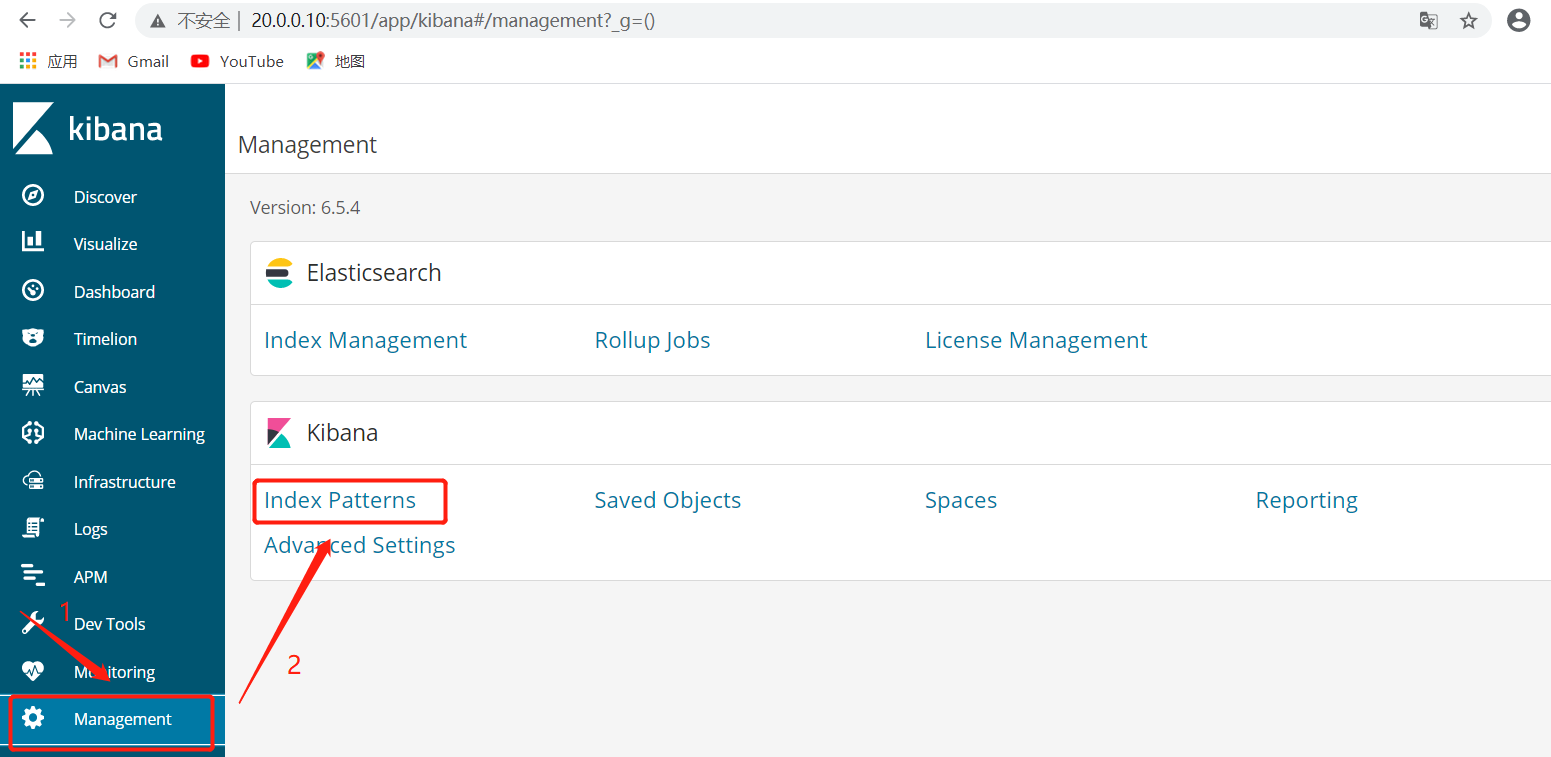
5.5.10、网页查看http://20.0.0.10:5601的Kibana界面,去看日志状态
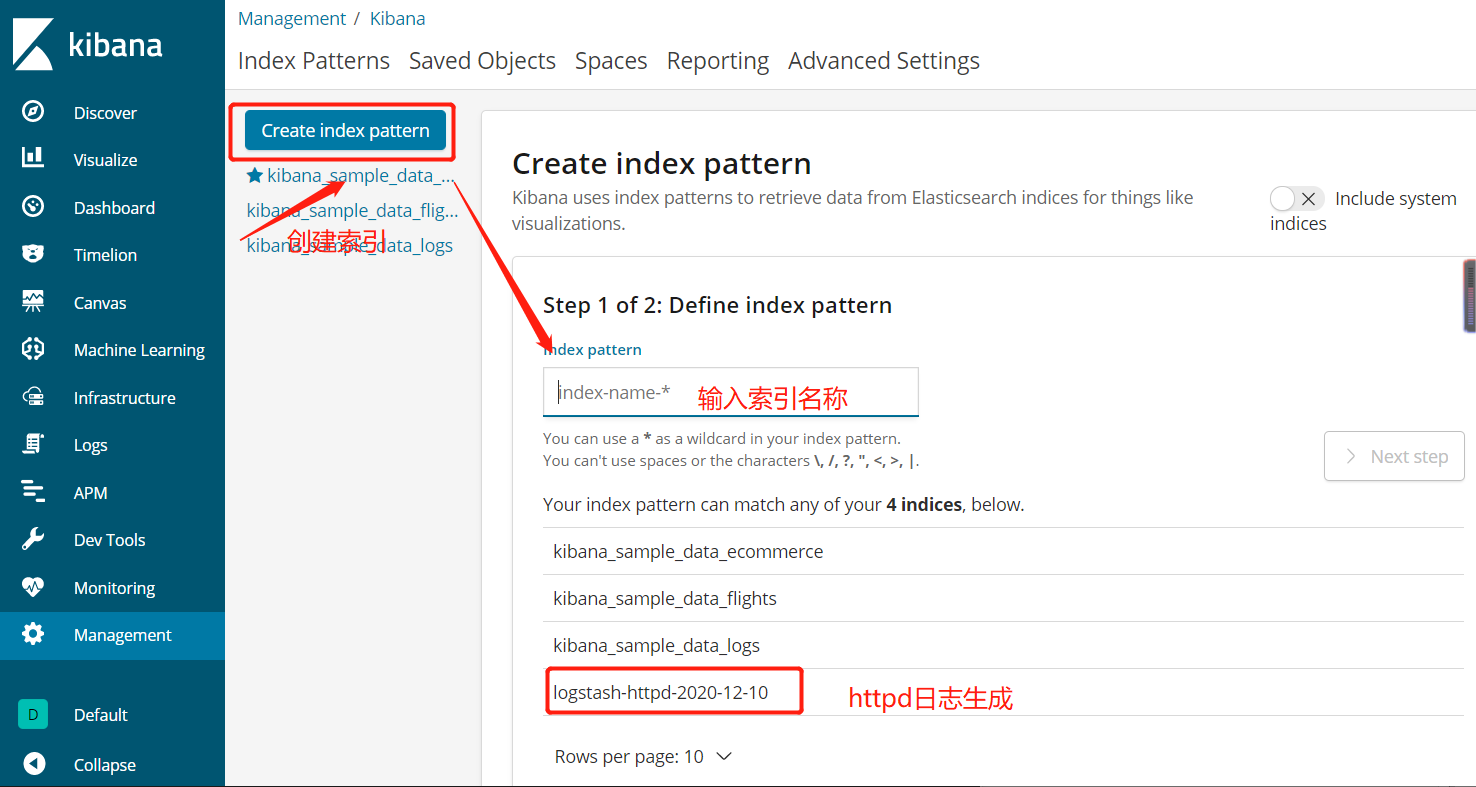
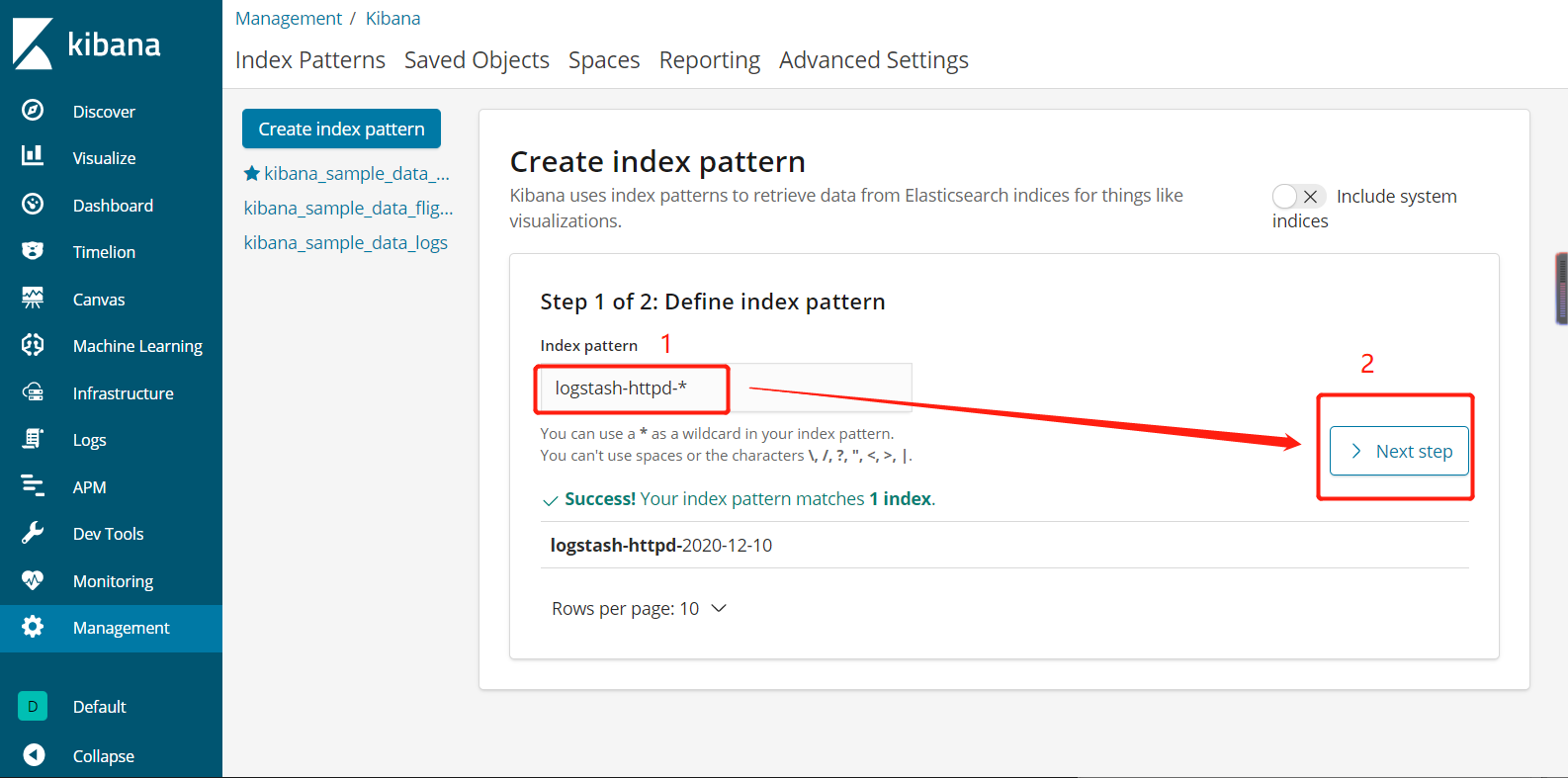
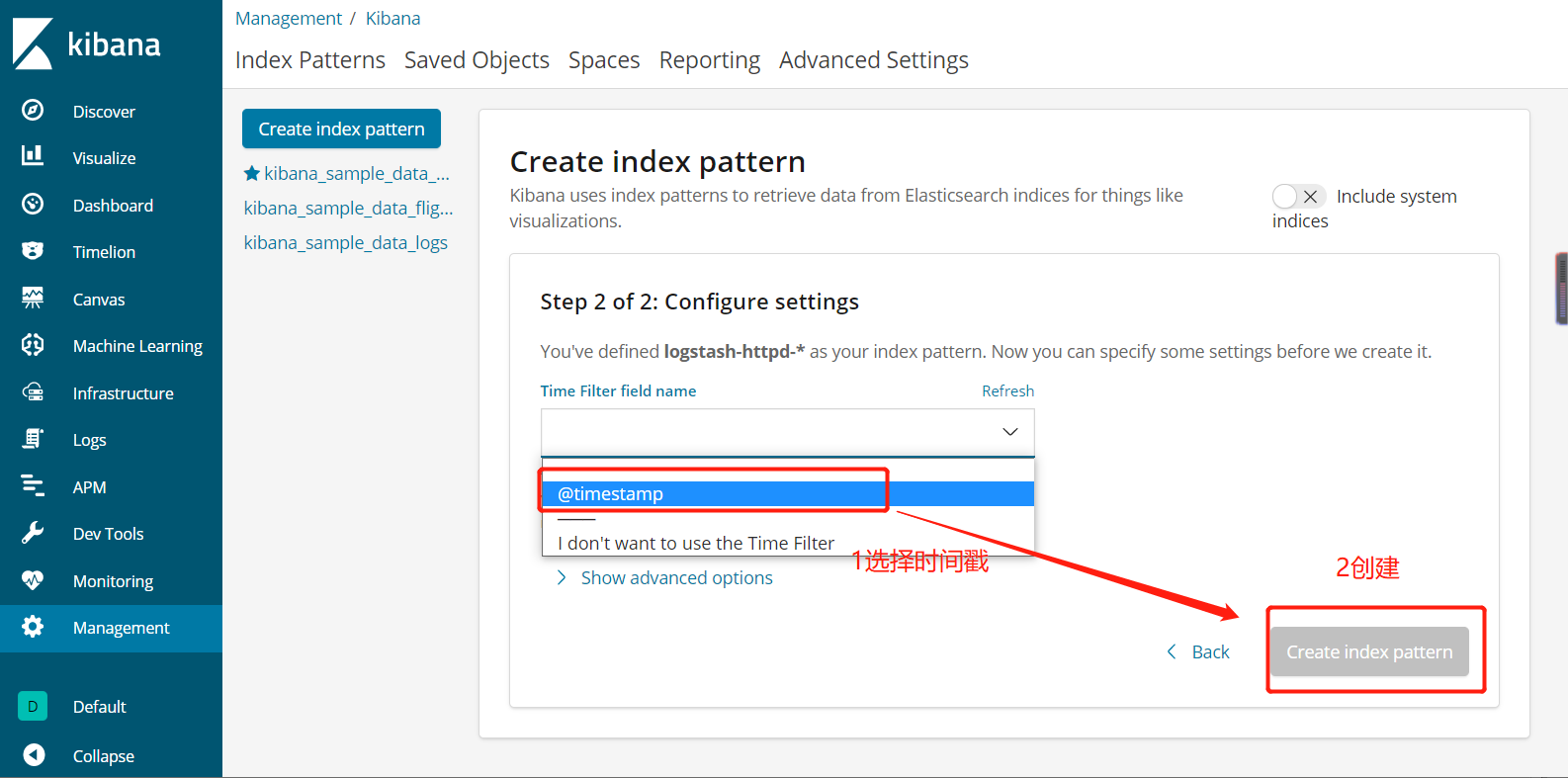
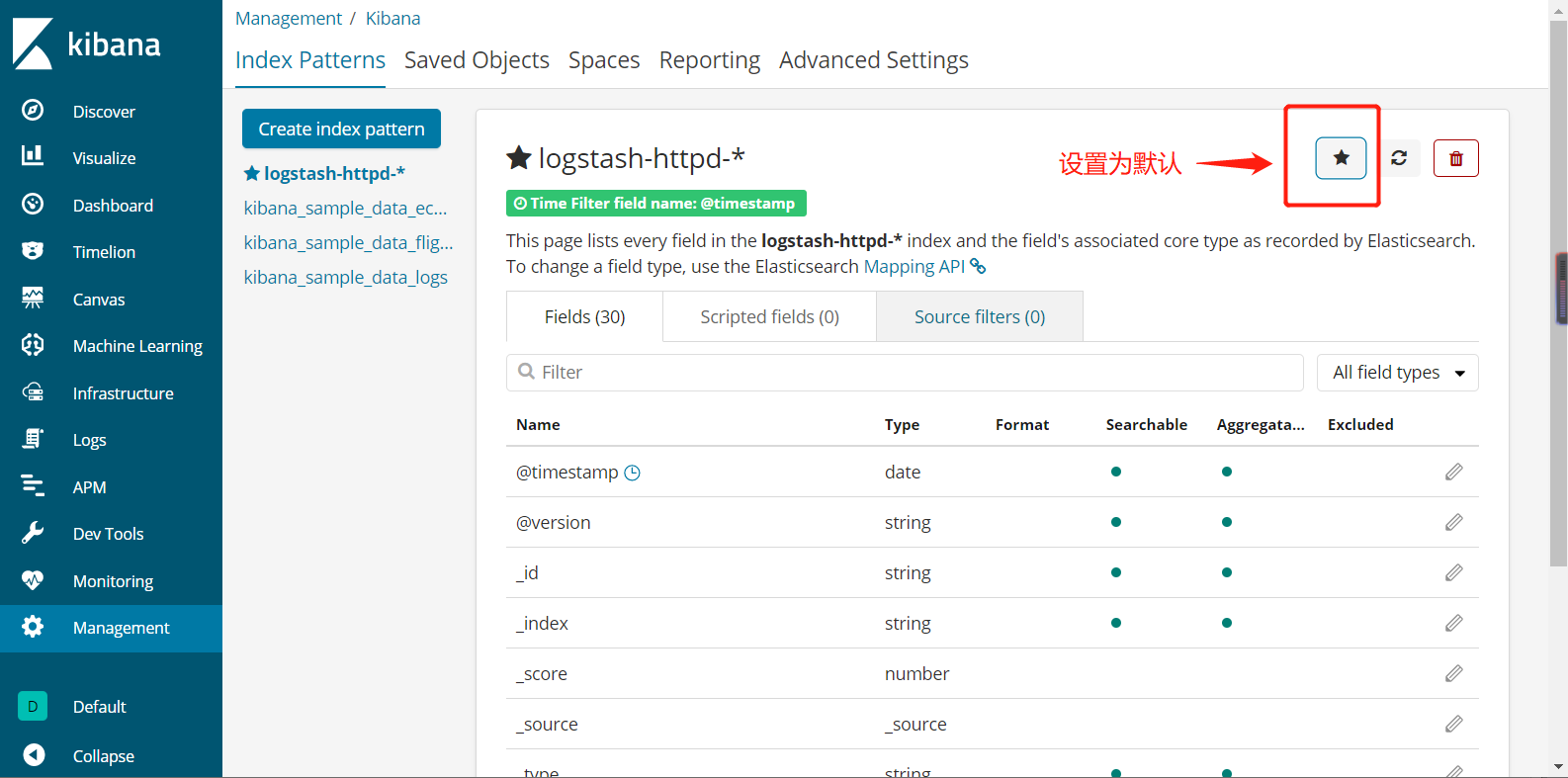
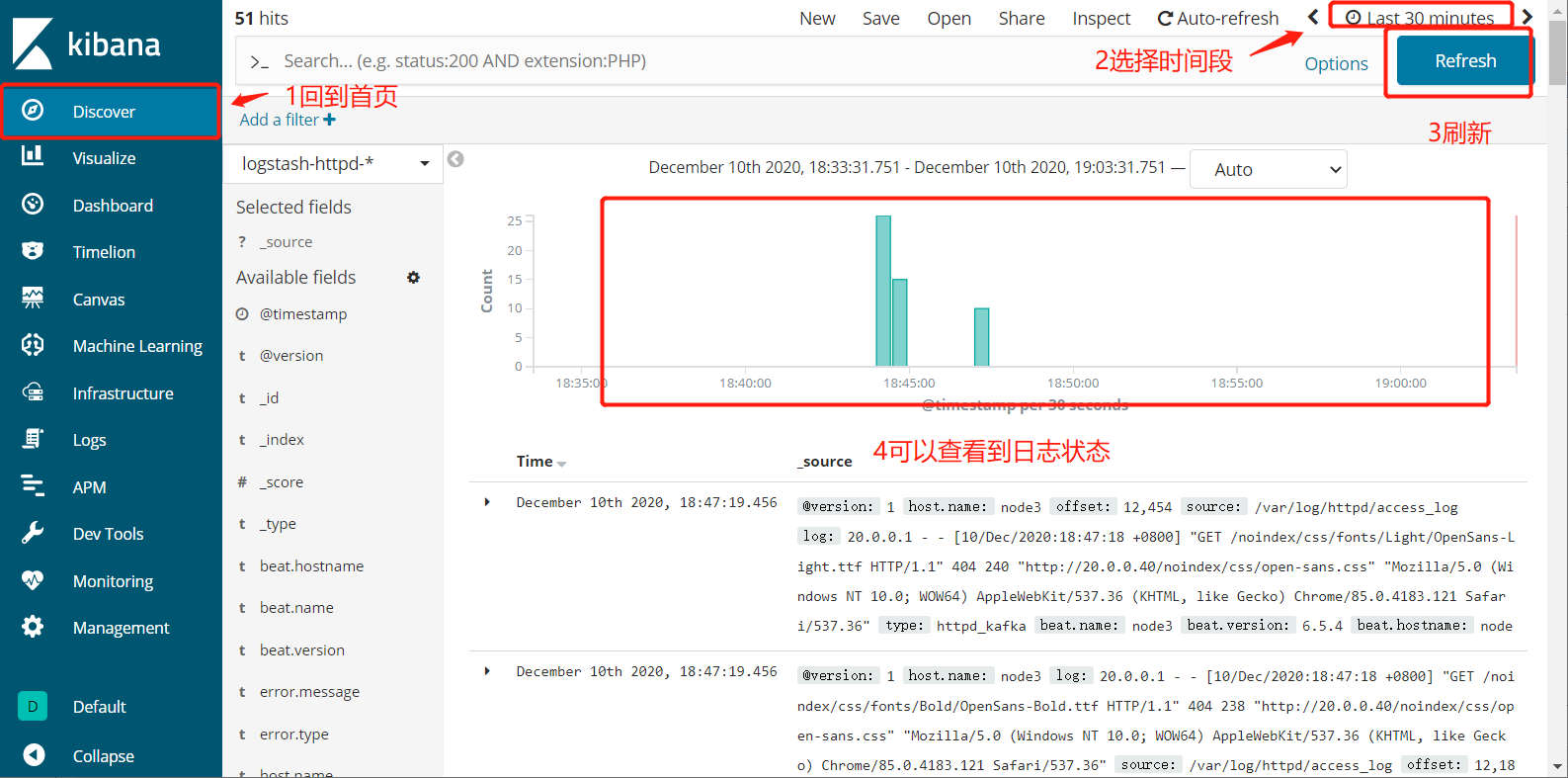
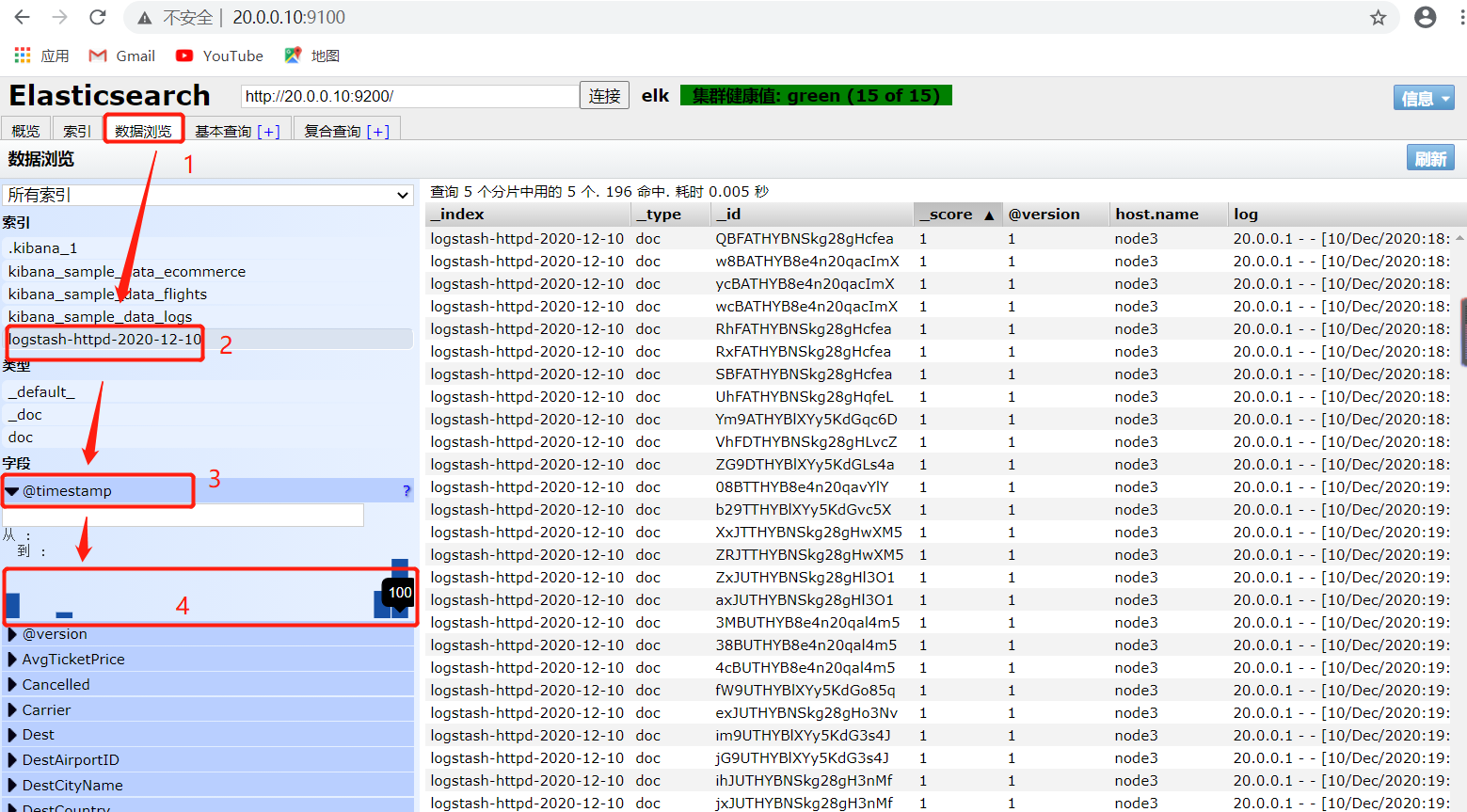
5.5.11、网页访问http://20.0.0.10:9100也可以看到访问记录
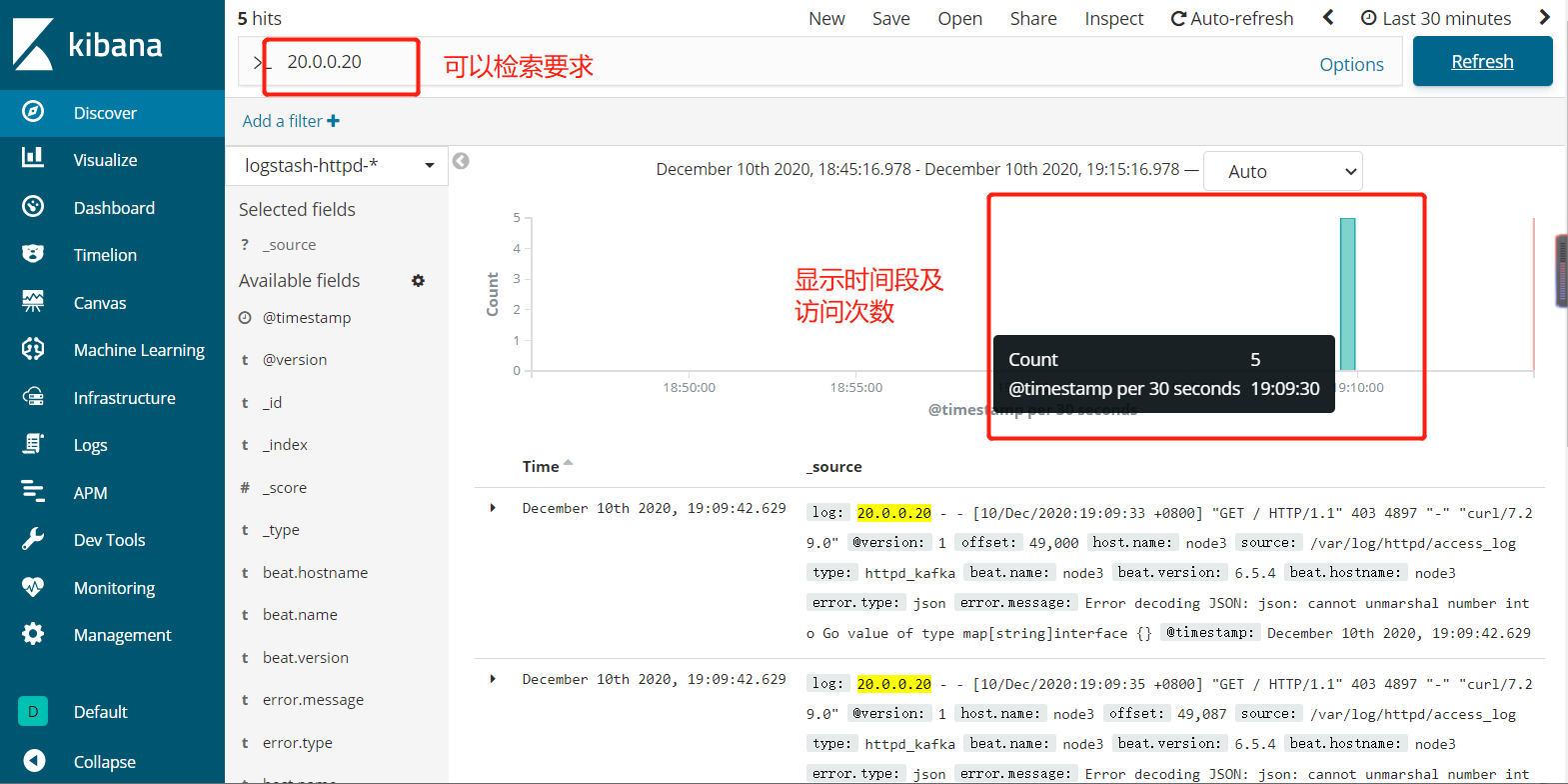
5.5.12、网页访问http://20.0.0.10:5601
六、总结
ELK+Kafka+filebeat日志分析系统是一款非常强大的日志分析工具,能够帮助运维工程师更快更准确的定位到想要的日志,特别是kibana可视化工具,功能强大,使用起来非常人性化

