knn算法--数据归一化
一.什么是数据归一化?
机器学习模型被互联网行业广泛应用,如排序、推荐、反作弊、定位等。一般做机器学习应用的时候大部分时间是花费在特征处理上,其中很关键的一步就是对特征数据进行归一化,为什么要归一化呢?维基百科给出的解释:
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度。
在knn算法中主要是可以用来提高结果的准确度。
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
二.数据归一化的方法
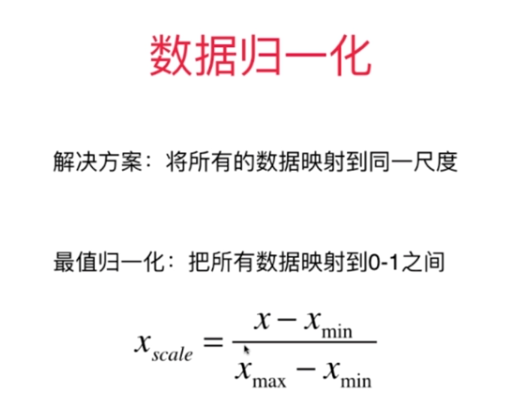
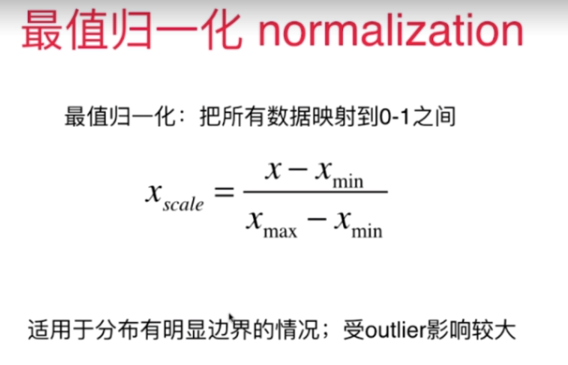
1.最值归一化(线性归一化)
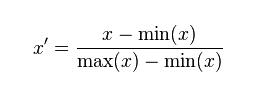
这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。(该方法使用于数据集存在明显的边界,有最大值和最小值的情况)
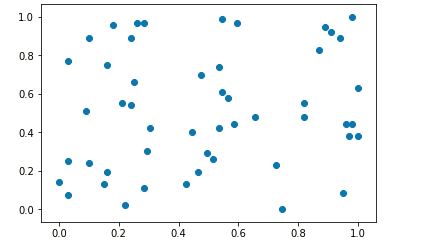
import numpy as np import matplotlib.pyplot as plt x = np.random.randint(0,100,size=100) x=(x-np.min(x))/(np.max(x)-np.min(x)) #数据归一化 #二维矩阵的归一化 x=np.random.randint(0,100,(50,2)) x=np.array(x,dtype='float') #转换成浮点型 #对二维数组中的每一列进行数据归一化 x[:,0]=(x[:,0]-np.min(x[:,0]))/(np.max(x[:,0])-np.min(x[:,0])) x[:,1]=(x[:,1]-np.min(x[:,1]))/(np.max(x[:,1])-np.min(x[:,1])) #数据可视化过程 plt.scatter(x[:,0],x[:,1]) plt.show()
如下图:
#第一列的均值和方差 np.mean(x[:,0]) #0.49151515151515146 np.std(x[:,0]) #0.3178761398431847 #第二列的均值和差 np.mean(x[:,1]) #0.5156521739130435 np.std(x[:,1]) #0.3018935202062692
2.均值方差归一化(标准差标准化)


#均值方差归一化 x2 = np.random.randint(0,100,(50,2)) x2=np.array(x2,dtype=float) #对数组中的每一列进行数据归一化 x2[:,0]=(x2[:,0] - np.mean(x2[:,0])) / np.std(x2[:,0]) x2[:,1]=(x2[:,1] - np.mean(x2[:,1])) / np.std(x2[:,1]) #可视化过程 plt.scatter(x2[:,0],x2[:,1]) plt.show()
如下图:
#第一列的均值和方差 np.mean(x2[:,0]) #-5.384581669432009e-17 np.std(x2[:,0]) #1.0 #第二列的均值和差 np.mean(x2[:,1]) #-1.1102230246251565e-16 np.std(x2[:,1]) #1.0
三.如何对测试数据集进行数据归一化?
1.利用训练数据集的均值和方差

2.使用scikit_learn中Scaler来进行

3.Scaler的流程如下
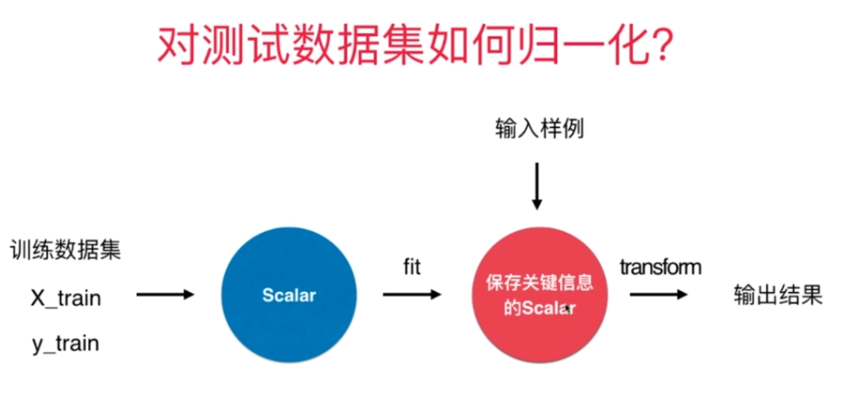
示例代码如下:
#scikit_learn中的Scalar import numpy as np from sklearn import datasets #以鸢尾花的数据集为示例 iris = datasets.load_iris() X=iris.data y=iris.target from sklearn.model_selection import train_test_split X_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=666) from sklearn.preprocessing import StandardScaler #sklearn中的相应的类 standardScaler = StandardScaler() #实例化这样的一个类 standardScaler.fit(X_train) #求出相应的均值和方差(根据训练集) standardScaler.mean_ # 均值 array([5.83416667, 3.0825 , 3.70916667, 1.16916667]) standardScaler.scale_ #标准差array([0.81019502, 0.44076874, 1.76295187, 0.75429833]) X_train=standardScaler.transform(X_train) #根据fit计算出来的值来进行相应的数据归一化 x_test_transform=standardScaler.transform(x_test) #对测试集也使用同样的方法进行相应的数据归一化 from sklearn.neighbors import KNeighborsClassifier knn_clf=KNeighborsClassifier(n_neighbors=3) knn_clf.fit(X_train,y_train) ''' KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=3, p=2, weights='uniform') ''' knn_clf.score(x_test_transform,y_test) # 数据归一化后的精确度1.0 #注意:算精确度的时候,测试集的数据也一定要使用数据归一化后的结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号