

C# 词法分析器(七)总结
系列导航
在之前的六篇文章中,我比较详细的介绍了与词法分析器相关的算法。它们都比较关注于实现的细节,感觉上可能比较凌乱,本篇就从整体上介绍一下如何定义词法分析器,以及如何实现自己的词法分析器。
第二节完整的介绍了如何定义词法分析器,可以当作一个词法分析器使用指南。如果不关心词法分析器的具体实现的话,可以只看第二节。
一、类库的改变
首先需要说明一下我对类库做的一些修改。词法分析部分的接口,与当初写《C# 词法分析器》系列时相比,已经发生了不小的改变,有必要做一下说明。
1. 词法单元的标识符
词法单元(token)最初的定义是一个 Token 结构,使用一个 int 属性作为词法单元的标识符,这也是很多词法分析器的通用做法。
但后来做语法分析的时候,感觉这样非常不方便。因为目前还不支持从定义文件生成词法分析器代码,只能在程序里面定义词法分析器。而 int 本身是不具有语义的,作为词法单元的标识符来使用,不但不方便还容易出错。
后来尝试过使用字符串作为标识符,虽然解决了语义的问题,但仍然容易出错,实现上也会复杂些(需要保存字符串字典)。
而既简单,又具有语义的解决方案,就是使用枚举了。枚举名称提供了语义,枚举值又可以转换为整数,而且还能够提供编译期检查,完全避免了拼写错误,所以现在的词法单元便定义为 Token<T> 类,与之相关的很多类也同样带上了泛型参数 T。
2. 命名空间
之前的命名空间是 Cyjb.Compiler 和 Cyjb.Compiler.Lexer,现在被改成了 Cyjb.Compilers 和 Cyjb.Compilers.Lexers,毕竟命名空间名称还是比较适合使用复数。
3. 词法分析器上下文
之前对词法分析器上下文的切换,可以使用上下文的索引、标签或 LexerContext 实例本身。但现在只能够通过标签进行切换,这样实现起来更简单些,使用上也不会受到过多影响。
4. DFA 的表示
原先 LexerRule 类中对 DFA 的表示有些简单粗暴,对于不了解具体实现的人来说,很难理解 DFA 的表示。现在重新规划了 LexerRule<T> 类中的接口,理解起来会更容易些。
二、定义词法分析器
这一节是 Cyjb.Compilers 类库中词法分析器的使用指南,包含了完整的文档、实例以及相关注意事项。类库的源码可以从 Cyjb.Compilers 项目找到,类库文档请参见 wiki。
1. 定义词法单元的标识符
前面说到,目前是使用枚举类型作为词法单元的标识符,这个枚举类型中的字段可以任意定义,没有任何限制。不过,为了方便之后的语法分析部分,特别要求枚举值必须是从 0 开始的整数,枚举值最好是连续的,因为不连续的枚举值会导致语法分析部分浪费更多的空间。
使用特殊的值 -1 来表示文件结束(EndOfFile),该值可以从 Token<T>.EndOfFile 字段得到,也可以通过 Token<T>.IsEndOfFile 属性获取词法单元是否表示文件结束。
这里仍然使用计算器作为示例,以下代码便定义了作为标识符的枚举:

在使用的时候,显然会比整数更加方便。
2. 定义词法分析器的上下文
词法分析器的所有定义都是从 Cyjb.Compilers.Grammar<T> 类开始的,因此首先需要实例化一个 Grammar<T> 类的实例:
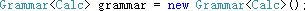
词法分析器的上下文,可以用来控制规则是否生效。上下文有两种类型:包含型或者排除型。
- 如果当前是包含型上下文,那么会激活当前上下文的所有规则,同时会激活所有没有指定任何上下文的规则。
- 如果当前是排除型上下文,那么只会激活当前上下文的所有规则,其它任何规则都不会被激活。
使用以下的方法来分别定义排除型和包含型的词法分析器上下文,label 参数即为上下文的标签:

默认的词法分析器上下文是 "Initial",通过该标签可以切换到默认的上下文中。需要特别注意的是,由于实现上的原因,上下文必须先于所有终结符定义。
例如,以下的代码定义了一个包含型上下文 Inc,以及一个排除型上下文 Exc。
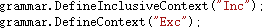
3. 定义正则表达式
使用以下的方法来定义正则表达式:
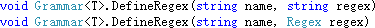
正则表达式可以通过 Cyjb.Compilers.RegularExpressions.Regex 类的相关方法构造得到,也可以直接使用表示正则表达式的字符串,相关定义的规则可以参考 《C# 词法分析器(三)正则表达式》。
注意,这里定义的正则表达式仅仅用于简化终结符定义,方便重复使用一些通用或复杂的正则表达式,并没有其它的作用。这里定义的正则表达式也不可以包含向前看符号(/)、行首限定符(^)、行尾限定符($)或者上下文(<context>)。
例如,以下代码定义了一个名为 digit 的正则表达式,以后需要表示数字的时候,就可以直接通过 “{digit}” 来引入,而不需要每次都写 “[0-9]+”。

4. 定义终结符
使用 Grammar<T>.DefineSymbol 方法的相关重载来定义终结符,如以下代码所示:

这些重载被分成了三组。第一组重载,接受 T id 作为与词法单元对应的标识符,和相应的正则表达式及其上下文。当相应的终结符被匹配后,自动返回标识符为 id 的 Token<T>实例。
第二组重载,具有额外的参数 action,这是只包含一个 ReaderController<T> 参数的委托,当匹配了相应的终结符时,就会被调用。通过 ReaderController<T> 的相应属性和方法,可以对词法分析过程进行一些控制。
最后一组重载,缺少了标识符 id,也就无法自动返回 Token<T> 实例,因此必须指定匹配到相应终结符时要执行的方法。
终结符的动作
在成功匹配某个终结符时,就会执行相应的动作,该动作是一个 Action<ReaderController<T>> 类型的委托。
ReaderController<T> 类包含了与当前匹配的终结符相关的信息,包括上下文、标识符、源文件和文本。主要的方法有 Accept、More、Reject 以及操纵上下文的方法 BeginContext、PopContext 和 PushContext。
Accept 方法会接受当前的匹配,词法分析器会返回表示当前匹配的 Token<T> 实例。
More 方法会通知词法分析器,保留本次匹配的文本。假设本次匹配的文本是 "foo",下次匹配的文本是 "bar",如果本次匹配时调用了 More 方法,下次匹配的文本就会变成 "foobar"。
Reject 方法会拒绝当前的匹配,转而使用次优的规则继续尝试匹配。详细信息请参考《C# 词法分析器(六)构造词法分析器》的 2.4 节“支持 Reject 动过的词法分析器”。
Accept 方法和 Reject 方法不能够在一次匹配中同时调用,因为它们是互斥的动作。如果在一次匹配中两个方法都没有调用,那么词法分析器会什么都不做——丢弃本次匹配的结果,直接进行下一次匹配。
对于词法分析器上下文的控制,简单的用法就是利用上下文来切换匹配的规则集,以实现一些“次级语法”,可以参考《C# 词法分析器(六)构造词法分析器》的 3.3 节给出的示例“转义的字符串”。
下面给出计算器的终结符定义。其中,Id 的定义是通过引入正则表达式 digit 来完成的,而且它定义了自己的动作,会将自己对应的文本转换为 double 类型,并保存到 Token<T>.Value 属性中。最后一条语句,通过定义空的动作,使得匹配到的空白被丢弃。

5. 构造词法分析器
以上四步便完成了词法分析器的定义,接下来就是构造词法分析器。使用以下四个方法,就可以直接构造出相应的词法单元读取器(TokenReader<T> 的子类的实例):

如果调用的是 GetReader 方法重载,则认为动作中不包含拒绝(Reject),会返回比较简单但更高效的词法分析器实现。如果调用的是 GetRejectableReader 方法重载,则认为动过中包含拒绝(Reject),会返回功能更强大但效率略低的词法分析器实现。
其规则是:
- 如果不包含向前看和拒绝动作,则返回 SimpleReader<T> 的实例。
- 如果只包含定长的向前看(不包含变长的向前看或拒绝动作),则返回 FixedTrailingReader<T> 的实例。
- 如果只包含拒绝动作(不包含向前看),则返回 RejectableReader<T> 的实例。
- 如果包含变长的向前看,或者同时包含拒绝动作和向前看(无论是否变长),则返回 RejectableTrailingReader<T> 的实例。
关于其中实现的细节,请参考《C# 词法分析器(六)构造词法分析器》。
所有的词法单元读取器,都继承自 TokenReader<T> 类,主要包含两个方法:PeekToken 和 ReadToken,与字面意义相同,就是读取输入流中的下一个词法单元,不更改(Peek)或提升(Read)输入流的字符位置。
TokenReader<T> 类还实现了 IEnumerable<T> 接口,因此可以使用 foreach 语句从中读取词法单元。但是,TokenReader<T> 本身并不会储存之前读取过的词法单元,在被枚举的时候,实际上还是会调用 ReadToken 方法,因此只能在一个位置枚举 TokenReader<T>,而且只能枚举一次,枚举完毕后,TokenReader<T> 也同样到达了流的结尾。如果希望多次枚举,还请缓存到数组中再进行操作。
以下是构造出计算器的词法单元读取器,并输出所有读取到的词法单元的代码:

最后是完整的构造计算器的代码:

代码的输出结果如下图所示:
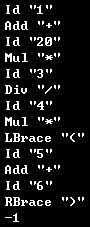
可以看到,最后总是会以特殊值 -1 结束,表示文件结束。
三、自定义词法分析器
Cyjb.Compilers 项目中,提供了完整的词法分析器实现。但是,在实际的使用中,难免会遇到各种各样的需求,可能已实现的词法分析器是无法满足的,此时就必须自己完成词法分析器了。
在完成定义词法分析器后,可以从 Grammar<T>.LexerRule 属性获取到一个 Cyjb.Compilers.Lexers.LexerRule<T> 对象,该实例中存储了一个词法分析器所需的全部信息,并且不会依赖于原始的 Grammar<T> 对象。它就是自定义词法分析器的核心。
下图是与 LexerRule<T> 对象相关的类图。这四个类表示了词法分析器的核心信息,即生成的 DFA 的数据。

图 1 与 LexerRule<T> 相关的类图
LexerRule<T>.CharClass 属性保存了与字符类相关的数据,这是一个长度为 65536 的数组,保存了每个字符所属的字符类。使用从 0 开始的连续整数表示不同的字符类,所有包含的字符类的数量可从 LexerRule<T>.CharClassCount 属性获取。关于字符类的详细信息,请参考《C# 词法分析器(四)构造 NFA》的第三节“划分字符类”。
LexerRule<T>.Contexts 属性保存了与词法分析器的上下文相关的数据,这是一个字典,其键为上下文的标签,值为相应的 DFA 头节点索引。LexerRule<T>.ContextCount 属性表示了上下文的数量。
LexerRule<T>.Symbols 属性是定义的终结符的列表,列表的每一项都是一个 SymbolData<T> 结构,包含终结符的标识符、动作和向前看信息。
LexerRule<T>.States 属性是词法分析器的 DFA 状态的列表,列表的每一项都是一个 StateData 结构,包含相应 DFA 状态的转移和对应的终结符索引。这个列表中实际上包含 ContextCount×2 个 DFA,这些 DFA 的首节点索引是从 0 到 ContextCount×2-1,其中每个上下文对应 2 个 DFA,前一个 DFA 对应于当前上下文中的所有非行首规则,用于从非行首位置进行匹配;后一个 DFA 对应于当前上下文中的所有规则,用于从行首位置进行匹配。索引为 i 的上下文,对应的两个 DFA 就是 i*2 和 i*2+1。关于行首和非行首规则的详细信息,请参考《C# 词法分析器(四)构造 NFA》的第四节“多条正则表达式、限定符和上下文”。
以上就是词法分析器所需的信息,只要获取了这些信息,就可以根据需要,构造自己的词法分析器。详细的实现,请参考《C# 词法分析器(六)构造词法分析器》中提供的算法,甚至可以将数据写入 .cs 文件中(甚至可以使用其它语言实现,因为数据本身是不影响实现的),实现词法分析器的生成(虽然现在我还仍未实现这点)。
以上的数据,全部是以比较容易理解的形式存储的,未进行压缩,所以可能会占用比较多的空间。在具体的实现中,可以根据需要改变数据存储格式,或选用一些压缩算法(如使用四数组压缩 DFA 状态)。
作者:CYJB
出处:http://www.cnblogs.com/cyjb/
GitHub:https://github.com/CYJB/

