
word2vec 的理解
1.CBOW 模型
CBOW模型包括输入层、投影层、输出层。模型是根据上下文来预测当前词,由输入层到投影层的示意图如下:
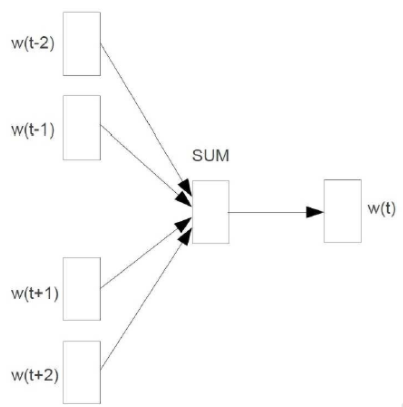
这里是对输入层的4个上下文词向量求和得到的当前词向量,实际应用中,上下文窗口大小可以设置。
输出层是一颗哈夫曼树,从向量W(t)到哈夫曼树的转化过程是这样的:以训练语料中出现的词当叶子结点,以各词在语料中出现的次数当权值来构造,这样不仅可以保证出现频率更高的词可以被更快地搜索到,而且为使用Hierarchical softmax铺平了道路。
对于词典中的任意词w,必然存在一条从根节点到这个词的路径,哈夫曼树是一颗二叉树,我们可以将根节点到叶子结点(词)的过程视为一个不断进行二分类(这里选择逻辑回归)的过程,那么每一次分类都会涉及到以一个概率选择一个分支,那么最后选择某个叶子结点(词)的概率就是从根节点到叶子结点过程中所有节点选择概率的连乘。表达式为: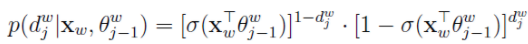
为什么要得到选择每个词对应的概率呢?因为这涉及到了我们的最优化方法。我们使用同神经概率语言模型相同的对数似然函数来优化参数,对数似然函数如下:
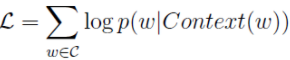
然后就可以使用随机梯度下降法来求解相关参数。
2.Skip-gram模型
Skip-gram模型已知的是当前词,需要对其上下文词汇进行预测,因此,其条件概率的形式为:
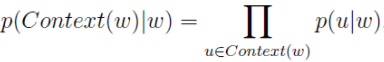
其中
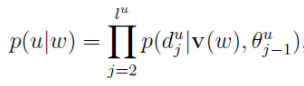
后面的过程与CBow模型类似。
以上内容若有不妥之处,还望批评指正,转载请注明出处!

