自建基于Hadoop+Hive+Spark的离线数仓总结
写在前面
1. 什么是离线数仓,为什么做离线数仓?为什么mysql不能作为数仓的存储?
首先我们要知道我们想做什么,我们的目的不是做业务系统的OLTP工作。而是要对海量的数据做OLAP操作。海量数据的分布式存储mysql也许可以满足,但分布式计算,mysql便无法胜任。而hadoop的hdfs与mr则应运而生。
为了开发人员的开发效率,又诞生了hive框架,通过sql的方式,解析之后经过mr自动计算。
mr的落盘io的问题进而又诞生了spark计算引擎。hive on spark的操作把mr取代,有向无环图DAG的执行计划及内存计算方式让分布式计算得到提高。
sparkSql直接取代了sql的解析,只用了hive的元数据。
回过头来,spark依赖hadoop的yarn资源调度,连接mysql做分布式计算?想想可以,一般不这么做哈哈。
OLTP(Online transaction processing):在线/联机事务处理。典型的OLTP类操作都比较简单,主要是对数据库中的数据进行增删改查,操作主体一般是产品的用户。
OLAP(Online analytical processing):指联机分析处理。通过分析数据库中的数据来得出一些结论性的东西。比如给老总们看的报表,用于进行市场开拓的用户行为统计,不同维度的汇总分析结果等等。操作主体一般是运营、销售和市场等团队人员。
2. 在离线数仓中,什么是增量同步什么是离线同步?
增量同步:大表、小更新。一般用于事实表。实时同步。
离线同步:小表、大更新。一般用于维度表。每日定时同步。
在离线数仓中,hdfs到hive的ods层全部是定时操作。所以在整体上看离线数仓的所有数据都是n+1的离线同步。
整体架构图
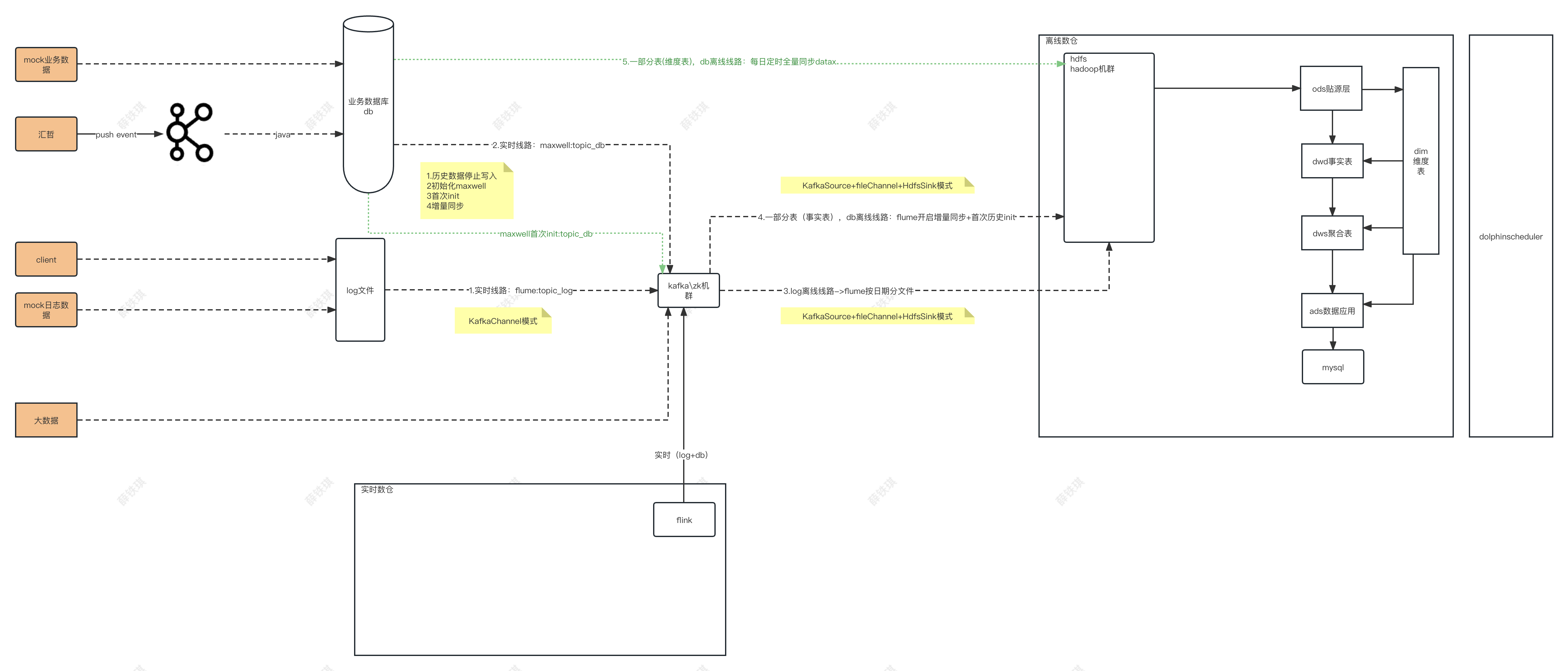
服务台账
| hadoop1 | hadoop2 | hadoop3 | |
| 172.23.112.160 | 172.23.112.161 | 172.23.112.162 | |
| HDFS | NameNode DataNode HDFS NameNode HTTP UI:9870 HDFS DataNode HTTP UI:9864 |
DataNode | SecondaryNameNode DataNode |
| http://hadoop1:9870/dfshealth.html#tab-overview | http://hadoop3:9868/status.html | ||
| YARN | NodeManager 8042端口 |
ResourceManager NodeManager |
NodeManager |
| http://hadoop2:8088/cluster | |||
| JOBHISTORY | historyserver | ||
| http://hadoop1:19888/jobhistory | |||
| 日志mock | user_action.jar | user_action.jar | |
| flume-job实时toKfka | Application | Application | |
| flume-job实时toHdfs | Application-log | ||
| 业务mock | business_db.jar | ||
| maxwell实时任务toKafka | Maxwell | ||
| maxwell离线增量+flume-job实时 | Application-db | ||
| dataX离线全量 | 每日定时提交任务 | ||
| hive | metaStoreServer hive2Server | metaStoreServer hive2Server | metaStoreServer hive2Server |
| spark/sparkSql | 4040端口 | ||
| dolphinscheduler | MasterServer | ||
| WorkerServer | WorkerServer | WorkerServer | |
| LoggerServer | LoggerServer | LoggerServer | |
| AlertServer | |||
| ApiApplicationServer | |||
| http://hadoop1:12345/dolphinscheduler |
简化数据流图 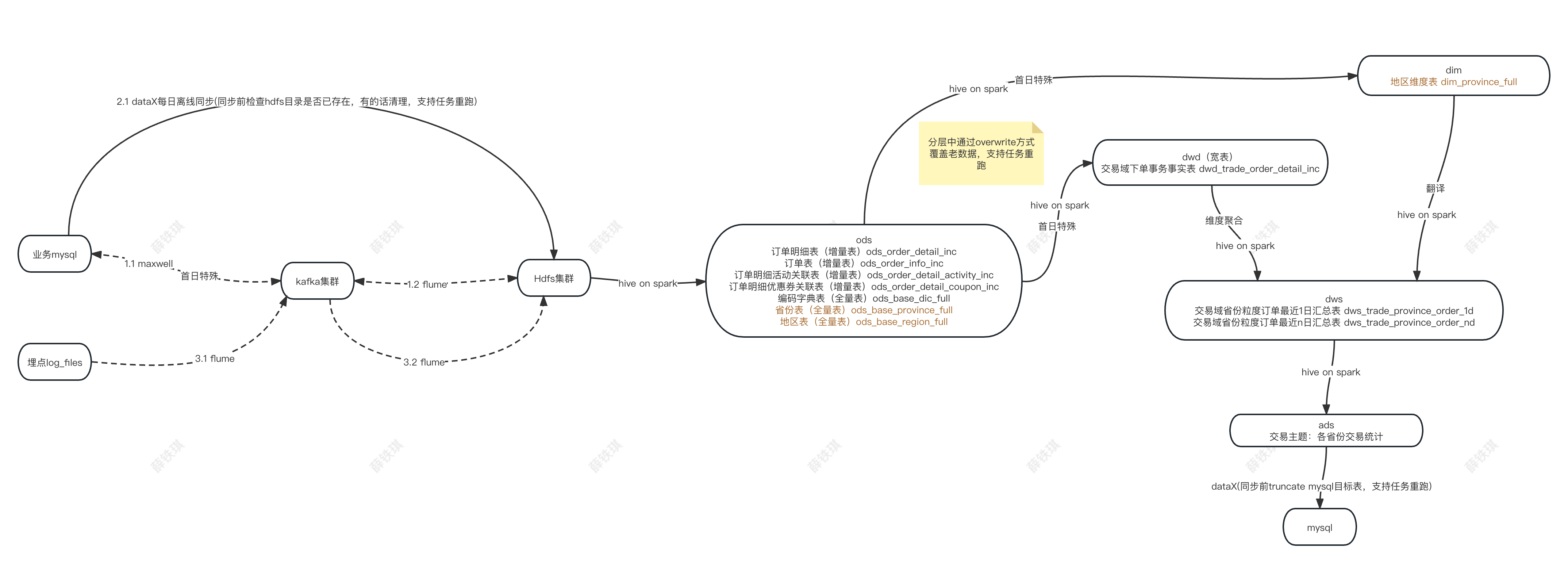
按步骤解析
图中1.1 mysql->maxwell->kafka:
采用maxwell中间件监听业务mysql的binlog日志(row模式),实时同步增删改的json格式记录到kafka的指定topic主题。实现增量同步。
maxwell配置不在赘述,需要做好maxwell库的初始化(核心主要用于存放binlog日志监听的步数),输入为开启binlog的msql库,输出为kafka集群。



producer=kafka kafka.bootstrap.servers=kafka1:9092,kafka2:9092 #kafka topic配置 kafka_topic=topic_db # mysql login info host=hadoop1 user=root password=root123456 jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
图中1.2 kafka->flume->hdfs:
由flume组件将监听的kafka主题数据传递至hdfs指定目录。
echo " --------启动 hadoop104 业务数据flume-------" ssh hadoop3 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
a1.sources = r1 a1.channels = c1 a1.sinks = k1 a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092 a1.sources.r1.kafka.topics = topic_db a1.sources.r1.kafka.consumer.group.id = flume a1.sources.r1.setTopicHeader = true a1.sources.r1.topicHeader = topic a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.zfyz.flume.interceptor.TimeStampAndTableNameInterceptor$Builder a1.channels.c1.type = file a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2 a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/ a1.channels.c1.maxFileSize = 2146435071 a1.channels.c1.capacity = 1000000 a1.channels.c1.keep-alive = 6 ## sink1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = db a1.sinks.k1.hdfs.round = false a1.sinks.k1.hdfs.rollInterval = 10 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = gzip ## 拼装 a1.sources.r1.channels = c1 a1.sinks.k1.channel= c1
hdfs的输出做了gzip压缩以及路径的按天拆分/%Y-%m-%d
图中2.1 mysql->dataX->hdfs:
需要离线同步的部分表由dataX组件一次性读取全表数据text格式同步到hdfs集群。实现离线同步。
DATAX_HOME=/opt/module/datax # 如果传入日期则do_date等于传入的日期,否则等于前一天日期 if [ -n "$2" ] ;then do_date=$2 else do_date=`date -d "-1 day" +%F` fi #处理目标路径,此处的处理逻辑是,如果目标路径不存在,则创建;若存在,则清空,目的是保证同步任务可重复执行 handle_targetdir() { hadoop fs -test -e $1 if [[ $? -eq 1 ]]; then echo "路径$1不存在,正在创建......" hadoop fs -mkdir -p $1 else echo "路径$1已经存在" fs_count=$(hadoop fs -count $1) content_size=$(echo $fs_count | awk '{print $3}') if [[ $content_size -eq 0 ]]; then echo "路径$1为空" else echo "路径$1不为空,正在清空......" hadoop fs -rm -r -f $1/* fi fi } #数据同步 import_data() { datax_config=$1 target_dir=$2 handle_targetdir $target_dir python $DATAX_HOME/bin/datax.py -p"-Dtargetdir=$target_dir" $datax_config } #举个例子 import_data /opt/module/datax/job/import/gmall.activity_info.json /origin_data/gmall/db/activity_info_full/$do_date
gmall.activity_info.json
{ "job":{ "content":[ { "writer":{ "parameter":{ "writeMode":"append", "fieldDelimiter":"\t", "column":[ { "type":"bigint", "name":"id" }, { "type":"string", "name":"activity_name" }, { "type":"string", "name":"activity_type" }, { "type":"string", "name":"activity_desc" }, { "type":"string", "name":"start_time" }, { "type":"string", "name":"end_time" }, { "type":"string", "name":"create_time" } ], "path":"${targetdir}", "fileType":"text", "defaultFS":"hdfs://hadoop1:8020", "compress":"gzip", "fileName":"activity_info" }, "name":"hdfswriter" }, "reader":{ "parameter":{ "username":"root", "column":[ "id", "activity_name", "activity_type", "activity_desc", "start_time", "end_time", "create_time" ], "connection":[ { "table":[ "activity_info" ], "jdbcUrl":[ "jdbc:mysql://hadoop1:3306/gmall" ] } ], "password":"root123456", "splitPk":"" }, "name":"mysqlreader" } } ], "setting":{ "speed":{ "channel":3 }, "errorLimit":{ "record":0, "percentage":0.02 } } } }
View Code
dataX的数据同步config可以由pathon脚本一次性生成
gen_import_config.py
# ecoding=utf-8 import json import getopt import os import sys import MySQLdb #MySQL相关配置,需根据实际情况作出修改 mysql_host = "hadoop1" mysql_port = "3306" mysql_user = "root" mysql_passwd = "root123456" #HDFS NameNode相关配置,需根据实际情况作出修改 hdfs_nn_host = "hadoop1" hdfs_nn_port = "8020" #生成配置文件的目标路径,可根据实际情况作出修改 output_path = "/opt/module/datax/job/import" def get_connection(): return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd) def get_mysql_meta(database, table): connection = get_connection() cursor = connection.cursor() sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION" cursor.execute(sql, [database, table]) fetchall = cursor.fetchall() cursor.close() connection.close() return fetchall def get_mysql_columns(database, table): return map(lambda x: x[0], get_mysql_meta(database, table)) def get_hive_columns(database, table): def type_mapping(mysql_type): mappings = { "bigint": "bigint", "int": "bigint", "smallint": "bigint", "tinyint": "bigint", "decimal": "string", "double": "double", "float": "float", "binary": "string", "char": "string", "varchar": "string", "datetime": "string", "time": "string", "timestamp": "string", "date": "string", "text": "string" } return mappings[mysql_type] meta = get_mysql_meta(database, table) return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta) def generate_json(source_database, source_table): job = { "job": { "setting": { "speed": { "channel": 3 }, "errorLimit": { "record": 0, "percentage": 0.02 } }, "content": [{ "reader": { "name": "mysqlreader", "parameter": { "username": mysql_user, "password": mysql_passwd, "column": get_mysql_columns(source_database, source_table), "splitPk": "", "connection": [{ "table": [source_table], "jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database] }] } }, "writer": { "name": "hdfswriter", "parameter": { "defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port, "fileType": "text", "path": "${targetdir}", "fileName": source_table, "column": get_hive_columns(source_database, source_table), "writeMode": "append", "fieldDelimiter": "\t", "compress": "gzip" } } }] } } if not os.path.exists(output_path): os.makedirs(output_path) with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f: json.dump(job, f) def main(args): source_database = "" source_table = "" options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl=']) for opt_name, opt_value in options: if opt_name in ('-d', '--sourcedb'): source_database = opt_value if opt_name in ('-t', '--sourcetbl'): source_table = opt_value generate_json(source_database, source_table) if __name__ == '__main__': main(sys.argv[1:])
图中3.1 logFile->flume->kafka:
由flume组件监听对用的埋点日志目录,实时将json格式的日志数据传递至kafka集群的主题topic。实现增量同步。
echo " --------启动 $i 采集flume-------" ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
#定义组件 a1.sources = r1 a1.channels = c1 #配置source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.* a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.zfyz.flume.interceptor.ETLInterceptor$Builder #配置channel a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092 a1.channels.c1.kafka.topic = topic_log a1.channels.c1.parseAsFlumeEvent = false #组装 a1.sources.r1.channels = c1
kafkaChannel模式不需要指定sink
图中3.2 kafka->flume->hdfs:
由flume组件将监听的kafka主题数据传递至hdfs指定目录。
echo " --------启动 hadoop104 日志数据flume-------" ssh hadoop3 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
#定义组件 a1.sources=r1 a1.channels=c1 a1.sinks=k1 #配置source1 a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092 a1.sources.r1.kafka.topics=topic_log a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.zfyz.flume.interceptor.TimeStampInterceptor$Builder #配置channel a1.channels.c1.type = file a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1 a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1 a1.channels.c1.maxFileSize = 2146435071 a1.channels.c1.capacity = 1000000 a1.channels.c1.keep-alive = 6 #配置sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = log a1.sinks.k1.hdfs.round = false a1.sinks.k1.hdfs.rollInterval = 10 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 #控制输出文件类型 a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = gzip #组装 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
同样是做了gzip压缩和日期的切换
Hive On Spark的离线数仓分层
正常的数仓分层开发是由下而上的,即由产品提出报表需求,逐层分析拆解得出事实表和聚合表。而为了方便理解,以小见大。我们从ads层出发倒推到ods层。如下
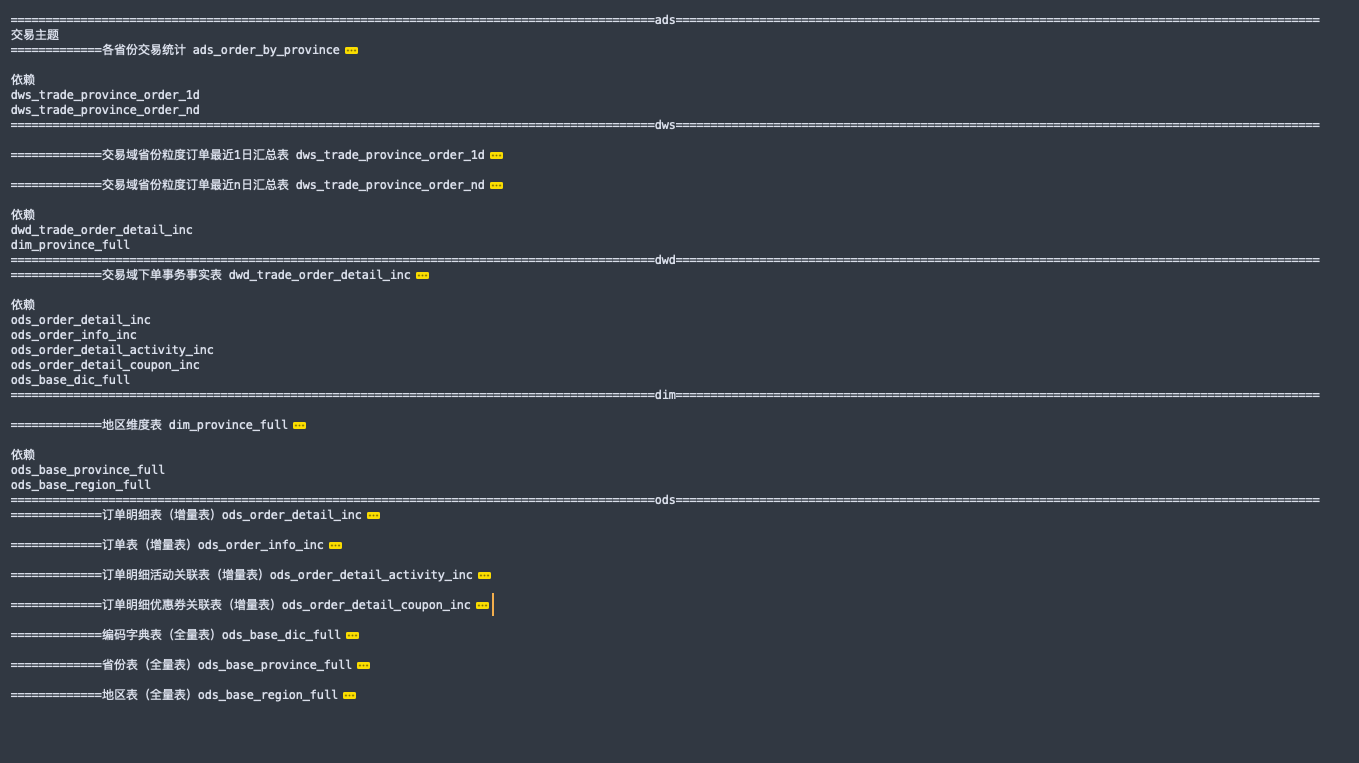
建标及每日装载语句
============================================================================================ads============================================================================================ 交易主题 =============各省份交易统计 ads_order_by_province 建表语句 DROP TABLE IF EXISTS ads_order_by_province; CREATE EXTERNAL TABLE ads_order_by_province ( `dt` STRING COMMENT '统计日期', `recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天', `province_id` STRING COMMENT '省份ID', `province_name` STRING COMMENT '省份名称', `area_code` STRING COMMENT '地区编码', `iso_code` STRING COMMENT '国际标准地区编码', `iso_code_3166_2` STRING COMMENT '国际标准地区编码', `order_count` BIGINT COMMENT '订单数', `order_total_amount` DECIMAL(16, 2) COMMENT '订单金额' ) COMMENT '各地区订单统计' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/warehouse/gmall/ads/ads_order_by_province/'; 数据装载 insert overwrite table ads_order_by_province select * from ads_order_by_province union select '2020-06-14' dt, 1 recent_days, province_id, province_name, area_code, iso_code, iso_3166_2, order_count_1d, order_total_amount_1d from dws_trade_province_order_1d where dt='2020-06-14' union select '2020-06-14' dt, recent_days, province_id, province_name, area_code, iso_code, iso_3166_2, sum(order_count), sum(order_total_amount) from ( select recent_days, province_id, province_name, area_code, iso_code, iso_3166_2, case recent_days when 7 then order_count_7d when 30 then order_count_30d end order_count, case recent_days when 7 then order_total_amount_7d when 30 then order_total_amount_30d end order_total_amount from dws_trade_province_order_nd lateral view explode(array(7,30)) tmp as recent_days where dt='2020-06-14' )t1 group by recent_days,province_id,province_name,area_code,iso_code,iso_3166_2; 依赖 dws_trade_province_order_1d dws_trade_province_order_nd ============================================================================================dws============================================================================================ =============交易域省份粒度订单最近1日汇总表 dws_trade_province_order_1d 建表语句 DROP TABLE IF EXISTS dws_trade_province_order_1d; CREATE EXTERNAL TABLE dws_trade_province_order_1d ( `province_id` STRING COMMENT '用户id', `province_name` STRING COMMENT '省份名称', `area_code` STRING COMMENT '地区编码', `iso_code` STRING COMMENT '旧版ISO-3166-2编码', `iso_3166_2` STRING COMMENT '新版版ISO-3166-2编码', `order_count_1d` BIGINT COMMENT '最近1日下单次数', `order_original_amount_1d` DECIMAL(16, 2) COMMENT '最近1日下单原始金额', `activity_reduce_amount_1d` DECIMAL(16, 2) COMMENT '最近1日下单活动优惠金额', `coupon_reduce_amount_1d` DECIMAL(16, 2) COMMENT '最近1日下单优惠券优惠金额', `order_total_amount_1d` DECIMAL(16, 2) COMMENT '最近1日下单最终金额' ) COMMENT '交易域省份粒度订单最近1日汇总事实表' PARTITIONED BY (`dt` STRING) STORED AS ORC LOCATION '/warehouse/gmall/dws/dws_trade_province_order_1d' TBLPROPERTIES ('orc.compress' = 'snappy'); 每日装载 insert overwrite table dws_trade_province_order_1d partition(dt='2020-06-15') select province_id, province_name, area_code, iso_code, iso_3166_2, order_count_1d, order_original_amount_1d, activity_reduce_amount_1d, coupon_reduce_amount_1d, order_total_amount_1d from ( select province_id, count(distinct(order_id)) order_count_1d, sum(split_original_amount) order_original_amount_1d, sum(nvl(split_activity_amount,0)) activity_reduce_amount_1d, sum(nvl(split_coupon_amount,0)) coupon_reduce_amount_1d, sum(split_total_amount) order_total_amount_1d from dwd_trade_order_detail_inc where dt='2020-06-15' group by province_id )o left join ( select id, province_name, area_code, iso_code, iso_3166_2 from dim_province_full where dt='2020-06-15' )p on o.province_id=p.id; =============交易域省份粒度订单最近n日汇总表 dws_trade_province_order_nd 建表语句 DROP TABLE IF EXISTS dws_trade_province_order_nd; CREATE EXTERNAL TABLE dws_trade_province_order_nd ( `province_id` STRING COMMENT '用户id', `province_name` STRING COMMENT '省份名称', `area_code` STRING COMMENT '地区编码', `iso_code` STRING COMMENT '旧版ISO-3166-2编码', `iso_3166_2` STRING COMMENT '新版版ISO-3166-2编码', `order_count_7d` BIGINT COMMENT '最近7日下单次数', `order_original_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单原始金额', `activity_reduce_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单活动优惠金额', `coupon_reduce_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单优惠券优惠金额', `order_total_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单最终金额', `order_count_30d` BIGINT COMMENT '最近30日下单次数', `order_original_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单原始金额', `activity_reduce_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单活动优惠金额', `coupon_reduce_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单优惠券优惠金额', `order_total_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单最终金额' ) COMMENT '交易域省份粒度订单最近n日汇总事实表' PARTITIONED BY (`dt` STRING) STORED AS ORC LOCATION '/warehouse/gmall/dws/dws_trade_province_order_nd' TBLPROPERTIES ('orc.compress' = 'snappy'); 数据装载 insert overwrite table dws_trade_province_order_nd partition(dt='2020-06-14') select province_id, province_name, area_code, iso_code, iso_3166_2, sum(if(dt>=date_add('2020-06-14',-6),order_count_1d,0)), sum(if(dt>=date_add('2020-06-14',-6),order_original_amount_1d,0)), sum(if(dt>=date_add('2020-06-14',-6),activity_reduce_amount_1d,0)), sum(if(dt>=date_add('2020-06-14',-6),coupon_reduce_amount_1d,0)), sum(if(dt>=date_add('2020-06-14',-6),order_total_amount_1d,0)), sum(order_count_1d), sum(order_original_amount_1d), sum(activity_reduce_amount_1d), sum(coupon_reduce_amount_1d), sum(order_total_amount_1d) from dws_trade_province_order_1d where dt>=date_add('2020-06-14',-29) and dt<='2020-06-14' group by province_id,province_name,area_code,iso_code,iso_3166_2; 依赖 dwd_trade_order_detail_inc dim_province_full ============================================================================================dwd============================================================================================ =============交易域下单事务事实表 dwd_trade_order_detail_inc 建表语句 DROP TABLE IF EXISTS dwd_trade_order_detail_inc; CREATE EXTERNAL TABLE dwd_trade_order_detail_inc ( `id` STRING COMMENT '编号', `order_id` STRING COMMENT '订单id', `user_id` STRING COMMENT '用户id', `sku_id` STRING COMMENT '商品id', `province_id` STRING COMMENT '省份id', `activity_id` STRING COMMENT '参与活动规则id', `activity_rule_id` STRING COMMENT '参与活动规则id', `coupon_id` STRING COMMENT '使用优惠券id', `date_id` STRING COMMENT '下单日期id', `create_time` STRING COMMENT '下单时间', `source_id` STRING COMMENT '来源编号', `source_type_code` STRING COMMENT '来源类型编码', `source_type_name` STRING COMMENT '来源类型名称', `sku_num` BIGINT COMMENT '商品数量', `split_original_amount` DECIMAL(16, 2) COMMENT '原始价格', `split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊', `split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊', `split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊' ) COMMENT '交易域下单明细事务事实表' PARTITIONED BY (`dt` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS ORC LOCATION '/warehouse/gmall/dwd/dwd_trade_order_detail_inc/' TBLPROPERTIES ('orc.compress' = 'snappy'); 每日装载 insert overwrite table dwd_trade_order_detail_inc partition (dt='2020-06-15') select od.id, order_id, user_id, sku_id, province_id, activity_id, activity_rule_id, coupon_id, date_id, create_time, source_id, source_type, dic_name, sku_num, split_original_amount, split_activity_amount, split_coupon_amount, split_total_amount from ( select data.id, data.order_id, data.sku_id, date_format(data.create_time, 'yyyy-MM-dd') date_id, data.create_time, data.source_id, data.source_type, data.sku_num, data.sku_num * data.order_price split_original_amount, data.split_total_amount, data.split_activity_amount, data.split_coupon_amount from ods_order_detail_inc where dt = '2020-06-15' and type = 'insert' ) od left join ( select data.id, data.user_id, data.province_id from ods_order_info_inc where dt = '2020-06-15' and type = 'insert' ) oi on od.order_id = oi.id left join ( select data.order_detail_id, data.activity_id, data.activity_rule_id from ods_order_detail_activity_inc where dt = '2020-06-15' and type = 'insert' ) act on od.id = act.order_detail_id left join ( select data.order_detail_id, data.coupon_id from ods_order_detail_coupon_inc where dt = '2020-06-15' and type = 'insert' ) cou on od.id = cou.order_detail_id left join ( select dic_code, dic_name from ods_base_dic_full where dt='2020-06-15' and parent_code='24' )dic on od.source_type=dic.dic_code; 依赖 ods_order_detail_inc ods_order_info_inc ods_order_detail_activity_inc ods_order_detail_coupon_inc ods_base_dic_full ============================================================================================dim============================================================================================ =============地区维度表 dim_province_full 建表语句 DROP TABLE IF EXISTS dim_province_full; CREATE EXTERNAL TABLE dim_province_full ( `id` STRING COMMENT 'id', `province_name` STRING COMMENT '省市名称', `area_code` STRING COMMENT '地区编码', `iso_code` STRING COMMENT '旧版ISO-3166-2编码,供可视化使用', `iso_3166_2` STRING COMMENT '新版IOS-3166-2编码,供可视化使用', `region_id` STRING COMMENT '地区id', `region_name` STRING COMMENT '地区名称' ) COMMENT '地区维度表' PARTITIONED BY (`dt` STRING) STORED AS ORC LOCATION '/warehouse/gmall/dim/dim_province_full/' TBLPROPERTIES ('orc.compress' = 'snappy'); 数据装载 insert overwrite table dim_province_full partition(dt='2020-06-14') select province.id, province.name, province.area_code, province.iso_code, province.iso_3166_2, region_id, region_name from ( select id, name, region_id, area_code, iso_code, iso_3166_2 from ods_base_province_full where dt='2020-06-14' )province left join ( select id, region_name from ods_base_region_full where dt='2020-06-14' )region on province.region_id=region.id; 依赖 ods_base_province_full ods_base_region_full ============================================================================================ods============================================================================================ =============订单明细表(增量表)ods_order_detail_inc DROP TABLE IF EXISTS ods_order_detail_inc; CREATE EXTERNAL TABLE ods_order_detail_inc ( `type` STRING COMMENT '变动类型', `ts` BIGINT COMMENT '变动时间', `data` STRUCT<id :STRING,order_id :STRING,sku_id :STRING,sku_name :STRING,img_url :STRING,order_price :DECIMAL(16, 2),sku_num :BIGINT,create_time :STRING,source_type :STRING,source_id :STRING,split_total_amount :DECIMAL(16, 2),split_activity_amount :DECIMAL(16, 2),split_coupon_amount :DECIMAL(16, 2)> COMMENT '数据', `old` MAP<STRING,STRING> COMMENT '旧值' ) COMMENT '订单明细表' PARTITIONED BY (`dt` STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' LOCATION '/warehouse/gmall/ods/ods_order_detail_inc/'; =============订单表(增量表)ods_order_info_inc DROP TABLE IF EXISTS ods_order_info_inc; CREATE EXTERNAL TABLE ods_order_info_inc ( `type` STRING COMMENT '变动类型', `ts` BIGINT COMMENT '变动时间', `data` STRUCT<id :STRING,consignee :STRING,consignee_tel :STRING,total_amount :DECIMAL(16, 2),order_status :STRING,user_id :STRING,payment_way :STRING,delivery_address :STRING,order_comment :STRING,out_trade_no :STRING,trade_body :STRING,create_time :STRING,operate_time :STRING,expire_time :STRING,process_status :STRING,tracking_no :STRING,parent_order_id :STRING,img_url :STRING,province_id :STRING,activity_reduce_amount :DECIMAL(16, 2),coupon_reduce_amount :DECIMAL(16, 2),original_total_amount :DECIMAL(16, 2),freight_fee :DECIMAL(16, 2),freight_fee_reduce :DECIMAL(16, 2),refundable_time :DECIMAL(16, 2)> COMMENT '数据', `old` MAP<STRING,STRING> COMMENT '旧值' ) COMMENT '订单表' PARTITIONED BY (`dt` STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' LOCATION '/warehouse/gmall/ods/ods_order_info_inc/'; =============订单明细活动关联表(增量表)ods_order_detail_activity_inc DROP TABLE IF EXISTS ods_order_detail_activity_inc; CREATE EXTERNAL TABLE ods_order_detail_activity_inc ( `type` STRING COMMENT '变动类型', `ts` BIGINT COMMENT '变动时间', `data` STRUCT<id :STRING,order_id :STRING,order_detail_id :STRING,activity_id :STRING,activity_rule_id :STRING,sku_id :STRING,create_time :STRING> COMMENT '数据', `old` MAP<STRING,STRING> COMMENT '旧值' ) COMMENT '订单明细活动关联表' PARTITIONED BY (`dt` STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' LOCATION '/warehouse/gmall/ods/ods_order_detail_activity_inc/'; =============订单明细优惠券关联表(增量表)ods_order_detail_coupon_inc DROP TABLE IF EXISTS ods_order_detail_coupon_inc; CREATE EXTERNAL TABLE ods_order_detail_coupon_inc ( `type` STRING COMMENT '变动类型', `ts` BIGINT COMMENT '变动时间', `data` STRUCT<id :STRING,order_id :STRING,order_detail_id :STRING,coupon_id :STRING,coupon_use_id :STRING,sku_id :STRING,create_time :STRING> COMMENT '数据', `old` MAP<STRING,STRING> COMMENT '旧值' ) COMMENT '订单明细优惠券关联表' PARTITIONED BY (`dt` STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' LOCATION '/warehouse/gmall/ods/ods_order_detail_coupon_inc/'; =============编码字典表(全量表)ods_base_dic_full DROP TABLE IF EXISTS ods_base_dic_full; CREATE EXTERNAL TABLE ods_base_dic_full ( `dic_code` STRING COMMENT '编号', `dic_name` STRING COMMENT '编码名称', `parent_code` STRING COMMENT '父编号', `create_time` STRING COMMENT '创建日期', `operate_time` STRING COMMENT '修改日期' ) COMMENT '编码字典表' PARTITIONED BY (`dt` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' NULL DEFINED AS '' LOCATION '/warehouse/gmall/ods/ods_base_dic_full/'; =============省份表(全量表)ods_base_province_full DROP TABLE IF EXISTS ods_base_province_full; CREATE EXTERNAL TABLE ods_base_province_full ( `id` STRING COMMENT '编号', `name` STRING COMMENT '省份名称', `region_id` STRING COMMENT '地区ID', `area_code` STRING COMMENT '地区编码', `iso_code` STRING COMMENT '旧版ISO-3166-2编码,供可视化使用', `iso_3166_2` STRING COMMENT '新版IOS-3166-2编码,供可视化使用' ) COMMENT '省份表' PARTITIONED BY (`dt` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' NULL DEFINED AS '' LOCATION '/warehouse/gmall/ods/ods_base_province_full/'; =============地区表(全量表)ods_base_region_full DROP TABLE IF EXISTS ods_base_region_full; CREATE EXTERNAL TABLE ods_base_region_full ( `id` STRING COMMENT '编号', `region_name` STRING COMMENT '地区名称' ) COMMENT '地区表' PARTITIONED BY (`dt` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' NULL DEFINED AS '' LOCATION '/warehouse/gmall/ods/ods_base_region_full/';
可见我们将ods层作为贴源层,尽可能的保留原始数据;来自dataX的text格式数据以及flume来的json格式;
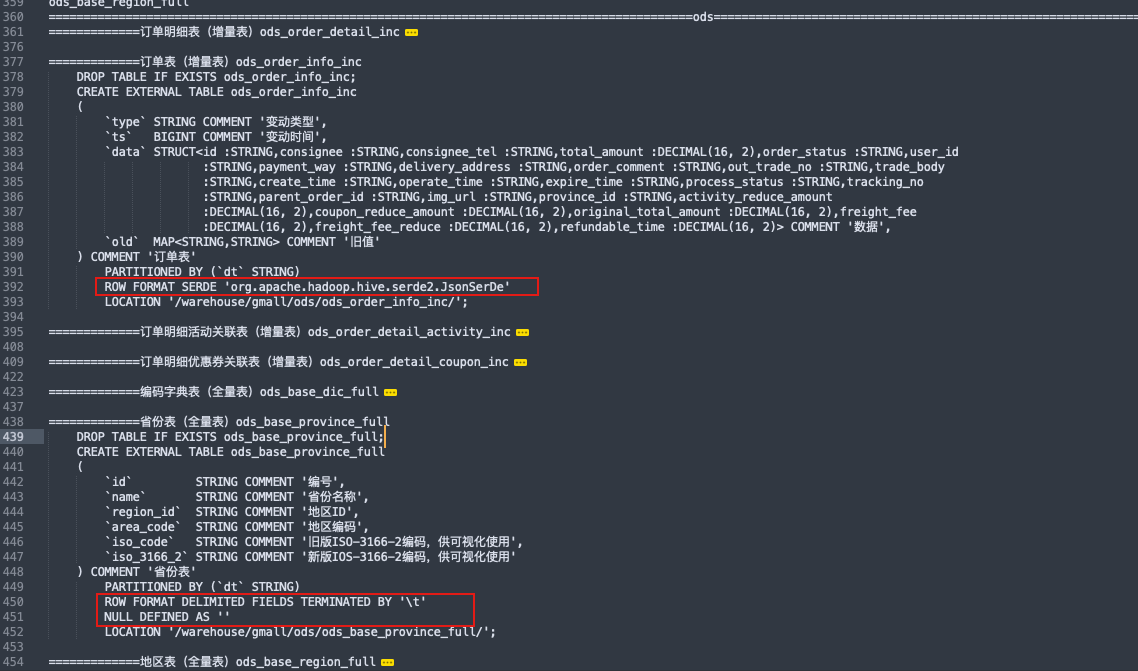
从ods层中抽取dim维度表供后续dws层使用;注意维度表的压缩排序;
TEXTFILE 和 SEQUENCEFILE 的存储格式都是基于行存储的;
ORC 和 PARQUET 是基于列式存储的。
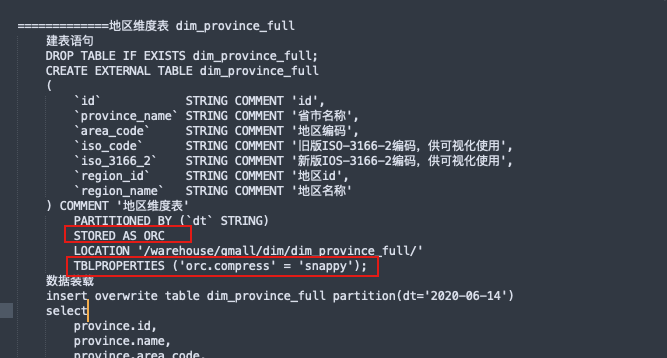
从ods层中抽取事实表及多张关联表组合为dwd事实层供后续dws层使用;还不需要翻译;
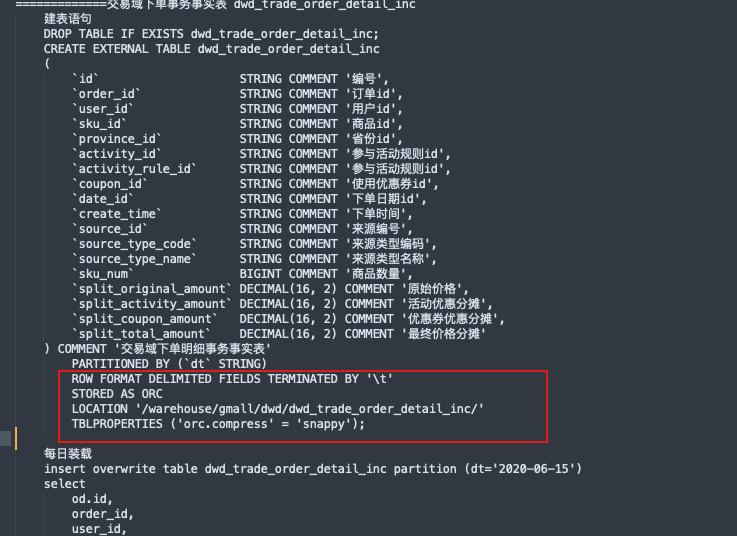
经过聚合dwd和dim的组合得到dws汇总层;
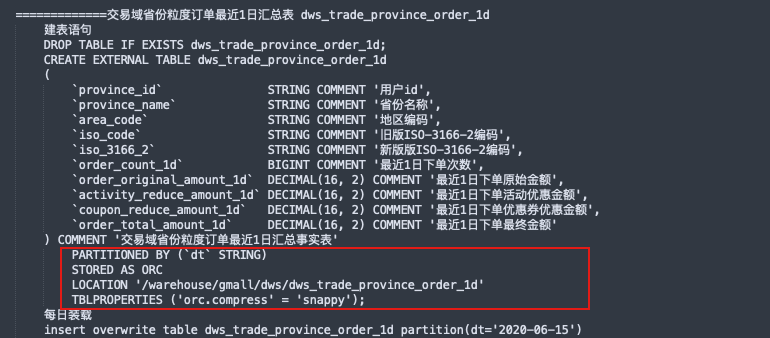
最后根据需求从dws层拿到对应的汇总记录再做一些个性化的统计如环比、同比等结果到ads层供应用层使用;
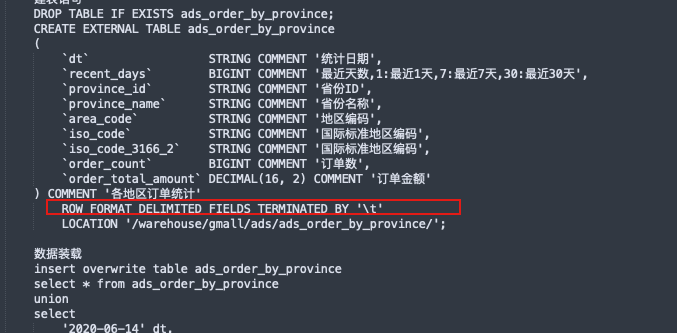
dim中的时间维度表、拉链表
离线数仓的首日数据装载
增量表通过maxwell首次同步时的type为bootstrap-insert
本文作者:大背头
本文链接:https://www.cnblogs.com/xuetieqi/p/17294950.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步