

OpenAI未至,Open-Sora再度升级!已支持生成16秒720p视频
Open-Sora 在开源社区悄悄更新了!现在单镜头支持长达 16 秒的视频生成,分辨率最高可达 720p,并且可以处理任何宽高比的文本到图像、文本到视频、图像到视频、视频到视频和无限长视频的生成需求。我们来试试效果。
生成个横屏圣诞雪景,发b站

再生成个竖屏,发抖音

还能生成单镜头16秒的长视频,这下人人都能过把编剧瘾了

怎么玩?指路 GitHub:github.com/hpcaitech/Open-Sora
更酷的是,Open-Sora 最新版本依旧全部开源、诚意满满,仓库内包含最新的模型架构、最新的模型权重、多时间/分辨率/长宽比/帧率的训练流程、数据收集和预处理的完整流程、所有的训练细节、Demo 示例和详尽的上手教程。
一、技术报告全面解读
近日,Open-Sora 的作者团队在 GitHub 上正式发布了最新版本的技术报告[1],下面我们将通过技术报告对功能、架构、训练方式、数据收集、预处理等方面进行逐一解读。
1.1 最新功能概览
Open-Sora 本次更新主要包括以下几项关键特性:
- 支持长视频生成;
- 视频生成分辨率最高可达 720p;
- 单模型支持任何宽高比,不同分辨率和时长的文本到图像、文本到视频、图像到视频、视频到视频和无限长视频的生成需求;
- 提出了更稳定的模型架构设计,支持多时间/分辨率/长宽比/帧率训练;
- 开源了最新的自动数据处理全流程;
1.2 时空扩散模型
Open-Sora 本次升级对 1.0 版本中的 STDiT 架构进行了关键性改进,旨在提高模型的训练稳定性和整体性能。针对当前的序列预测任务,团队采纳了大型语言模型(LLM)的最佳实践,将时序注意力中的正弦波位置编码(sinusoidal positional encoding)替换为更加高效的旋转位置编码(RoPE embedding)。
此外,为了增强训练的稳定性,他们参考 SD3 模型架构,进一步引入了 QK 归一化技术,以增强半精度训练的稳定性。为了支持多分辨率、不同长宽比和帧率的训练需求,作者团队提出的 ST-DiT-2 架构能够自动缩放位置编码,并处理不同大小尺寸的输入。
1.3 多阶段训练
技术报告指出,Open-Sora 采用了一种多阶段训练方法,每个阶段都会基于前一个阶段的权重继续训练。相较于单一阶段训练,这种多阶段训练通过分步骤引入数据,更高效地实现了高质量视频生成的目标。
- 初始阶段:大部分视频采用 144p 分辨率,同时与图片和 240p、480p 的视频进行混训,训练持续约 1 周,总步长 81k。
- 第二阶段:将大部分视频数据分辨率提升至 240p 和 480p,训练时长为 1 天,步长达到 22k。
- 第三阶段:进一步增强至 480p 和 720p,训练时长为 1 天,完成了 4k 步长的训练。整个多阶段训练流程在约 9 天内完成。
与 1.0 相比,最新版本在多个维度提升了视频生成的质量。
1.4 统一的图生视频/视频生视频框架
作者团队表示,基于 Transformer 的特性,可以轻松扩展 DiT 架构以支持图像到图像以及视频到视频的任务。他们提出了一种掩码策略来支持图像和视频的条件化处理。通过设置不同的掩码,可以支持各种生成任务,包括:图生视频,循环视频,视频延展,视频自回归生成,视频衔接,视频编辑,插帧等。
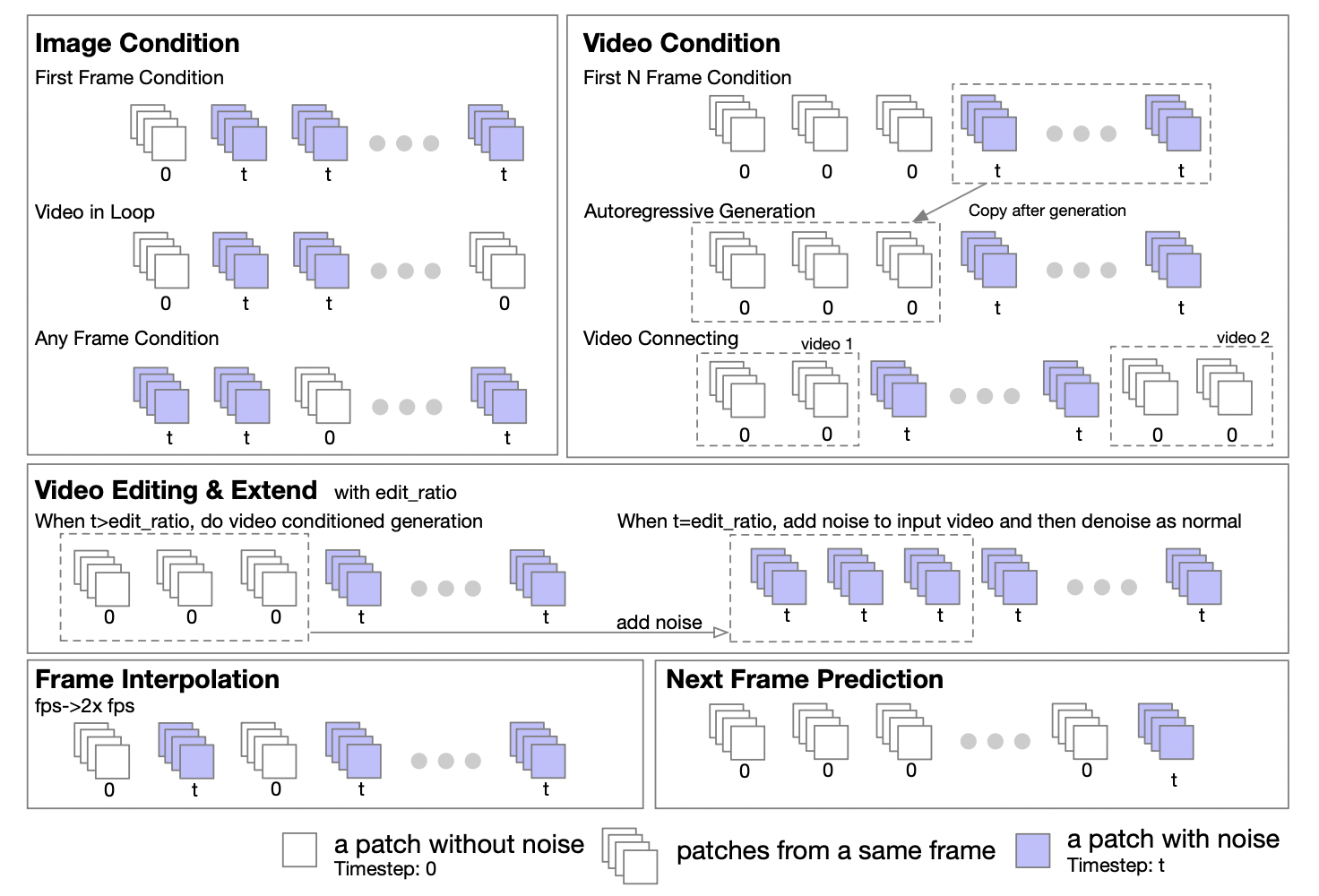
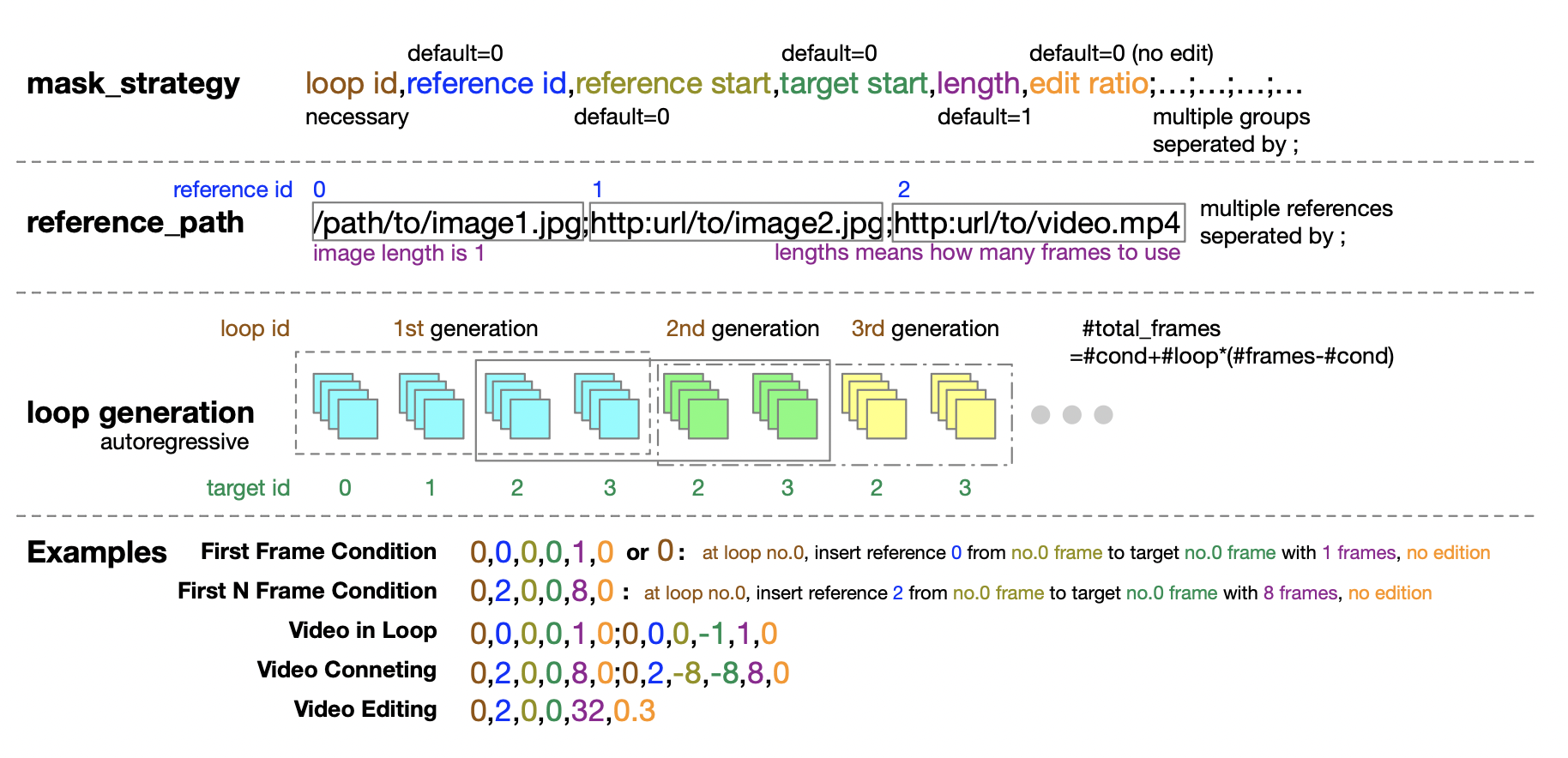
受到 UL2[2] 方法的启发,他们在模型训练阶段引入了一种随机掩码策略。具体而言,就是在训练过程中以随机方式选择并取消掩码的帧,包括但不限于取消掩码第一帧、前 k 帧、后 k 帧、任意 k 帧等。报告中还透露,基于 Open-Sora 1.0 的实验,应用 50% 的概率应用掩码策略时,只需少量步数模型能够更好地学会处理图像条件化。在最新版的 Open-Sora 中,他们采用了从头开始使用掩码策略进行预训练的方法。
此外,作者团队还贴心地为推理阶段提供了掩码策略配置的详细指南,五个数字的元组形式在定义掩码策略时提供了极大的灵活性和控制力。
1.5 支持多时间/分辨率/长宽比/帧率训练
OpenAI Sora 的技术报告[3]指出,使用原始视频的分辨率、长宽比和长度进行训练可以增加采样灵活性,改善帧和构图。对此,作者团队提出了分桶的策略。
具体怎么实现呢?通过深入阅读作者发布的技术报告,我们了解到,所谓的桶,是(分辨率、帧数、长宽比)的三元组。他们为不同分辨率的视频预定义了一系列宽高比,以覆盖大多数常见的视频宽高比类型。在每个训练周期 epoch 开始之前,他们会对数据集进行重新洗牌,并将样本根据其特征分配到相应的桶中。具体来说,他们会将每个样本放入一个分辨率和帧长度均小于或等于该视频特性的桶中。
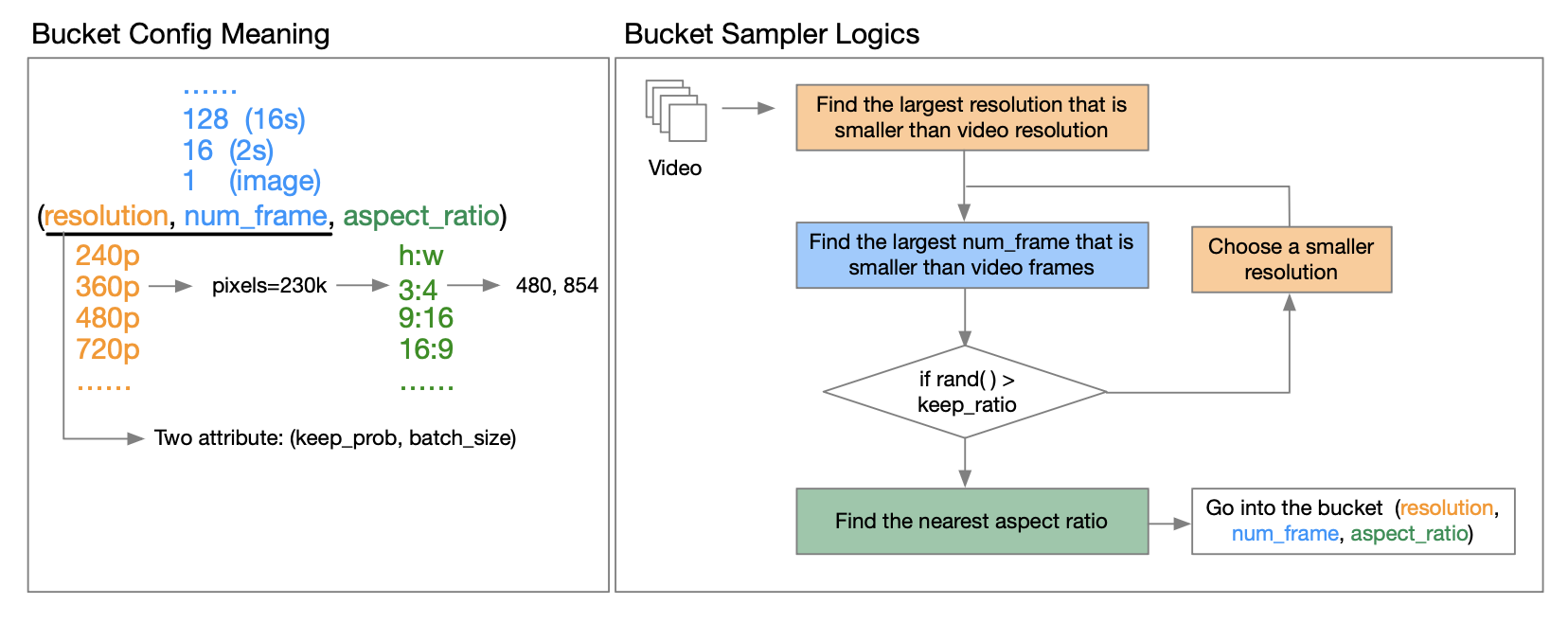
为了降低计算资源的要求,他们为每个 keep_prob 和 batch_size 引入两个属性(分辨率、帧数),以减少计算成本并实现多阶段训练。这样就可以控制不同桶中的样本数量,并通过为每个桶搜索良好的批大小来平衡 GPU 负载。技术报告中对此进行了详尽的阐述,感兴趣的小伙伴,可以阅读 GitHub 上的技术报告来获取更多的信息。
GitHub 地址:github.com/hpcaitech/Open-Sora
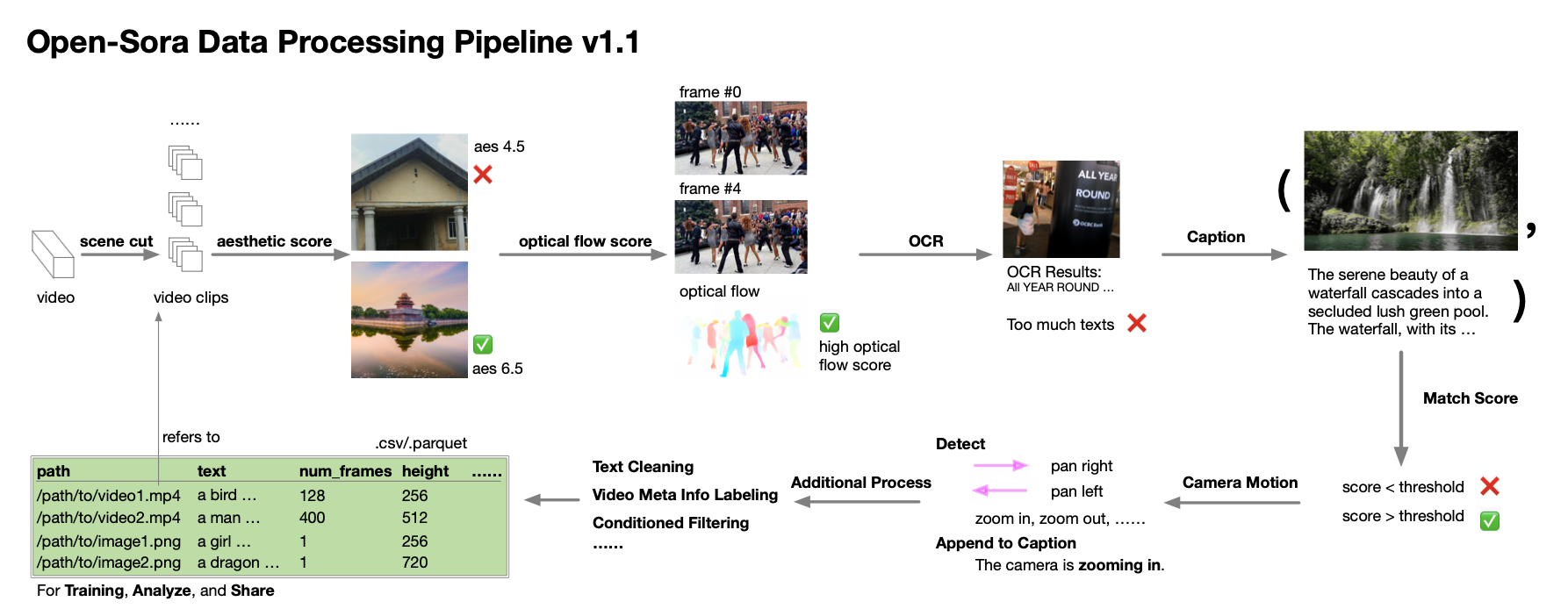
1.6 数据收集和预处理流程
作者团队甚至对数据收集与处理环节也提供了详尽的指南。根据技术报告中的阐述,在 Open-Sora 1.0 的开发过程中,他们意识到数据的数量和质量对于培育一个高效能模型极为关键,因此他们致力于扩充和优化数据集。他们建立了一个自动化的数据处理流程,该流程遵循奇异值分解(SVD)原则,涵盖了场景分割、字幕处理、多样化评分与筛选,以及数据集的管理系统和规范。
同样,他们也将数据处理的相关脚本无私地分享至开源社区。对此感兴趣的开发者现在可以利用这些资源,结合技术报告和代码,来高效地处理和优化自己的数据集。
二、性能全方位评测
说了这么多技术细节,下面让我们一同欣赏下 Open-Sora 最新的视频生成效果,放松一下。
Open-Sora 本次更新最令人瞩目的亮点在于,它能够将你脑中的景象,通过文字描述的方式,捕捉并转化为动人的动态视频。那些在思维中一闪而过的画面和想象,现在得以被永久地记录下来,并与他人分享。在这里,笔者尝试了几种不同的 prompt,作为抛砖引玉。
2.1 风景
比如,笔者尝试生成了一个在冬季森林里游览的视频。雪刚下不久,松树上挂满了皑皑白雪,暗色的松针和洁白的雪花错落有致,层次分明。

又或者,在一个静谧夜晚中,你身处像无数童话里描绘过黑暗的森林,幽深的湖水在漫天璀璨的星河的照耀下波光粼粼。

在空中俯瞰繁华岛屿的夜景则更是美丽,温暖的黄色灯光和丝带一样的蓝色海水让人一下子就被拉入度假的悠闲时光里。

城市里的车水马龙,深夜依然亮着灯的高楼大厦和街边小店,又有另一番风味。

2.2 自然生物
除了风景之外,Open-Sora 还能还原各种自然生物。无论是红艳艳的小花,

还是慢悠悠扭头的变色龙,Open-Sora 都能生成较为真实的视频。

2.3 不同分辨率/长宽比/时长
笔者还尝试了多种 prompt 测试,还提供了许多生成的视频供大家参考,包括不同内容、不同分辨率、不同长宽比、不同时长。



笔者还发现,仅需一个简洁的指令,Open-Sora 便能生成多分辨率的视频短片,彻底打破创作限制。




2.4 图生视频
我们还可以喂给 Open-Sora 一张静态图片让它生成短片。

Open-Sora 还可以将两个静态图巧妙地连接起来,轻触下方视频,将带您体验从下午至黄昏的光影变幻,每一帧都是时间的诗篇。

2.5 视频编辑
再比如说我们要对原有视频进行编辑,仅需一个简单的指令,原本明媚的森林便迎来了一场鹅毛大雪。


2.6 生成高清图片
我们也能让 Open-Sora 生成高清的图片:

值得注意的是,Open-Sora 的模型权重已经完全免费公开在他们的开源社区上。由于他们还支持视频拼接功能,这意味着你完全有机会免费创作出一段带有故事性的小短片,将你的创意带入现实。
三、当前局限与未来计划
尽管 Open-Sora 在复现类 Sora 文生视频模型的工作方面取得了不错的进展,但作者团队也谦逊地指出,当前生成的视频在多个方面仍有待改进,包括生成过程中的噪声问题、时间一致性的缺失、人物生成质量不佳以及美学评分较低。
对于这些挑战,作者团队表示:他们将在下一版本的开发中优先解决,以期望达到更高的视频生成标准,感兴趣的朋友不妨持续关注。我们期待 Open-Sora 社区带给我们的下一次惊喜。
GitHub 地址:github.com/hpcaitech/Open-Sora
参考文献:
[1] https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
[2] Tay, Yi, et al. "Ul2: Unifying language learning paradigms." arXiv preprint arXiv:2205.05131 (2022).
[3] https://openai.com/research/video-generation-models-as-world-simulators
作者:削微寒
扫描左侧的二维码可以联系到我

本作品采用署名-非商业性使用-禁止演绎 4.0 国际 进行许可。

